语法:
|
字符 |
描述 |
示例 |
|
(pattern) |
匹配pattern并捕获结果,自动设置组号。 |
(abc)+d 匹配abcd或者abcabcd |
|
(?<name>pattern) 或 (?'name'pattern) |
匹配pattern并捕获结果,设置name为组名。 |
|
|
num |
对捕获组的反向引用。其中 num 是一个正整数。 |
(w)(w)21 匹配abba |
|
k< name > 或 k' name ' |
对命名捕获组的反向引用。其中 name 是捕获组名。 |
(?<group>w)abck<group> 匹配xabcx |
例如:
(d{4})-(d{2}-(d{2}))
1 1 2 3 32
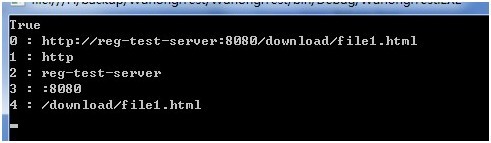
以下是用程序处理捕获组的示例,对一个Url地址进行解析,并显示所有捕获组。
可以看到按顺序设置的捕获组号。
Regex.Match方法
using System.Text.RegularExpressions;
namespace Wuhong.Test
{
class Program
{
static void Main(string[] args)
{
//目标字符串
string source = "http://reg-test-server:8080/download/file1.html# ";
//正则式
string regex = @"(w+)://([^/:]+)(:d+)?([^# :]*)";
Regex regUrl = new Regex(regex);
//匹配正则表达式
Match m = regUrl.Match(source);
Console.WriteLine(m.Success);
if (m.Success)
{
//捕获组存放在Match.Groups集合中,索引值从1开始,索引0处为匹配的整个字符串值
//按“组号 : 捕获内容”的格式显示
for (int i = 0; i < m.Groups.Count; i++)
{
Console.WriteLine(string.Format("{0} : {1}", i, m.Groups[i]));
}
}
Console.ReadLine();
}
}
}
也可以自己指定子表达式的组名。这样在表达式或程序中可以直接引用组名,当然也可以继续使用组号。但如果正则表达式中同时存在普通捕获组和命名捕获组,那么捕获组的编号就要特别注意,编号的规则是先对普通捕获组进行编号,再对命名捕获组进行编号。
例如:
(d{4})-(?<date>d{2}-(d{2}))
1 1 3 2 23
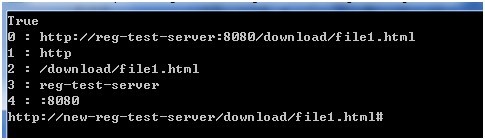
下面在程序中处理命名捕获组,显示混合规则生成的组号,并利用捕获组的内容对源字符串进行替换。
可以看到先对普通捕获组进行编号,再对命名捕获组编号。
Regex.Replace方法
using System.Text.RegularExpressions;
namespace Wuhong.Test
{
class Program
{
static void Main(string[] args)
{
//目标字符串
string source = "http://reg-test-server:8080/download/file1.html# ";
//正则式,对其中两个分组命名
string regex = @"(w+)://(?<server>[^/:]+)(?<port>:d+)?([^# :]*)";
Regex regUrl = new Regex(regex);
//匹配正则表达式
Match m = regUrl.Match(source);
Console.WriteLine(m.Success);
if (m.Success)
{
//捕获组存放在Match.Groups集合中,索引值从1开始,索引0处为匹配的整个字符串值
//按“组号 : 捕获内容”的格式显示
for (int i = 0; i < m.Groups.Count; i++)
{
Console.WriteLine(string.Format("{0} : {1}", i, m.Groups[i]));
}
}
//替换字符串
//“$组号”引用捕获组的内容。
//需要特别注意的是“$组号”后不能跟数字形式的字符串,如果出现此情况,需要使用命名捕获组,引用格式“${组名}”
string replacement = string.Format("$1://{0}{1}$2", "new-reg-test-server", "");
string result = regUrl.Replace(source, replacement);
Console.WriteLine(result);
Console.ReadLine();
}
}
}
非捕获组
语法:
|
字符 |
描述 |
示例 |
|
(?:pattern) |
匹配pattern,但不捕获匹配结果。 |
'industr(?:y|ies) 匹配'industry'或'industries'。 |
|
(?=pattern) |
零宽度正向预查,不捕获匹配结果。 |
'Windows (?=95|98|NT|2000)' 匹配 "Windows2000" 中的 "Windows" 不匹配 "Windows3.1" 中的 "Windows"。 |
|
(?!pattern) |
零宽度负向预查,不捕获匹配结果。 |
'Windows (?!95|98|NT|2000)' 匹配 "Windows3.1" 中的 "Windows" 不匹配 "Windows2000" 中的 "Windows"。 |
|
(?<=pattern) |
零宽度正向回查,不捕获匹配结果。 |
'2000 (?<=Office|Word|Excel)' 匹配 " Office2000" 中的 "2000" 不匹配 "Windows2000" 中的 "2000"。 |
|
(?<!pattern) |
零宽度负向回查,不捕获匹配结果。 |
'2000 (?<!Office|Word|Excel)' 匹配 " Windows2000" 中的 "2000" 不匹配 " Office2000" 中的 "2000"。 |
非捕获组只匹配结果,但不捕获结果,也不会分配组号,当然也不能在表达式和程序中做进一步处理。
首先(?:pattern)与(pattern)不同之处只是在于不捕获结果。
接下来的四个非捕获组用于匹配pattern(或者不匹配pattern)位置之前(或之后)的内容。匹配的结果不包括pattern。
例如:
(?<=<(w+)>).*(?=</1>)匹配不包含属性的简单HTML标签内的内容。如:<div>hello</div>之中的hello,匹配结果不包括前缀<div>和后缀</div>。
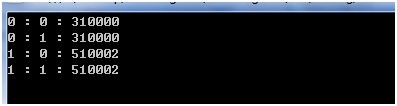
下面是程序中非捕获组的示例,用来提取邮编。
可以看到反向回查和反向预查都没有被捕获。
Regex.Matches方法
using System.Text.RegularExpressions;
namespace Wuhong.Test
{
class Program
{
static void Main(string[] args)
{
//目标字符串
string source = "有6组数字:010001,100,21000,310000,4100011,510002,把邮编挑出来。";
//正则式
string regex = @"(?<!d)([1-9]d{5})(?!d)";
Regex regUrl = new Regex(regex);
//获取所有匹配
MatchCollection mList = regUrl.Matches(source);
for (int j = 0; j < mList.Count; j++)
{
//显示每个分组,可以看到每个分组都只有组号为1的项,反向回查和反向预查没有被捕获
for (int i = 0; i < mList[j].Groups.Count; i++)
{
Console.WriteLine(string.Format("{0} : {1} : {2}", j, i, mList[j].Groups[i]));
}
}
Console.ReadLine();
}
}
}