核心组件运行机制
Kubernetes API Server原理解析
1. 总体来看,Kubernetes API Server的核心功能是提供Kubernetes各类 资源对象(如Pod、RC、Service等)的增、删、改、查及Watch等HTTP Rest接口,成为集群内各个功能模块之间数据交互和通信的中心枢纽, 是整个系统的数据总线和数据中心。除此之外,它还有以下一些功能特 性。(1)是集群管理的API入口。 (2)是资源配额控制的入口。 (3)提供了完备的集群安全机制。
2. API Server的性能是决定Kubernetes集群整体性能的关键因素,因此 Kubernetes的设计者综合运用以下方式来最大程度地保证API Server的性 能。(1)API Server拥有大量高性能的底层代码。在API Server源码中 使用协程(Coroutine)+队列(Queue)这种轻量级的高性能并发代码, 使得单进程的API Server具备了超强的多核处理能力,从而以很快的速 度并发处理大量的请求(2)普通List接口结合异步Watch接口,不但完美解决了 Kubernetes中各种资源对象的高性能同步问题,也极大提升了Kubernetes 集群实时响应各种事件的灵敏度。(3)采用了高性能的etcd数据库而非传统的关系数据库,不仅解决 了数据的可靠性问题,也极大提升了API Server数据访问层的性能。在 常见的公有云环境中,一个3节点的etcd集群在轻负载环境中处理一个请 求的时间可以低于1ms,在重负载环境中可以每秒处理超过30000个请 求。
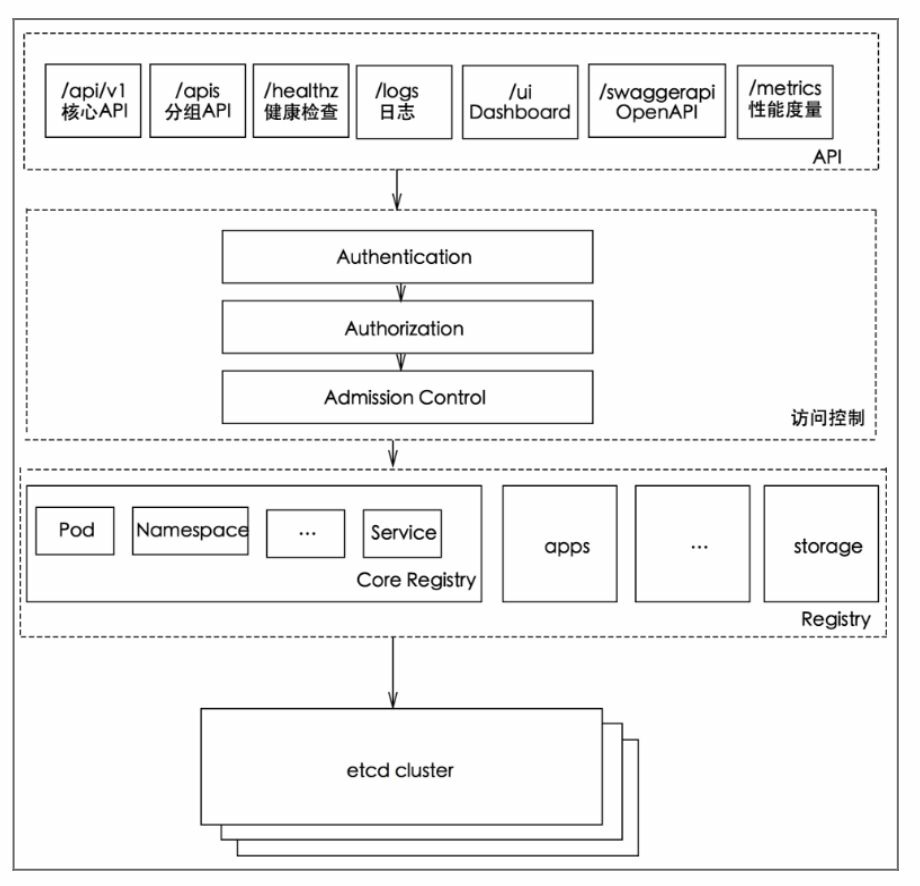
图5.3以一个完整的Pod调度过程为 例,对API Server的List-Watch机制进行说明
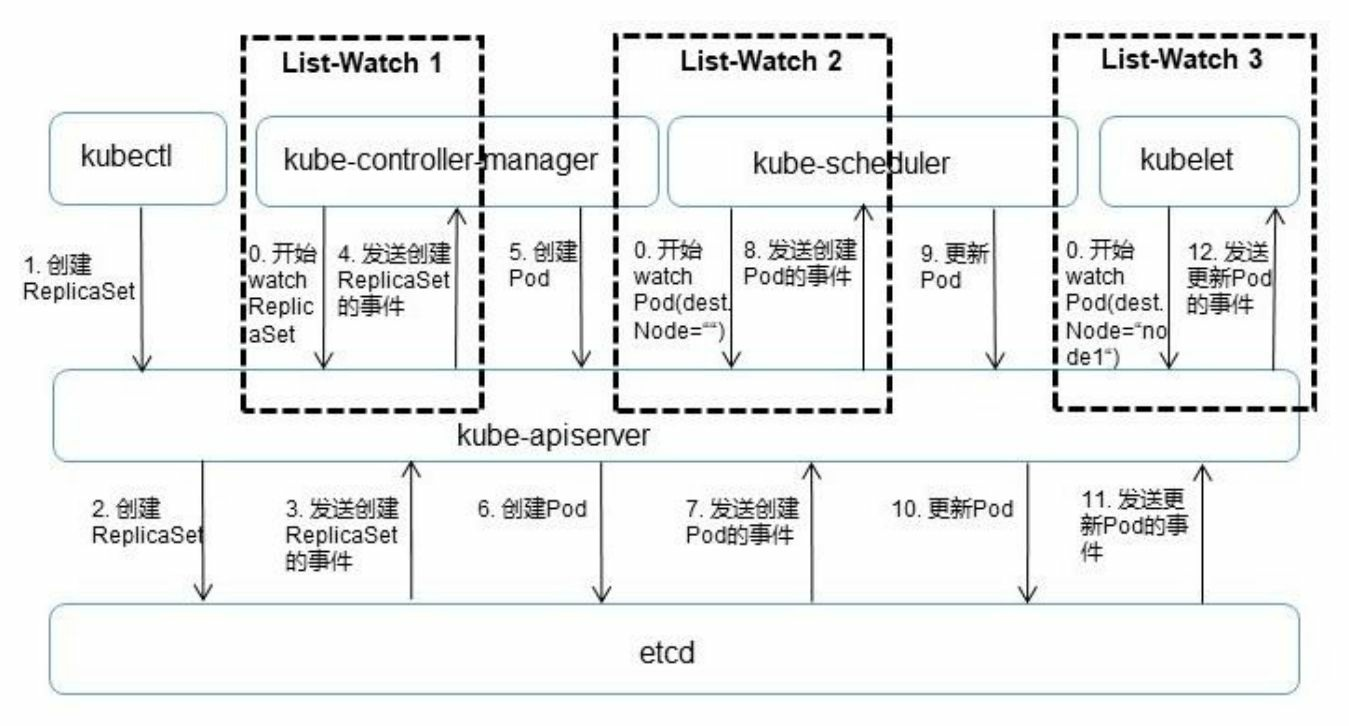
首先,借助etcd提供的Watch API接口,API Server可以监听 (Watch)在etcd上发生的数据操作事件,比如Pod创建事件、更新事 件、删除事件等,在这些事件发生后,etcd会及时通知API Server。图 5.3中API Server与etcd之间的交互箭头表明了这个过程:当一个 ReplicaSet对象被创建并被保存到etcd中后(图中的2.Create RepliatSet箭 头),etcd会立即发送一个对应的Create事件给API Server(图中的 3.Send RepliatSet Create Event箭头),与其类似的6、7、10、11箭头都 是针对Pod的创建、更新事件的。然后,为了让Kubernetes中的其他组件在不访问底层etcd数据库的 情况下,也能及时获取资源对象的变化事件,API Server模仿etcd的 Watch API接口提供了自己的Watch接口,这样一来,这些组件就能近乎 实时地获取它们感兴趣的任意资源对象的相关事件通知了。图5.3中 controller-manager、scheduler、kublet等组件与API Server之间的3个标记 有List-Watch的虚框表明了这个过程。同时,在监听自己感兴趣的资源 的时候,客户端可以增加过滤条件,以List-Watch 3为例,node1节点上 的kubelet进程只对自己节点上的Pod事件感兴趣。最后,Kubernetes List-Watch用于实现数据同步的代码逻辑。客户 端首先调用API Server的List接口获取相关资源对象的全量数据并将其缓 存到内存中,然后启动对应资源对象的Watch协程,在接收到Watch事 件后,再根据事件的类型(比如新增、修改或删除)对内存中的全量资 源对象列表做出相应的同步修改,从实现上来看,这是一种全量结合增 量的、高性能的、近乎实时的数据同步方式。
3. 从图5.6中可以看出,Kubernetes API Server作为集群的核心,负责 集群各功能模块之间的通信。集群内的各个功能模块通过API Server将 信息存入etcd,当需要获取和操作这些数据时,则通过API Server提供的 REST接口(用GET、LIST或WATCH方法)来实现,从而实现各模块之 间的信息交互。

常见的一个交互场景是kubelet进程与API Server的交互。每个Node 上的kubelet每隔一个时间周期,就会调用一次API Server的REST接口报 告自身状态,API Server在接收到这些信息后,会将节点状态信息更新 到etcd中。此外,kubelet也通过API Server的Watch接口监听Pod信息, 如果监听到新的Pod副本被调度绑定到本节点,则执行Pod对应的容器创 建和启动逻辑;如果监听到Pod对象被删除,则删除本节点上相应的Pod 容器;如果监听到修改Pod的信息,kubelet就会相应地修改本节点的Pod 容器。
另一个交互场景是kube-controller-manager进程与API Server的交互。kube-controller-manager中的Node Controller模块通过API Server提供 的Watch接口实时监控Node的信息,并做相应处理
还有一个比较重要的交互场景是kube-scheduler与API Server的交 互。Scheduler通过API Server的Watch接口监听到新建Pod副本的信息 后,会检索所有符合该Pod要求的Node列表,开始执行Pod调度逻辑, 在调度成功后将Pod绑定到目标节点上。
为了缓解集群各模块对API Server的访问压力,各功能模块都采用 缓存机制来缓存数据。各功能模块定时从API Server获取指定的资源对 象信息(通过List-Watch方法),然后将这些信息保存到本地缓存中, 功能模块在某些情况下不直接访问API Server,而是通过访问缓存数据 来间接访问API Server。
Controller Manager原理解析
1. 一般来说,智能系统和自动系统通常会通过一个“操作系统”来不断修正系统的工作状态。在Kubernetes集群中,每个Controller都是这样的 一个“操作系统”,它们通过API Server提供的(List-Watch)接口实时监控集群中特定资源的状态变化,当发生各种故障导致某资源对象的状态发生变化时,Controller会尝试将其状态调整为期望的状态。比如当某个 Node意外宕机时,Node Controller会及时发现此故障并执行自动化修复流程,确保集群始终处于预期的工作状态。Controller Manager是 Kubernetes中各种操作系统的管理者,是集群内部的管理控制中心,也 是Kubernetes自动化功能的核心。
2. Controller Manager内部包含Replication Controller、 Node Controller、ResourceQuota Controller、Namespace Controller、 ServiceAccount Controller、Token Controller、Service Controller及 Endpoint Controller这8种Controller,每种Controller都负责一种特定资源 的控制流程,而Controller Manager正是这些Controller的核心管理者


(1)Controller Manager在启动时如果设置了--cluster-cidr参数,那 么为每个没有设置Spec.PodCIDR的Node都生成一个CIDR地址,并用该 CIDR地址设置节点的Spec.PodCIDR属性,这样做的目的是防止不同节 点的CIDR地址发生冲突。
(2)逐个读取Node信息,多次尝试修改nodeStatusMap中的节点状 态信息,将该节点信息和Node Controller的nodeStatusMap中保存的节点 信息做比较。如果判断出没有收到kubelet发送的节点信息、第1次收到 节点kubelet发送的节点信息,或在该处理过程中节点状态变成非“健康”状态,则在nodeStatusMap中保存该节点的状态信息,并用Node Controller所在节点的系统时间作为探测时间和节点状态变化时间。如果 判断出在指定时间内收到新的节点信息,且节点状态发生变化,则在 nodeStatusMap中保存该节点的状态信息,并用Node Controller所在节点 的系统时间作为探测时间和节点状态变化时间。如果判断出在指定时间 内收到新的节点信息,但节点状态没发生变化,则在nodeStatusMap中 保存该节点的状态信息,并用Node Controller所在节点的系统时间作为 探测时间,将上次节点信息中的节点状态变化时间作为该节点的状态变 化时间。如果判断出在某段时间(gracePeriod)内没有收到节点状态信 息,则设置节点状态为“未知”,并且通过API Server保存节点状态。
(3)逐个读取节点信息,如果节点状态变为非“就绪”状态,则将 节点加入待删除队列,否则将节点从该队列中删除。如果节点状态为 非“就绪”状态,且系统指定了Cloud Provider,则Node Controller调用 Cloud Provider查看节点,若发现节点故障,则删除etcd中的节点信息, 并删除和该节点相关的Pod等资源的信息。
ResourceQuota Controller
目前Kubernetes支持如下三个层次的资源配额管理
(1)容器级别,可以对CPU和Memory进行限制。(2)Pod级别,可以对一个Pod内所有容器的可用资源进行限制。(3)Namespace级别,为Namespace(多租户)级别的资源限制, 包括:◎ Pod数量; ◎ Replication Controller数量; ◎ Service数量; ◎ ResourceQuota数量; ◎ Secret数量; ◎ 可持有的PV数量。
Kubernetes的配额管理是通过Admission Control(准入控制)来控制 的,Admission Control当前提供了两种方式的配额约束,分别是 LimitRanger与ResourceQuota。其中LimitRanger作用于Pod和Container, ResourceQuota则作用于Namespace,限定一个Namespace里的各类资源 的使用总额。
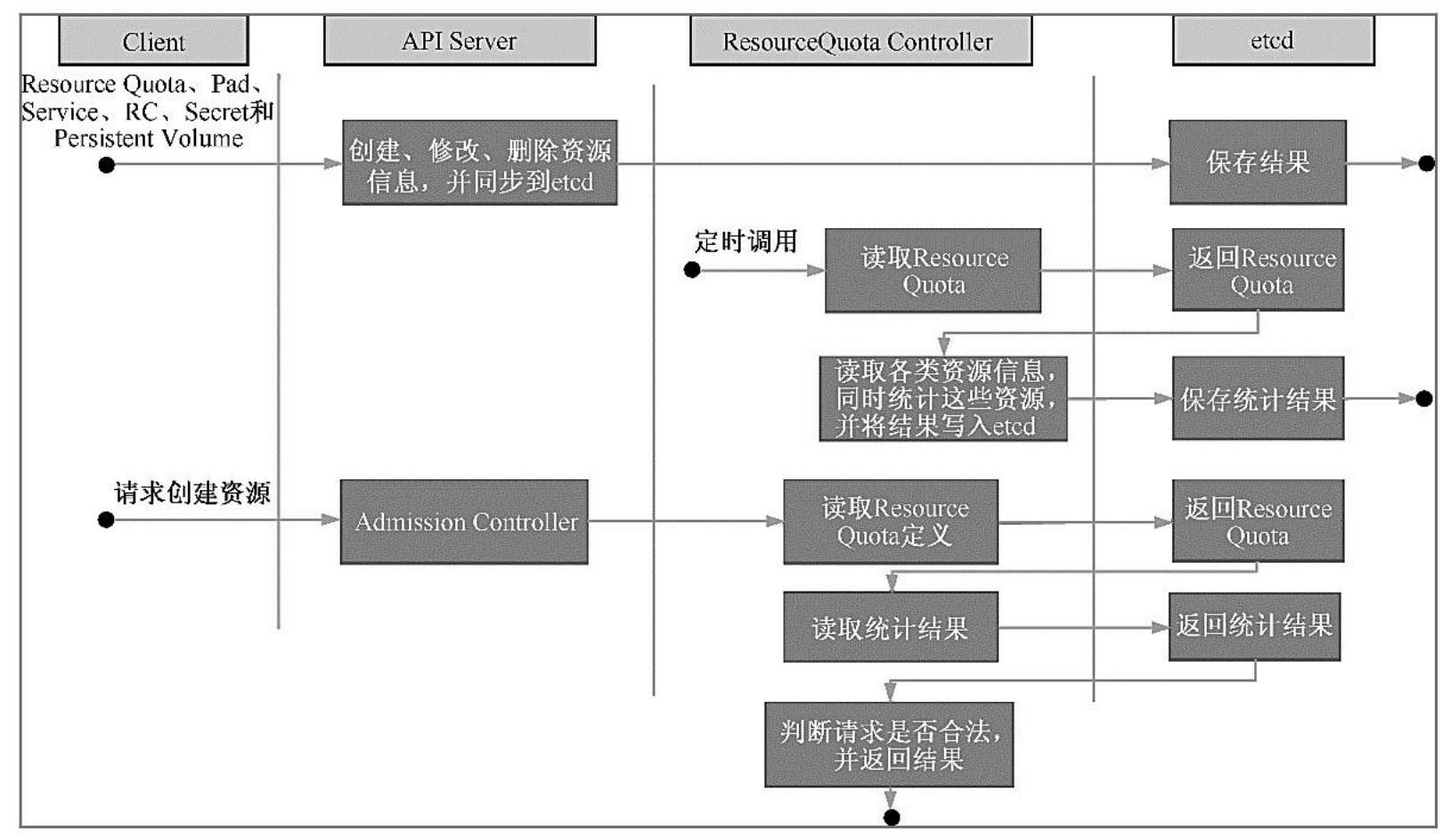
如图5.9所示,如果在Pod定义中同时声明了LimitRanger,则用户通 过API Server请求创建或修改资源时,Admission Control会计算当前配额 的使用情况,如果不符合配额约束,则创建对象失败。对于定义了 ResourceQuota的Namespace,ResourceQuota Controller组件则负责定期 统计和生成该Namespace下的各类对象的资源使用总量,统计结果包括 Pod、Service、RC、Secret和Persistent Volume等对象实例个数,以及该 Namespace下所有Container实例所使用的资源量(目前包括CPU和内 存),然后将这些统计结果写入etcd的resourceQuotaStatusStorage目录 (resourceQuotas/status)下。写入resourceQuotaStatusStorage的内容包含 Resource名称、配额值(ResourceQuota对象中spec.hard域下包含的资源 的值)、当前使用值(ResourceQuota Controller统计出来的值)。随后 这些统计信息被Admission Control使用,以确保相关Namespace下的资 源配额总量不会超过ResourceQuota中的限定值。
Namespace Controller
用户通过API Server可以创建新的Namespace并将其保存在etcd中, Namespace Controller定时通过API Server读取这些Namespace的信息。如 果Namespace被API标识为优雅删除(通过设置删除期限实现,即设置 DeletionTimestamp属性),则将该NameSpace的状态设置成Terminating 并保存到etcd中。同时Namespace Controller删除该Namespace下的 ServiceAccount、RC、Pod、Secret、PersistentVolume、ListRange、 ResourceQuota和Event等资源对象。
在Namespace的状态被设置成Terminating后,由Admission Controller的NamespaceLifecycle插件来阻止为该Namespace创建新的资 源。同时,在Namespace Controller删除该Namespace中的所有资源对象 后,Namespace Controller对该Namespace执行finalize操作,删除Namespace的spec.finalizers域中的信
如果Namespace Controller观察到Namespace设置了删除期限,同时 Namespace的spec.finalizers域值是空的,那么Namespace Controller将通 过API Server删除该Namespace资源。
Service Controller与Endpoints Controller
本节讲解Endpoints Controller,在这之前,让我们先看看Service、 Endpoints与Pod的关系。如图5.10所示,Endpoints表示一个Service对应 的所有Pod副本的访问地址,Endpoints Controller就是负责生成和维护所 有Endpoints对象的控制器。
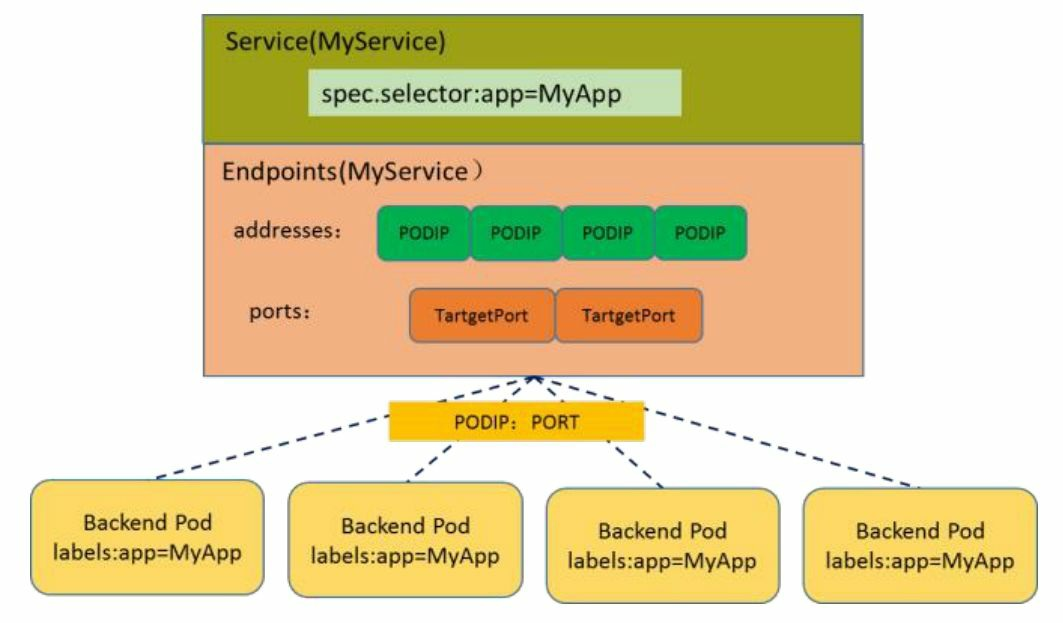
它负责监听Service和对应的Pod副本的变化,如果监测到Service被 删除,则删除和该Service同名的Endpoints对象。如果监测到新的Service 被创建或者修改,则根据该Service信息获得相关的Pod列表,然后创建 或者更新Service对应的Endpoints对象。如果监测到Pod的事件,则更新 它所对应的Service的Endpoints对象(增加、删除或者修改对应的 Endpoint条目)。
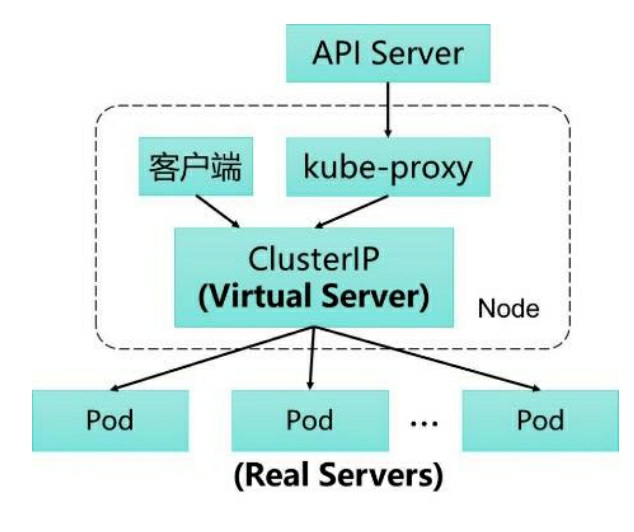
那么,Endpoints对象是在哪里被使用的呢?答案是每个Node上的 kube-proxy进程,kube-proxy进程获取每个Service的Endpoints,实现了 Service的负载均衡功能。

Kubernetes Scheduler当前提供的默认调度流程分为以下两步。
(1)预选调度过程,即遍历所有目标Node,筛选出符合要求的候 选节点。为此,Kubernetes内置了多种预选策略(xxx Predicates)供用 户选择
(2)确定最优节点,在第1步的基础上,采用优选策略(xxx Priority)计算出每个候选节点的积分,积分最高者胜出。
Kubernetes Scheduler的调度流程是通过插件方式加载的“调度算法 提供者”(AlgorithmProvider)具体实现的。一个AlgorithmProvider其实 就是包括了一组预选策略与一组优先选择策略的结构体
Scheduler中可用的预选策略包含:NoDiskConflict、 PodFitsResources、PodSelectorMatches、PodFitsHost、 CheckNodeLabelPresence、CheckServiceAffinity和PodFitsPorts策略等。 其默认的AlgorithmProvider加载的预选策略Predicates包括: PodFitsPorts(PodFitsPorts)、PodFitsResources(PodFitsResources)、 NoDiskConflict(NoDiskConflict)、 MatchNodeSelector(PodSelectorMatches)和 HostName(PodFitsHost),即每个节点只有通过前面提及的5个默认预 选策略后,才能初步被选中,进入下一个流程
1)NoDiskConflict 判断备选Pod的gcePersistentDisk或AWSElasticBlockStore和备选的节 点中已存在的Pod是否存在冲突。检测过程如下。
(1)首先,读取备选Pod的所有Volume的信息(即 pod.Spec.Volumes),对每个Volume执行以下步骤进行冲突检测。
(2)如果该Volume是gcePersistentDisk,则将Volume和备选节点上 的所有Pod的每个Volume都进行比较,如果发现相同的 gcePersistentDisk,则返回false,表明存在磁盘冲突,检查结束,反馈给 调度器该备选节点不适合作为备选Pod;如果该Volume是 AWSElasticBlockStore,则将Volume和备选节点上的所有Pod的每个 Volume都进行比较,如果发现相同的AWSElasticBlockStore,则返回 false,表明存在磁盘冲突,检查结束,反馈给调度器该备选节点不适合 备选Pod。
(3)如果检查完备选Pod的所有Volume均未发现冲突,则返回true,表明不存在磁盘冲突,反馈给调度器该备选节点适合备选Pod。
2)PodFitsResources 判断备选节点的资源是否满足备选Pod的需求,检测过程如下。
(1)计算备选Pod和节点中已存在Pod的所有容器的需求资源(内 存和CPU)的总和。
(2)获得备选节点的状态信息,其中包含节点的资源信息。
(3)如果在备选Pod和节点中已存在Pod的所有容器的需求资源 (内存和CPU)的总和,超出了备选节点拥有的资源,则返回false,表 明备选节点不适合备选Pod,否则返回true,表明备选节点适合备选 Pod。
3)PodSelectorMatches 判断备选节点是否包含备选Pod的标签选择器指定的标签。
(1)如果Pod没有指定spec.nodeSelector标签选择器,则返回true。
(2)否则,获得备选节点的标签信息,判断节点是否包含备选Pod 的标签选择器(spec.nodeSelector)所指定的标签,如果包含,则返回 true,否则返回false。
4)PodFitsHost 判断备选Pod的spec.nodeName域所指定的节点名称和备选节点的名 称是否一致,如果一致,则返回true,否则返回false。
5)CheckNodeLabelPresence 如果用户在配置文件中指定了该策略,则Scheduler会通过 RegisterCustomFitPredicate方法注册该策略。该策略用于判断策略列出 的标签在备选节点中存在时,是否选择该备选节点。
(1)读取备选节点的标签列表信息
(2)如果策略配置的标签列表存在于备选节点的标签列表中,且 策略配置的presence值为false,则返回false,否则返回true;如果策略配 置的标签列表不存在于备选节点的标签列表中,且策略配置的presence 值为true,则返回false,否则返回true。
6)CheckServiceAffinity 如果用户在配置文件中指定了该策略,则Scheduler会通过 RegisterCustomFitPredicate方法注册该策略。该策略用于判断备选节点 是否包含策略指定的标签,或包含和备选Pod在相同Service和Namespace 下的Pod所在节点的标签列表。如果存在,则返回true,否则返回false。
7)PodFitsPorts 判断备选Pod所用的端口列表中的端口是否在备选节点中已被占 用,如果被占用,则返回false,否则返回true。
1)LeastRequestedPriority 该优选策略用于从备选节点列表中选出资源消耗最小的节点。
(1)计算出在所有备选节点上运行的Pod和备选Pod的CPU占用量 totalMilliCPU。
(2)计算出在所有备选节点上运行的Pod和备选Pod的内存占用量 totalMemory。
(3)计算每个节点的得分,计算规则大致如下,其中, NodeCpuCapacity为节点CPU计算能力,NodeMemoryCapacity为节点内存大小:

2)CalculateNodeLabelPriority 如果用户在配置文件中指定了该策略,则scheduler会通过 RegisterCustomPriorityFunction方法注册该策略。该策略用于判断策略列 出的标签在备选节点中存在时,是否选择该备选节点。如果备选节点的 标签在优选策略的标签列表中且优选策略的presence值为true,或者备选 节点的标签不在优选策略的标签列表中且优选策略的presence值为 false,则备选节点score=10,否则备选节点score=0。
3)BalancedResourceAllocation 该优选策略用于从备选节点列表中选出各项资源使用率最均衡的节 点。
(1)计算出在所有备选节点上运行的Pod和备选Pod的CPU占用量 totalMilliCPU。
(2)计算出在所有备选节点上运行的Pod和备选Pod的内存占用量 totalMemory。
(3)计算每个节点的得分,计算规则大致如下,其中, NodeCpuCapacity为节点的CPU计算能力,NodeMemoryCapacity为节点 的内存大小:

在Kubernetes集群中,在每个Node(又称Minion)上都会启动一个 kubelet服务进程。该进程用于处理Master下发到本节点的任务,管理 Pod及Pod中的容器。每个kubelet进程都会在API Server上注册节点自身 的信息,定期向Master汇报节点资源的使用情况,并通过cAdvisor监控 容器和节点资源。
kubelet通过以下几种方式获取自身Node上要运行的Pod清单
(1)文件:kubelet启动参数“--config”指定的配置文件目录下的文 件(默认目录为“/etc/ kubernetes/manifests/”)。通过--file-check- frequency设置检查该文件目录的时间间隔,默认为20s。
(2)HTTP端点(URL):通过“--manifest-url”参数设置。通过-- http-check-frequency设置检查该HTTP端点数据的时间间隔,默认为 20s。
(3)API Server:kubelet通过API Server监听etcd目录,同步Pod列 表
所有以非API Server方式创建的Pod都叫作Static Pod。kubelet将 Static Pod的状态汇报给API Server,API Server为该Static Pod创建一个 Mirror Pod和其相匹配。Mirror Pod的状态将真实反映Static Pod的状态。 当Static Pod被删除时,与之相对应的Mirror Pod也会被删除。
kubelet监听etcd,所有针对Pod的操作都会被kubelet监听。如果发现 有新的绑定到本节点的Pod,则按照Pod清单的要求创建该Pod。
如果发现本地的Pod被修改,则kubelet会做出相应的修改,比如在 删除Pod中的某个容器时,会通过Docker Client删除该容器。
如果发现删除本节点的Pod,则删除相应的Pod,并通过Docker Client删除Pod中的容器。
kubelet读取监听到的信息,如果是创建和修改Pod任务,则做如下 处理。
(1)为该Pod创建一个数据目录。
(2)从API Server读取该Pod清单。
(3)为该Pod挂载外部卷(External Volume)。
(4)下载Pod用到的Secret。
(5)检查已经运行在节点上的Pod,如果该Pod没有容器或Pause容 器(“kubernetes/pause”镜像创建的容器)没有启动,则先停止Pod里所 有容器的进程。如果在Pod中有需要删除的容器,则删除这些容器。
(6)用“kubernetes/pause”镜像为每个Pod都创建一个容器。该Pause 容器用于接管Pod中所有其他容器的网络。每创建一个新的Pod,kubelet 都会先创建一个Pause容器,然后创建其他容器。“kubernetes/pause”镜像 大概有200KB,是个非常小的容器镜像。
(7)为Pod中的每个容器做如下处理。
◎ 为容器计算一个Hash值,然后用容器的名称去查询对应Docker 容器的Hash值。若查找到容器,且二者的Hash值不同,则停止Docker中 容器的进程,并停止与之关联的Pause容器的进程;若二者相同,则不做任何处理。
◎ 如果容器被终止了,且容器没有指定的restartPolicy(重启策 略),则不做任何处理。
◎ 调用Docker Client下载容器镜像,调用Docker Client运行容器
容器健康检查
Pod通过两类探针来检查容器的健康状态。一类是LivenessProbe探 针,用于判断容器是否健康并反馈给kubelet。如果LivenessProbe探针探 测到容器不健康,则kubelet将删除该容器,并根据容器的重启策略做相 应的处理。如果一个容器不包含LivenessProbe探针,那么kubelet认为该 容器的LivenessProbe探针返回的值永远是Success;另一类是 ReadinessProbe探针,用于判断容器是否启动完成,且准备接收请求。 如果ReadinessProbe探针检测到容器启动失败,则Pod的状态将被修改, Endpoint Controller将从Service的Endpoint中删除包含该容器所在Pod的IP 地址的Endpoint条目

Kubernetes从1.2版本开始,将iptables作为kube- proxy的默认模式。iptables模式下的kube-proxy不再起到Proxy的作用, 其核心功能:通过API Server的Watch接口实时跟踪Service与Endpoint的 变更信息,并更新对应的iptables规则,Client的请求流量则通过iptables 的NAT机制“直接路由”到目标Pod。

根据Kubernetes的网络模型,一个Node上的Pod与其他Node上的Pod 应该能够直接建立双向的TCP/IP通信通道,所以如果直接修改iptables规 则,则也可以实现kube-proxy的功能,只不过后者更加高端,因为是全 自动模式的。与第1代的userspace模式相比,iptables模式完全工作在内 核态,不用再经过用户态的kube-proxy中转,因而性能更强
iptables与IPVS虽然都是基于Netfilter实现的,但因为定位不同,二 者有着本质的差别:iptables是为防火墙而设计的;IPVS则专门用于高 性能负载均衡,并使用更高效的数据结构(Hash表),允许几乎无限的 规模扩张,因此被kube-proxy采纳为第三代模式
与iptables相比,IPVS拥有以下明显优势:
◎ 为大型集群提供了更好的可扩展性和性能
◎ 支持比iptables更复杂的复制均衡算法(最小负载、最少连接、 加权等);
◎ 支持服务器健康检查和连接重试等功能;
◎ 可以动态修改ipset的集合,即使iptables的规则正在使用这个集 合。
由于IPVS无法提供包过滤、airpin-masquerade tricks(地址伪装)、 SNAT等功能,因此在某些场景(如NodePort的实现)下还要与iptables 搭配使用。在IPVS模式下,kube-proxy又做了重要的升级,即使用 iptables的扩展ipset,而不是直接调用iptables来生成规则链
iptables规则链是一个线性的数据结构,ipset则引入了带索引的数据 结构,因此当规则很多时,也可以很高效地查找和匹配我们可以将 ipset简单理解为一个IP(段)的集合,这个集合的内容可以是IP地址、 IP网段、端口等,iptables可以直接添加规则对这个“可变的集合”进行操 作,这样做的好处在于可以大大减少iptables规则的数量,从而减少性能 损耗
假设要禁止上万个IP访问我们的服务器,则用iptables的话,就需要 一条一条地添加规则,会在iptables中生成大量的规则;但是用ipset的 话,只需将相关的IP地址(网段)加入ipset集合中即可,这样只需设置 少量的iptables规则即可实现目标。
kube-proxy针对Service和Pod创建的一些主要的iptables规则如下
◎ KUBE-CLUSTER-IP:在masquerade-all=true或clusterCIDR指定 的情况下对Service Cluster IP地址进行伪装,以解决数据包欺骗问题。
◎ KUBE-EXTERNAL-IP:将数据包伪装成Service的外部IP地 址
◎ KUBE-LOAD-BALANCER、KUBE-LOAD-BALANCER-LOCAL:伪装Load Balancer 类型的Service流量。
◎ KUBE-NODE-PORT-TCP、KUBE-NODE-PORT-LOCAL- TCP、KUBE-NODE-PORTUDP、KUBE-NODE-PORT-LOCAL-UDP: 伪装NodePort类型的Service流量。