A computer program is said to learn from experience E with respect to some task T and some performance measure P, if its performance on T, as measured by P improves with experience E
ML Algorithms Overview
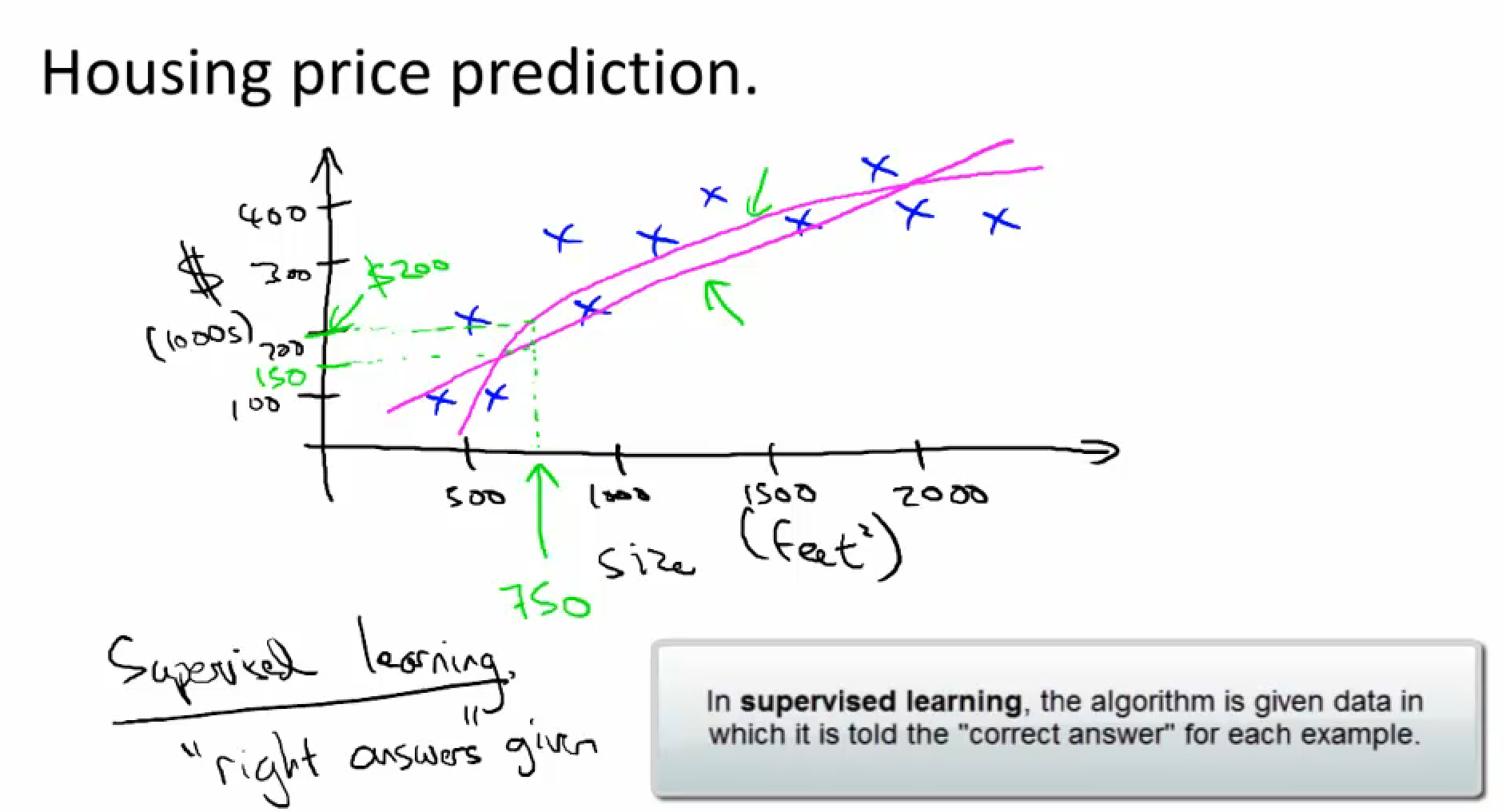
- Supervised learning <= "teach" program
- Given "right answers" data, then predict
- Regression: predict
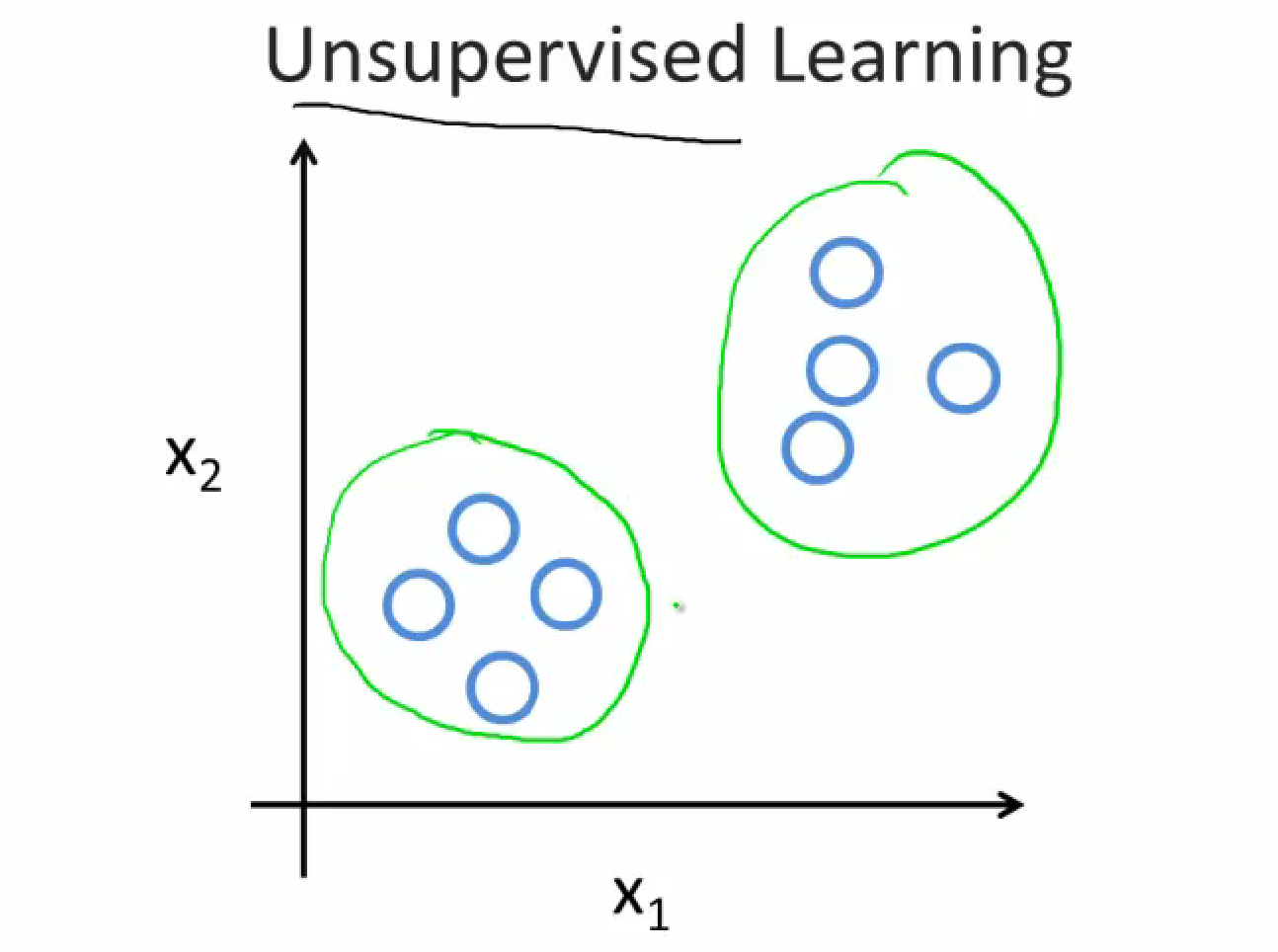
- Unsupervisedlearning <= let it learn by itself
- Given data without labels, then find some structures in the data
- Others: reinforcement learning, recommender systems
Regression Overivew
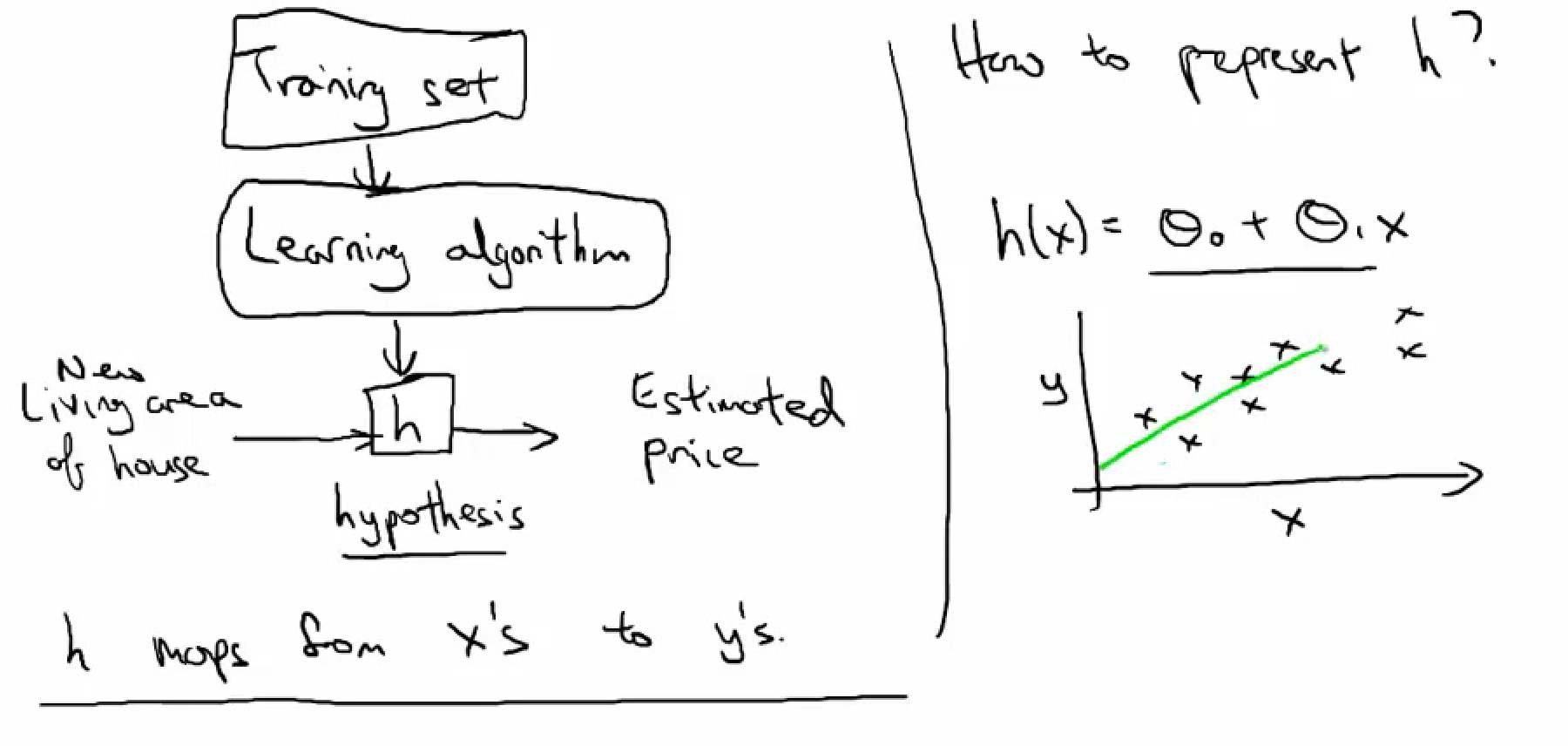
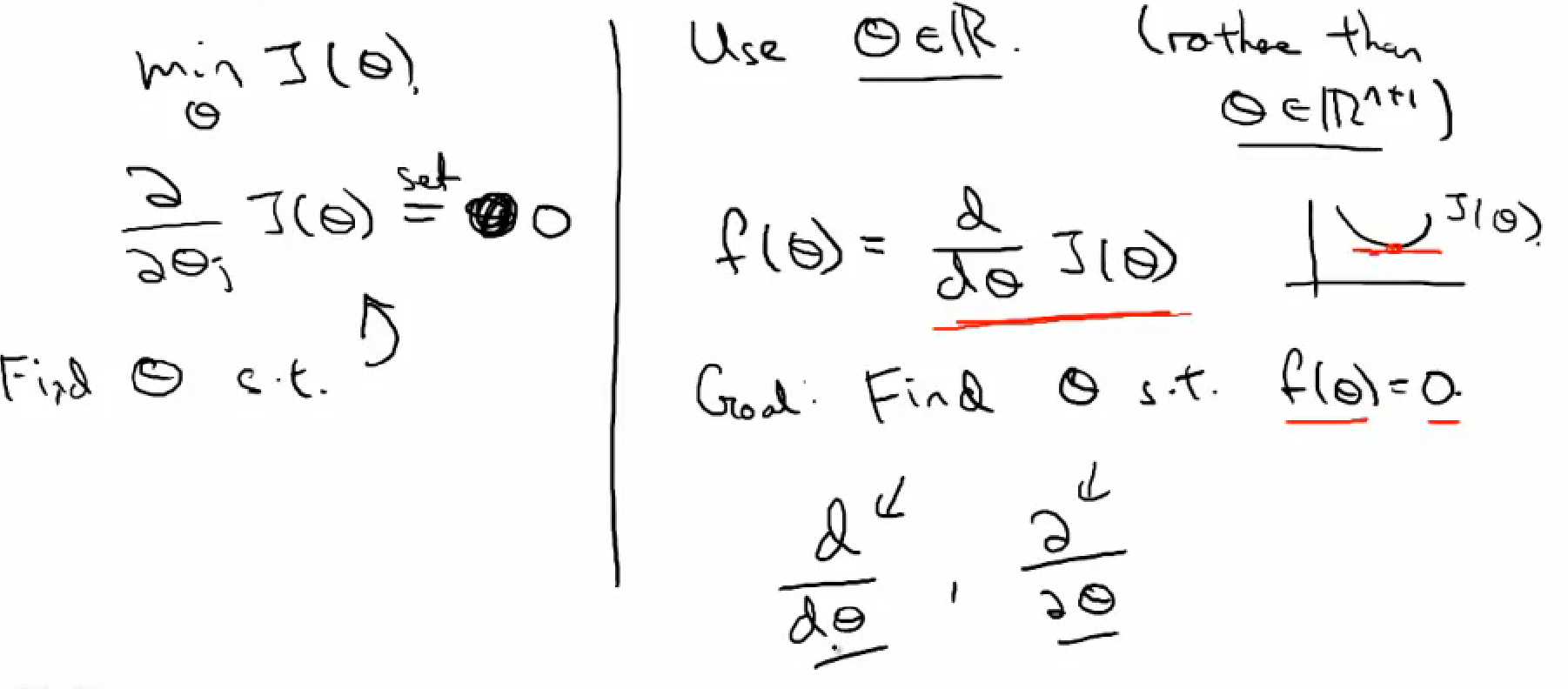
To get the prediction model, we need to define the hythontheis function, and determine the parameters
- Hythonthesis function & Cost Function
- Hypothesis function hΘ(x)
- Cost Function J(Θ)
- Gradient Descent

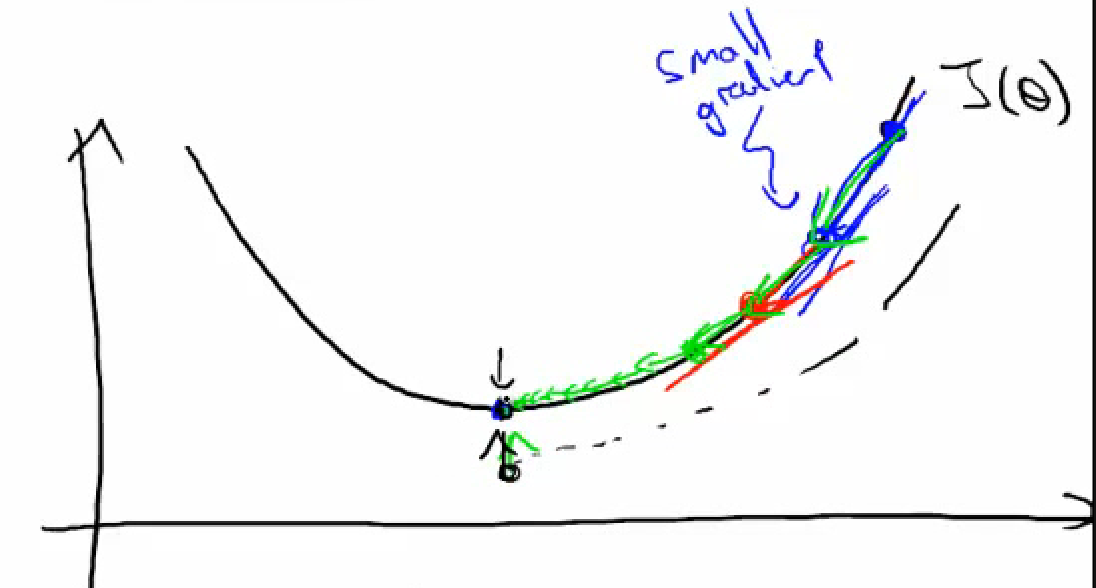

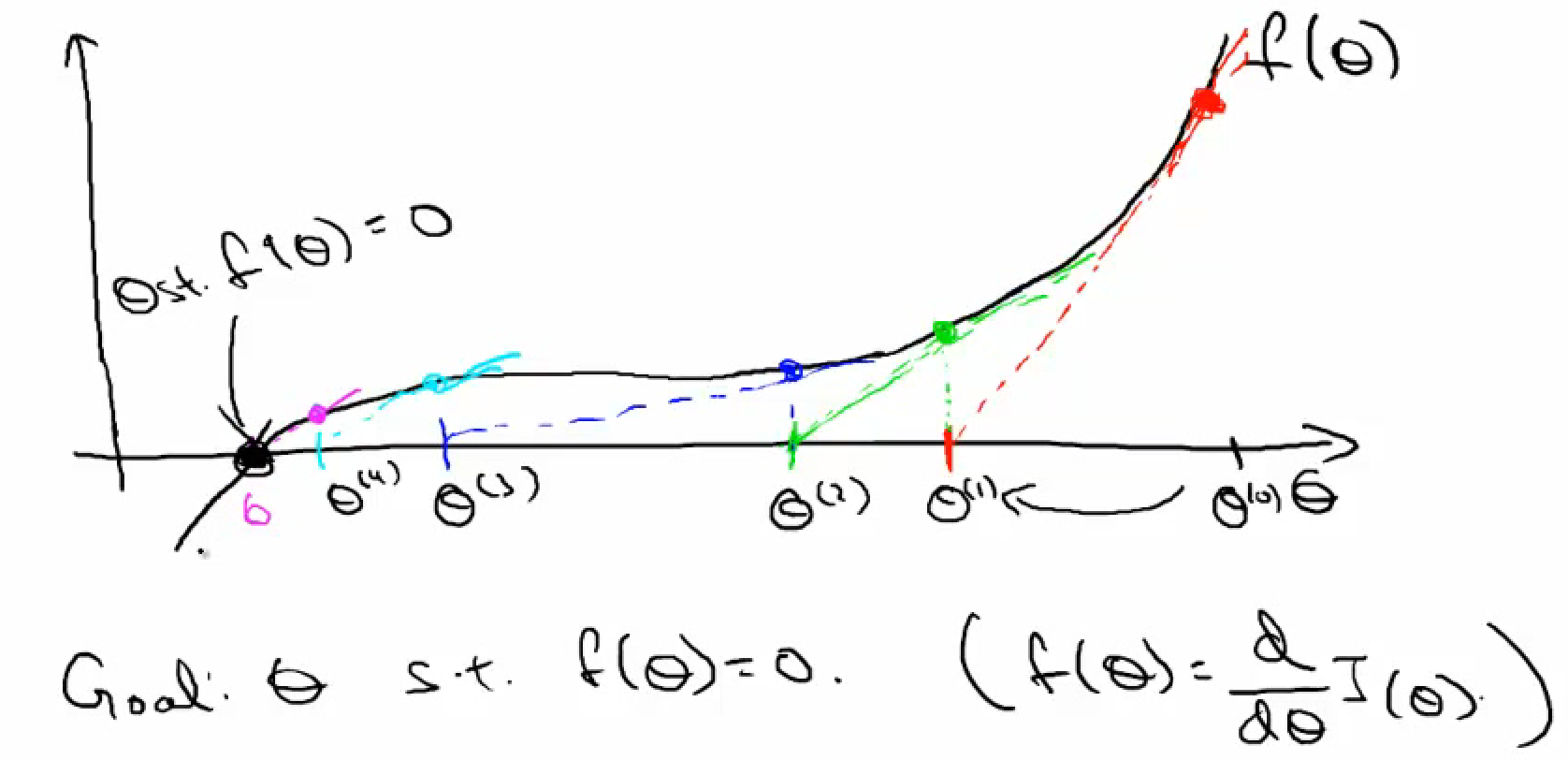
- Newton's method
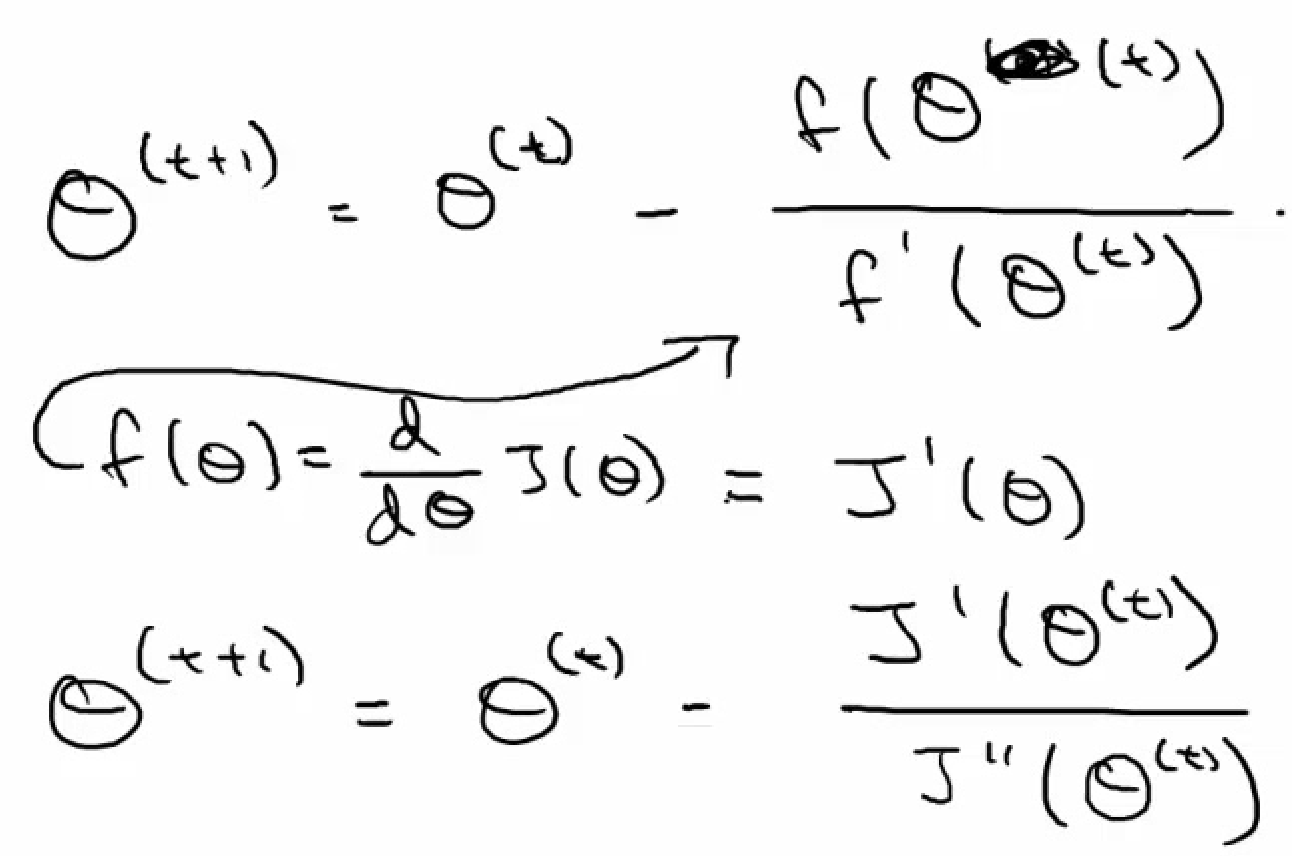
Linear Regression
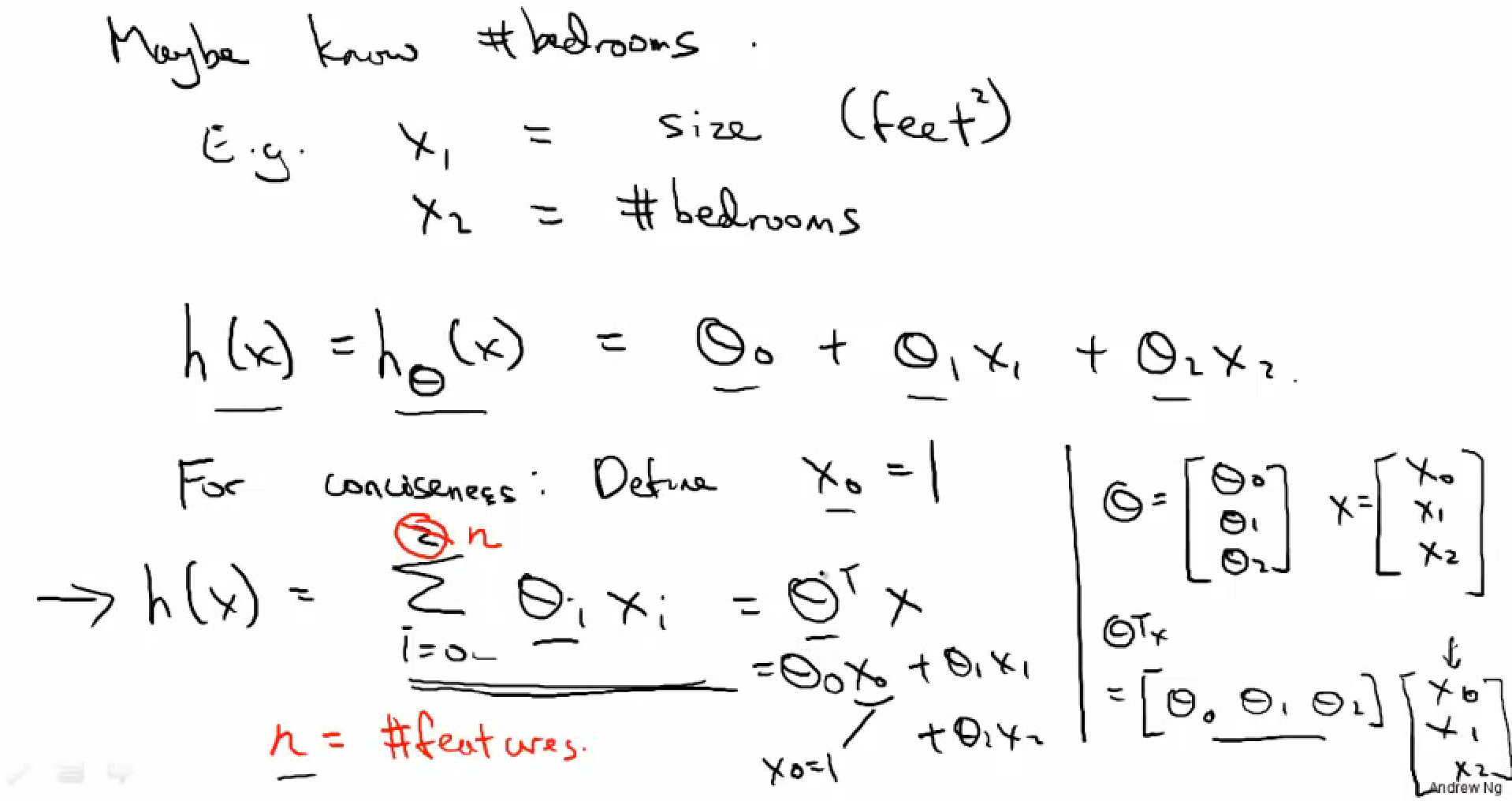
- Hypothesis function hΘ(x) = ΘTx
- Gradient descent for linear regression
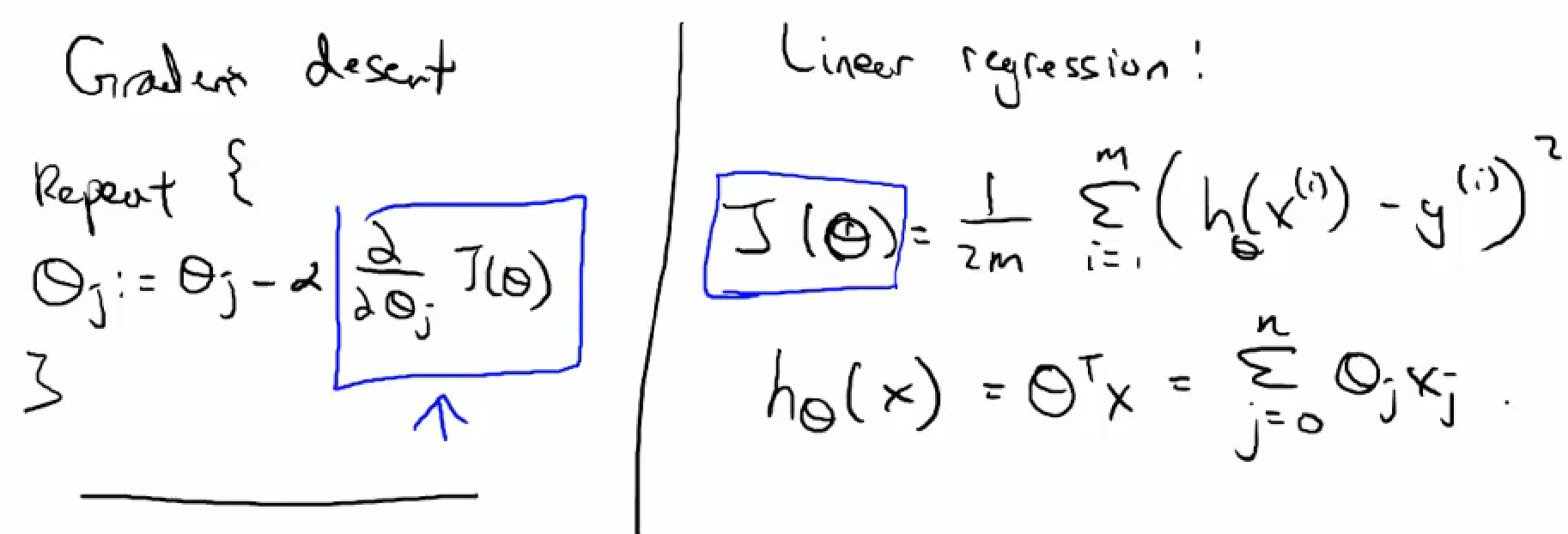
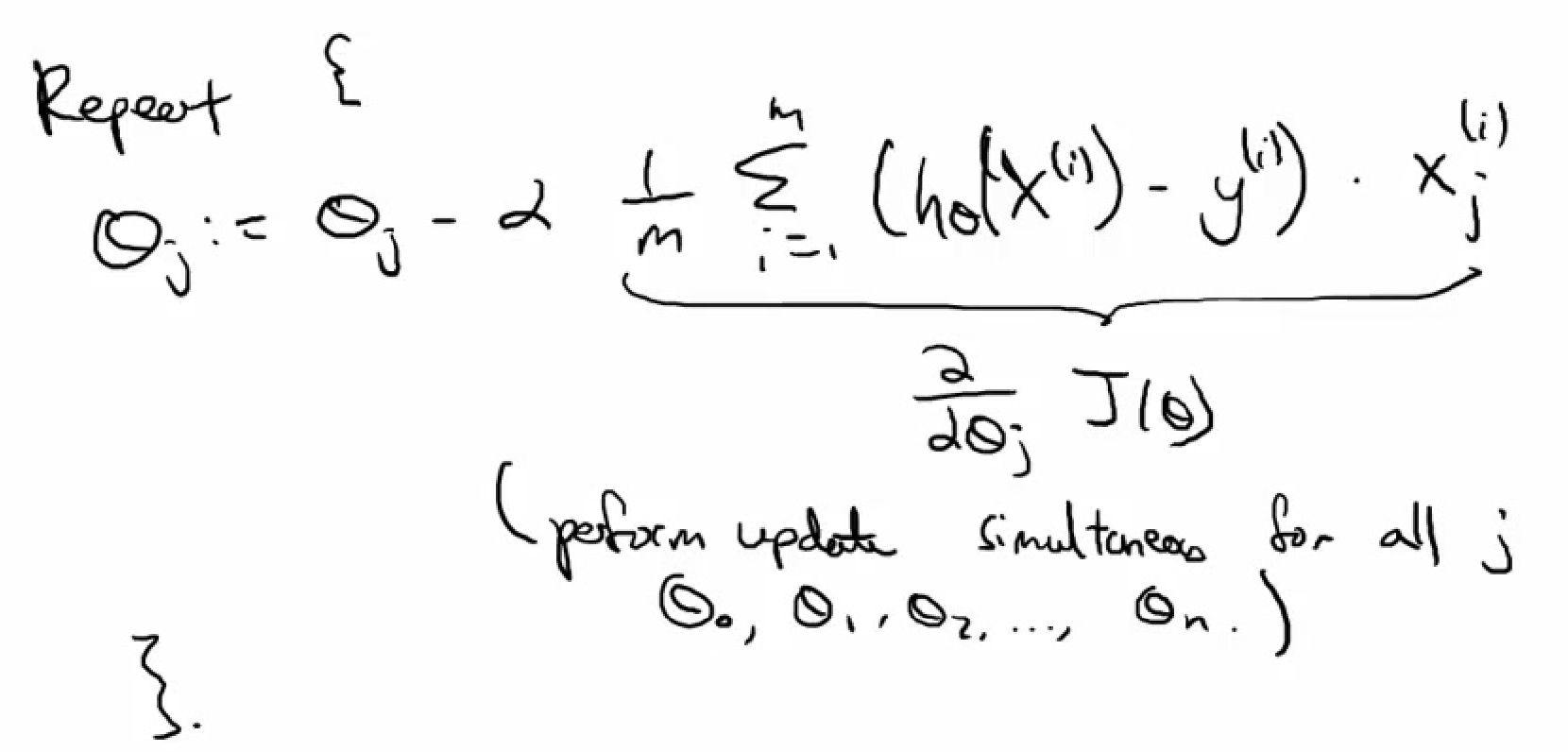
- Feature scaling
- make sure features are on similar scales
- Learning rate α
- pick the one seems to get J(Θ) to decrease fastest
- Features & Polynomial regession
- Normal Equation

- too many features
- regularization or delete some
- redundent features (e.g. linear dependent features)
- too many features
Logistic Regression
- Hypothesis function:
 [0,1]
[0,1] - Gradient descent & Newton's method for logisitic regression


Regularization*
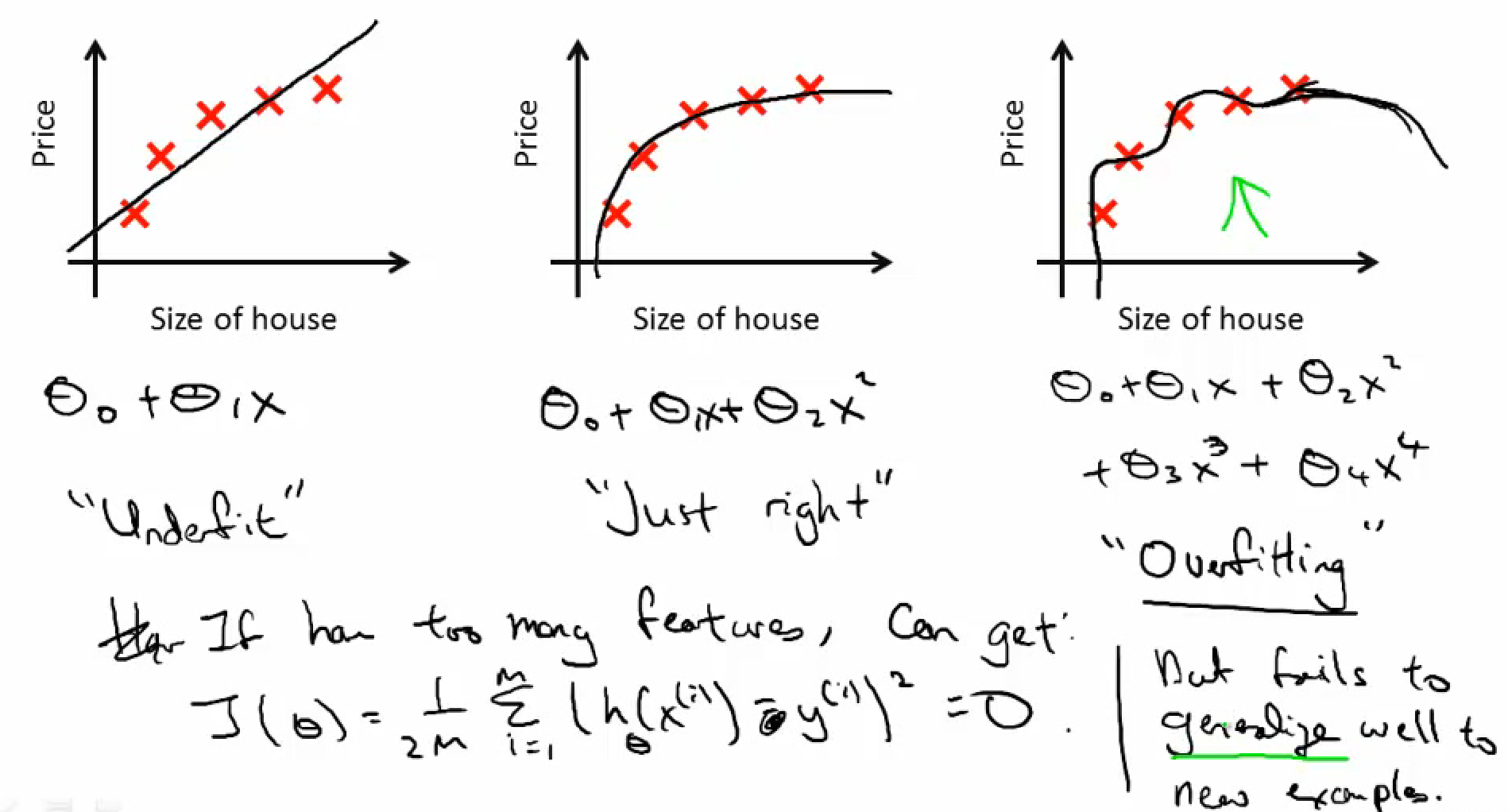
Regularizatio(正则化)意在eliminate overfitting(过拟合)问题。因为参数太多,会导致我们的模型复杂度上升,容易过拟合,也就是我们的训练误差会很小。但训练误差小并不是我们的最终目标,我们的目标是希望模型的测试误差小,也就是能准确的预测新的样本。所以,我们需要保证模型“简单”的基础上最小化训练误差,这样得到的参数才具有好的泛化性能(也就是测试误差也小),而模型“简单”就是通过规则函数来实现的。
简单来说,我们需要在训练误差小(目标1)和模型简单(目标2)之间tradeoff!
- 过拟合问题 (too many features)

- Regularized linear regression
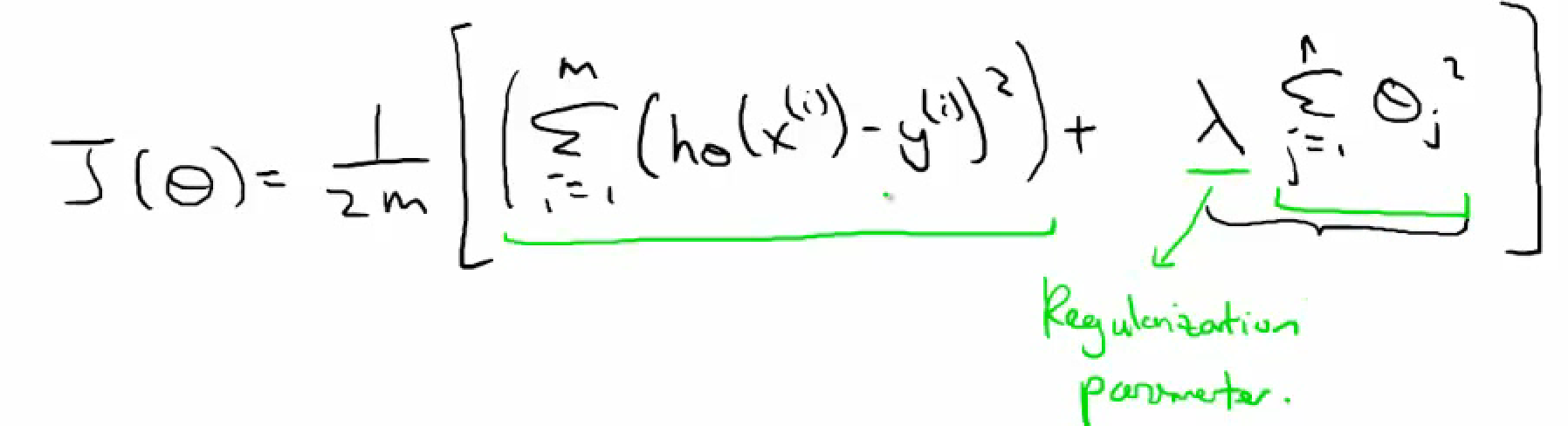
- Regularized logistic regression
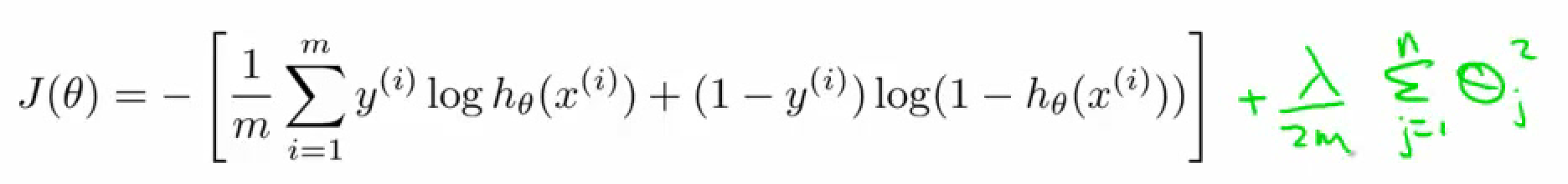
- regularization 惩罚项 & L2范数*
Reference
- http://www.52ml.net/12019.html
- http://blog.csdn.net/zouxy09/article/details/24971995/