分布式系统中服务端会通过心跳机制确认客户端是否存活,在 k8s 中,kubelet 也会定时上报心跳到 apiserver,以此判断该 node 是否存活,若 node 超过一定时间没有上报心跳,其状态会被置为 NotReady,宿主上容器的状态也会被置为 Nodelost 或者 Unknown 状态。kubelet 自身会定期更新状态到 apiserver,通过参数 --node-status-update-frequency 指定上报频率,默认是 10s 上报一次,kubelet 不止上报心跳信息还会上报自身的一些数据信息
一、kubelet 上报哪些状态
在 k8s 中,一个 node 的状态包含以下几个信息:
1、Addresses
主要包含以下几个字段:
- HostName:Hostname 。可以通过 kubelet 的
--hostname-override参数进行覆盖。 - ExternalIP:通常是可以外部路由的 node IP 地址(从集群外可访问)。
- InternalIP:通常是仅可在集群内部路由的 node IP 地址。
2、Condition
conditions 字段描述了所有 Running nodes 的状态。
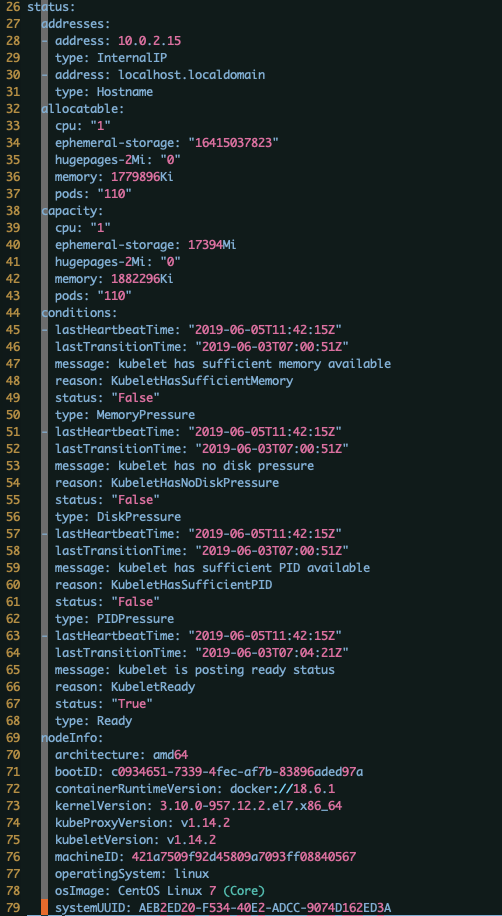
3、Capacity
描述 node 上的可用资源:CPU、内存和可以调度到该 node 上的最大 pod 数量。
4、Info
描述 node 的一些通用信息,例如内核版本、Kubernetes 版本(kubelet 和 kube-proxy 版本)、Docker 版本 (如果使用了)和系统版本,这些信息由 kubelet 从 node 上获取到。
二、kubelet 状态异常时的影响
如果一个 node 处于非 Ready 状态超过 pod-eviction-timeout的值(默认为 5 分钟,在 kube-controller-manager 中定义),在 v1.5 之前的版本中 kube-controller-manager 会 force delete pod 然后调度该宿主上的 pods 到其他宿主,在 v1.5 之后的版本中,kube-controller-manager 不会 force delete pod,pod 会一直处于Terminating 或Unknown 状态直到 node 被从 master 中删除或 kubelet 状态变为 Ready。在 node NotReady 期间,Daemonset 的 Pod 状态变为 Nodelost,Deployment、Statefulset 和 Static Pod 的状态先变为 NodeLost,然后马上变为 Unknown。Deployment 的 pod 会 recreate,Static Pod 和 Statefulset 的 Pod 会一直处于 Unknown 状态。
当 kubelet 变为 Ready 状态时,Daemonset的pod不会recreate,旧pod状态直接变为Running,Deployment的则是将kubelet进程停止的pod删除,Statefulset的Pod会重新recreate,Staic Pod 会被删除。
三、kubelet 状态上报的实现
kubelet 有两种上报状态的方式,第一种定期向 apiserver 发送心跳消息,简单理解就是启动一个 goroutine 然后定期向 APIServer 发送消息。
第二中被称为 NodeLease,在 v1.13 之前的版本中,节点的心跳只有 NodeStatus,从 v1.13 开始,NodeLease feature 作为 alpha 特性引入。当启用 NodeLease feature 时,每个节点在“kube-node-lease”名称空间中都有一个关联的“Lease”对象,该对象由节点定期更新,NodeStatus 和 NodeLease 都被视为来自节点的心跳。NodeLease 不会频繁更新,而只有在 NodeStatus 发生改变或者超过了一定时间(默认值为1分钟,node-monitor-grace-period 的默认值为 40s),才会将 NodeStatus 上报给 master。由于 NodeLease 比 NodeStatus 更轻量级,该特性在集群规模扩展性和性能上有明显提升。本文主要分析第一种上报方式的实现。
kubelet 上报状态的代码大部分在 kubernetes/pkg/kubelet/kubelet_node_status.go 中实现。状态上报的功能是在 kubernetes/pkg/kubelet/kubelet.go#Run 方法以 goroutine 形式中启动的,kubelet 中多个重要的功能都是在该方法中启动的。
kl.syncNodeStatus 便是上报状态的,此处 kl.nodeStatusUpdateFrequency 使用的是默认设置的 10s,也就是说节点间同步状态的函数 kl.syncNodeStatus 每 10s 执行一次。
syncNodeStatus 是状态上报的入口函数,其后所调用的多个函数也都是在同一个文件中实现的
syncNodeStatus 调用 updateNodeStatus, 然后又调用 tryUpdateNodeStatus 来进行上报操作,而最终调用的是 setNodeStatus。这里还进行了同步状态判断,如果是注册节点,则执行 registerWithAPIServer,否则,执行 updateNodeStatus。
updateNodeStatus 主要是调用 tryUpdateNodeStatus 进行后续的操作,该函数中定义了状态上报重试的次数,nodeStatusUpdateRetry 默认定义为 5 次。
syncNodeStatus 调用 updateNodeStatus, 然后又调用 tryUpdateNodeStatus 来进行上报操作,而最终调用的是 setNodeStatus。这里还进行了同步状态判断,如果是注册节点,则执行 registerWithAPIServer,否则,执行 updateNodeStatus
updateNodeStatus 主要是调用 tryUpdateNodeStatus 进行后续的操作,该函数中定义了状态上报重试的次数,nodeStatusUpdateRetry 默认定义为 5 次。
tryUpdateNodeStatus 是主要的上报逻辑,先给 node 设置状态,然后上报 node 的状态到 master。
tryUpdateNodeStatus 中调用 setNodeStatus 设置 node 的状态。setNodeStatus 会获取一次 node 的所有状态,然后会将 kubelet 中保存的所有状态改为最新的值,也就是会重置 node status 中的所有字段。
setNodeStatus 通过 setNodeStatusFuncs 方法覆盖 node 结构体中所有的字段,setNodeStatusFuncs 是在
NewMainKubelet(pkg/kubelet/kubelet.go) 中初始化的。
defaultNodeStatusFuncs 是生成状态的函数,通过获取 node 的所有状态指标后使用工厂函数生成状态
defaultNodeStatusFuncs 可以看到 node 上报的所有信息,主要有 MemoryPressureCondition、DiskPressureCondition、PIDPressureCondition、ReadyCondition 等。每一种 nodestatus 都返回一个 setters,所有 setters 的定义在 pkg/kubelet/nodestatus/setters.go 文件中。
对于二次开发而言,如果我们需要 APIServer 掌握更多的 Node 信息,可以在此处添加自定义函数,例如,上报磁盘信息等。
tryUpdateNodeStatus 中最后调用 PatchNodeStatus 上报 node 的状态到 master
在 PatchNodeStatus 会调用已注册的那些方法将状态把状态发给 APIServer。
四、总结
本文主要讲述了 kubelet 上报状态的方式及其实现,node 状态上报的方式目前有两种,本文仅分析了第一种状态上报的方式。在大规模集群中由于节点数量比较多,所有 node 都频繁报状态对 etcd 会有一定的压力,当 node 与 master 通信时由于网络导致心跳上报失败也会影响 node 的状态,为了避免类似问题的出现才有 NodeLease 方式,对于该功能的实现后文会继续进行分析。