1.简介
Docker Swarm 是 Docker原生的集群管理工具。它将 Docker 主机池转变为单个虚拟 Docker 主机。 Docker Swarm 提供了标准的 Docker API,所有任何已经与 Docker 守护程序通信的工具都可以使用 Swarm 轻松地扩展到多个主机。
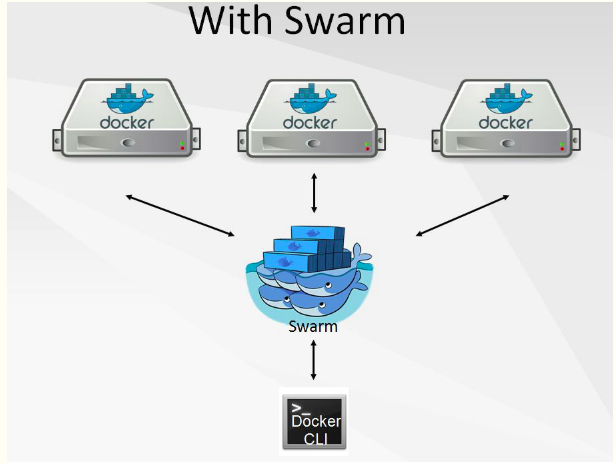
Swarm项目正是这样,通过把多个Docker Engine聚集在一起,形成一个大的docker-engine,对外提供容器的集群服务。同时这个集群对外提供Swarm API,用户可以像使用Docker Engine一样使用Docker集群。
Swarm使用标准的Docker API接口作为其前端访问入口,换言之,各种形式的Docker Client(docker client in Go, docker_py, docker等)均可以直接与Swarm通信。Swarm几乎全部用Go语言来完成开发,Swarm0.2版本增加了一个新的策略来调度集群中的容器,使得在可用的节点上传播它们,以及支持更多的Docker命令以及集群驱动。Swarm deamon只是一个调度器(Scheduler)加路由器(router),Swarm自己不运行容器,它只是接受docker客户端发送过来的请求,调度适合的节点来运行容器,这意味着,即使Swarm由于某些原因挂掉了,集群中的节点也会照常运行,当Swarm重新恢复运行之后,它会收集重建集群信息。
2.Swarm关键概念
1.Swarm
集群的管理和编排是使用嵌入到docker引擎的SwarmKit,可以在docker初始化时启动swarm模式或者加入已存在的swarm
2.Node
一个节点(node)是已加入到swarm的Docker引擎的实例 ,可以在一台物理机上运行多个node,node分为manager nodes 也就是管理节点; worker nodes 也就是工作节点.。当部署应用到集群,你将会提交服务定义到管理节点,接着Manager管理节点调度任务到worker节点,manager节点还执行维护集群的状态的编排和群集管理功能,worker节点接收并执行来自manager节点的任务。通常,manager节点也可以是worker节点,worker节点会报告当前状态给manager节点.
-> manager node管理节点:执行集群的管理功能,维护集群的状态,选举一个leader节点去执行调度任务。
-> worker node工作节点:接收和执行任务。参与容器集群负载调度,仅用于承载task。
3.服务(Service)
一个服务是工作节点上执行任务的定义。创建一个服务,指定了容器所使用的镜像和容器运行的命令。service是运行在worker nodes上的task的描述,service的描述包括使用哪个docker 镜像,以及在使用该镜像的容器中执行什么命令。
4.任务(Task)
任务是在docekr容器中执行的命令,task是service的执行实体,task启动docker容器并在容器中执行任务。Manager节点根据指定数量的任务副本分配任务给worker节点。
3.Swarm架构和特点
1.架构
Swarm作为一个管理Docker集群的工具,首先需要将其部署起来,可以单独将Swarm部署于一个节点。另外,自然需要一个Docker集群,集群上每一个节点均安装有Docker。具体的Swarm架构图可以参照下图:
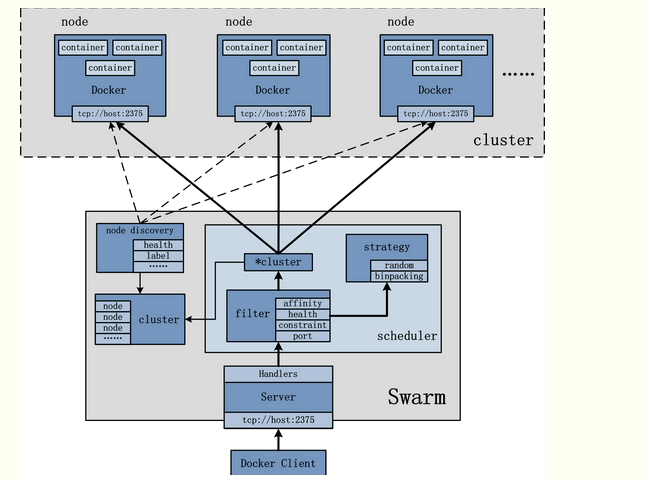
Swarm架构中最主要的处理部分自然是Swarm节点,Swarm管理的对象自然是Docker Cluster,Docker Cluster由多个Docker Node组成,而负责给Swarm发送请求的是Docker Client。
2.特点
Docker的Swarm (集群) 模式,集成很多工具和特性,比如:跨主机上快速部署服务,服务的快速扩展,集群的管理整合到docker引擎,分散设计,声明式的服务模型,可扩展,状态协调处理,多主机网络,分布式的服务发现,负载均衡,滚动更新,安全(通信的加密)。
1) 对外以Docker API接口呈现,这样带来的好处是,如果现有系统使用Docker Engine,则可以平滑将Docker Engine切到Swarm上,无需改动现有系统。
2) Swarm对用户来说,之前使用Docker的经验可以继承过来。非常容易上手,学习成本和二次开发成本都比较低。同时Swarm本身专注于Docker集群管理,非常轻量,占用资源也非常少。简单说,就是插件化机制,Swarm中的各个模块都抽象出了API,可以根据自己一些特点进行定制实现。
3) Swarm自身对Docker命令参数支持的比较完善,Swarm目前与Docker是同步发布的。Docker的新功能,都会第一时间在Swarm中体现。
4.Swarm工作方式
1.Node
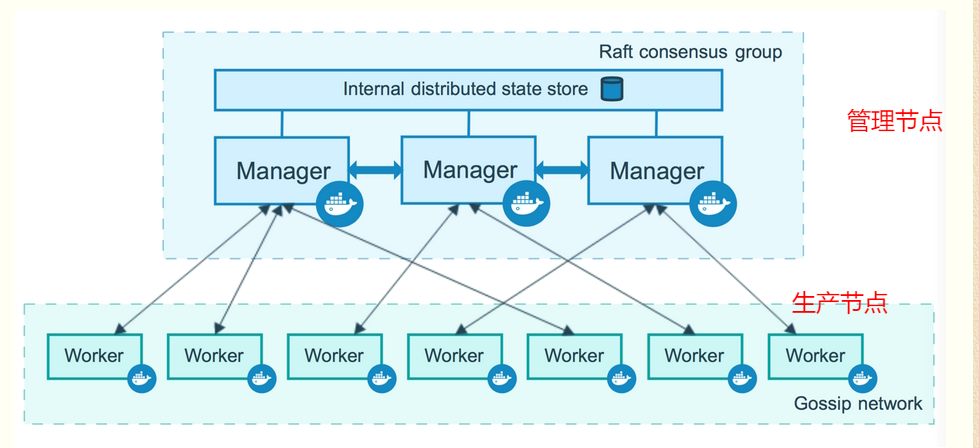
2.Service(服务, 任务, 容器)

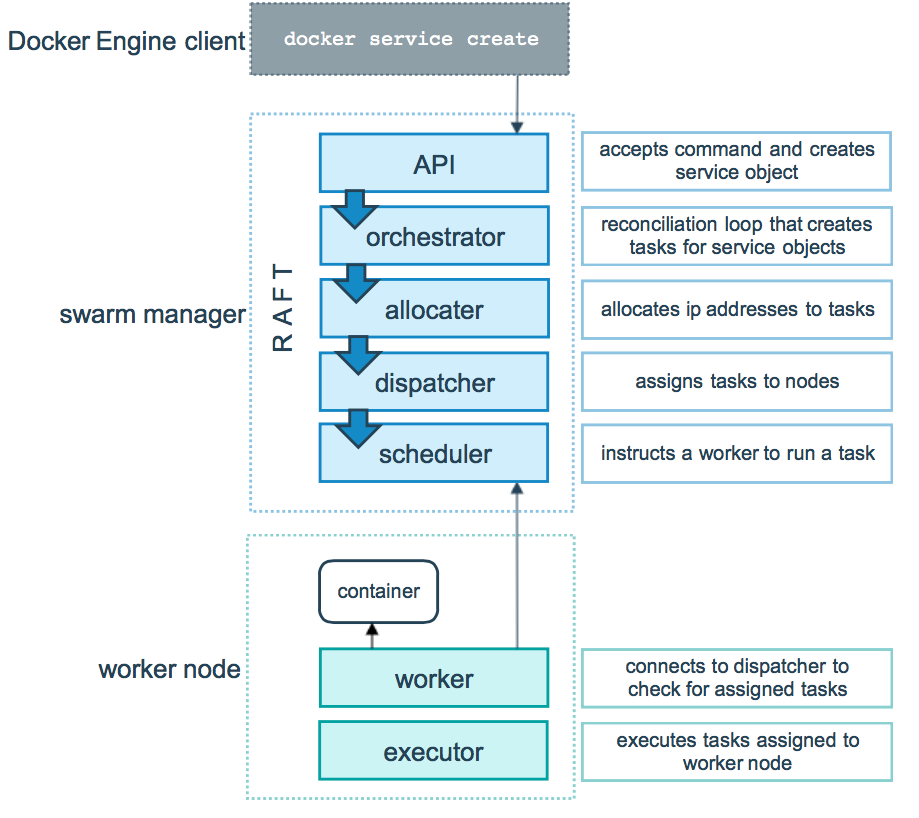
3.任务与调度
命令--->管理节点--->调用API--->通过调度算法进行调度--->工作节点(执行task创建容器和维护)
逻辑图如下
4.服务副本与全局服务
逻辑图如下

服务是Swarm集群中最重要的一个概念,服务分为服务副本服务,和全局服务,服务副本服务根据我们指定的副本数,然后再根据调度算法,把具体的容器跑在调度后的节点上。
然后全局服务就是他会把后台容器运行在集群里的全部节点上,不根据调度算法进行调度。
这里还要提一个概率就是在Swarm集群中真正提供服务的是Service。客户端真正访问的是你通过Swarm创建的服务。他不管你这个服务后面跑了几个容器,和跑在了哪些服务器上。屏蔽了底层的差异。概念图如下
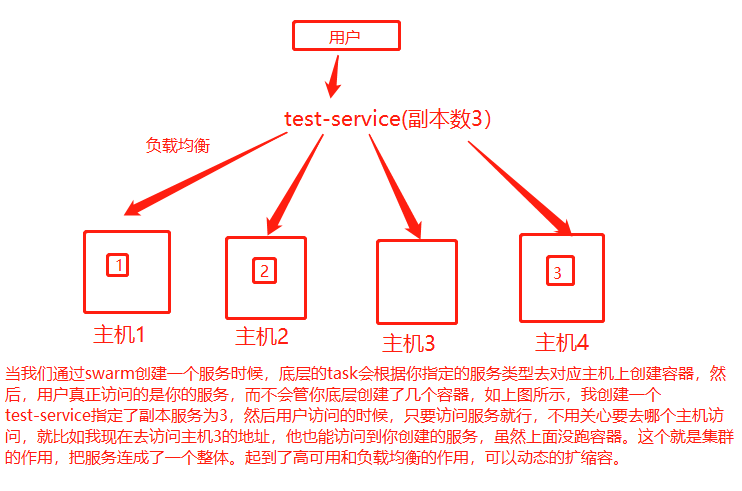
5.Swarm调度策略
Swarm在scheduler节点(leader节点)运行容器的时候,会根据指定的策略来计算最适合运行容器的节点,目前支持的策略有:spread, binpack, random.
1.Random(随机算法)
顾名思义,就是随机选择一个Node来运行容器,一般用作调试用,spread和binpack策略会根据各个节点可用的CPU, RAM以及正在运行的容器数量来计算应该运行容器的节点。
2.Spread(资源平均算法)
在同等条件下,Spread策略会选择运行容器最少的那台节点来运行新的容器,binpack策略会选择运行容器最集中的那台机器来运行新的节点。使用Spread策略会使得容器会均衡的分布在集群中的各个节点上运行,一旦一个节点挂掉了只会损失少部分的容器。
3.Binpack(资源集中算法)
Binpack策略最大化的避免容器碎片化,就是说binpack策略尽可能的把还未使用的节点留给需要更大空间的容器运行,尽可能的把容器运行在一个节点上面。
6.Swarm Cluster模式的特性和集群的内部创建过程
1.批量创建服务
建立容器之前先创建一个overlay的网络,用来保证在不同主机上的容器网络互通的网络模式
2.强大的集群的容错性
当容器副本中的其中某一个或某几个节点宕机后,cluster会根据自己的服务注册发现机制,以及之前设定的值--replicas n,在集群中剩余的空闲节点上,重新拉起容器副本。整个副本迁移的过程无需人工干预,迁移后原本的集群的load balance(负载均衡)依旧好使!不难看出,docker service其实不仅仅是批量启动服务这么简单,而是在集群中定义了一种状态。Cluster会持续检测服务的健康状态并维护集群的高可用性。
3.服务节点的可扩展性
Swarm Cluster不光只是提供了优秀的高可用性,同时也提供了节点弹性扩展或缩减的功能。当容器组想动态扩展时,只需通过scale参数即可复制出新的副本出来。仔细观察的话,可以发现所有扩展出来的容器副本都run在原先的节点下面,如果有需求想在每台节点上都run一个相同的副本,方法其实很简单,只需要在命令中将"--replicas n"更换成"--mode=global"即可!其中:
复制服务(--replicas n)将一系列复制任务分发至各节点当中,具体取决于您所需要的设置状态,例如“--replicas 3”。
全局服务(--mode=global)适用于集群内全部可用节点上的服务任务,例如“--mode global”。如果在 Swarm 集群中设有 7 台 Docker 节点,则全部节点之上都将存在对应容器。
4.调度机制
所谓的调度其主要功能是cluster的server端去选择在哪个服务器节点上创建并启动一个容器实例的动作。它是由一个装箱算法和过滤器组合而成。每次通过过滤器(constraint)启动容器的时候,swarm cluster 都会调用调度机制筛选出匹配约束条件的服务器,并在这上面运行容器。
5.Swarm cluster的创建过程
1)发现Docker集群中的各个节点,收集节点状态、角色信息,并监视节点状态的变化
2)初始化内部调度(scheduler)模块
3)创建并启动API监听服务模块
一旦创建好这个cluster,就可以用命令docker service批量对集群内的容器进行操作,非常方便!
在启动容器后,docker 会根据当前每个swarm节点的负载判断,在负载最优的节点运行这个task任务,用"docker service ls" 和"docker service ps + taskID"
可以看到任务运行在哪个节点上。容器启动后,有时需要等待一段时间才能完成容器创建。
7.Swarm集群的部署和使用
1.环境介绍和准备
#机器环境 172.31.46.38 swarm的manager节点1 manager-node1 172.31.46.78 swarm的manager节点2 manager-node2 172.31.46.22 swarm的node节点 node1 172.31.46.115 swarm的node节点 node2 #设置主机名 [root@linux-test-no ~]# hostnamectl --static set-hostname manager-node1 [root@gitlab ~]# hostnamectl --static set-hostname manager-node2 [root@gitlab ~]# hostnamectl --static set-hostname node1 [root@centos-test4-no ~]# hostnamectl --static set-hostname node2 #在三台机器上都要设置hosts,均执行如下命令 [root@linux-test-no ~]# vim /etc/hosts 172.31.46.38 manager-node1 172.31.46.78 manager-node2 172.31.46.22 node1 172.31.46.115 node2 #关闭三台机器上的防火墙。如果开启防火墙,则需要在所有节点的防火墙上依次放行2377/tcp(管理端口)、7946/udp(节点间通信端口)、4789/udp(overlay 网络端口)端口。 [root@manager-node1 ~]# systemctl disable firewalld.service [root@manager-node1 ~]# systemctl stop firewalld.service
2.分别在manager节点和node节点上安装docker,并下载swarm镜像
[root@manager-node1 ~]# yum install -y docker #配置docker,注意修改管理节点上的docker的以下配置时,管理节点最好是在内网,或者做好严格的防火墙策略,因为此配置会暴露端口,这是不安全的。 [root@manager-node1 ~]# vim /etc/sysconfig/docker ...... OPTIONS='-H 0.0.0.0:2375 -H unix:///var/run/docker.sock' //在OPTIONS参数项后面的''里添加内容. 或者使用'-H tcp://0.0.0.0:2375 -H unix:///var/run/docker.sock' [root@manager-node1 ~]# systemctl restart docker #下载swarm镜像 [root@manager-node1 ~]# docker pull swarm
[root@manager-node1 ~]# docker images #注意这些操作每台机器上都要做
3.创建swarm
#执行下面命令,创建swarm集群,会初始化此节点为主管理节点,并生成一个集群token,获取全球唯一的 token,作为集群唯一标识。
后续将其他节点加入集群都会用到这个token值。其中,--advertise-addr参数表示其它swarm中的worker节点使用此ip地址与manager
联系。命令的输出包含了其它节点如何加入集群的命令。
[root@manager-node1 ~]# docker swarm init --advertise-addr 172.31.46.38 Swarm initialized: current node (6usguns6poiaj9t5d0k2c4qxm) is now a manager. To add a worker to this swarm, run the following command: docker swarm join --token SWMTKN-1-0sxi3xn7ebz59r7scvsy8xp4jss78xq25e86m2ikk3xot8oa71-ahklh8z5cftatplqi3skr7hja 172.31.46.38:2377 To add a manager to this swarm, run 'docker swarm join-token manager' and follow the instructions.
温馨提示:如果再次执行上面启动swarm集群的命令,会报错说这个节点已经在集群中了Error response from daemon: This node is already part of a swarm. Use "docker swarm leave" to leave this swarm and join another one.解决办法:[root@manager-node ~]# docker swarm leave --help //查看帮助[root@manager-node ~]# docker swarm leave --force使用docker info 或 docker node ls 查看集群中的相关信息[root@manager-node1 ~]# docker info Swarm: active NodeID: chz1o1jfusf64y3z2xo4cf5hj Is Manager: true ClusterID: ipozawcrtpgxqu83oomnw0jfc Managers: 1 Nodes: 1 Default Address Pool: 10.0.0.0/8 SubnetSize: 24 Data Path Port: 4789 Orchestration: Task History Retention Limit: 5 ........ #node ID旁边那个*号表示现在连接到这个节点上。 [root@manager-node1 ~]# docker node ls ID HOSTNAME STATUS AVAILABILITY MANAGER STATUS ENGINE VERSION chz1o1jfusf64y3z2xo4cf5hj * manager-node1 Ready Active Leader 19.03.12
4.添加节点到swarm集群中
#在docker swarm init 完了之后,会提示如何加入新机器到集群,如果当时没有注意到,也可以通过下面的命令来获知 如何加入新机器到集群。 #下面这个命令就是获知从管理节点如何加入集群。 [root@manager-node1 ~]# docker swarm join-token manager To add a manager to this swarm, run the following command: docker swarm join --token SWMTKN-1-37f9hi4mgyw1lmvk91m4fzwop0llz4xcxj66afpm71vt045ax8-9uxgmoz208dybs2l84m1sorgb 172.31.46.38:2377 #下面命令就是获知工作节点如何加入集群。 [root@manager-node1 ~]# docker swarm join-token worker To add a worker to this swarm, run the following command: docker swarm join --token SWMTKN-1-37f9hi4mgyw1lmvk91m4fzwop0llz4xcxj66afpm71vt045ax8-6m4yrfnzqguwke99prkyph37u 172.31.46.38:2377
现在我们按照上面的提示,把工作节点和从管理节点加入Swarm集群中
[root@manager-node2 ~]# docker swarm join --token SWMTKN-1-37f9hi4mgyw1lmvk91m4fzwop0llz4xcxj66afpm71vt045ax8-9uxgmoz208dybs2l84m1sorgb 172.31.46.38:2377 This node joined a swarm as a manager. [root@node1 ~]# docker swarm join --token SWMTKN-1-37f9hi4mgyw1lmvk91m4fzwop0llz4xcxj66afpm71vt045ax8-6m4yrfnzqguwke99prkyph37u 172.31.46.38:2377 This node joined a swarm as a worker. [root@node2 ~]# docker swarm join --token SWMTKN-1-37f9hi4mgyw1lmvk91m4fzwop0llz4xcxj66afpm71vt045ax8-6m4yrfnzqguwke99prkyph37u 172.31.46.38:2377 This node joined a swarm as a worker. #如果想要将其他更多的节点添加到这个swarm集群中,添加方法如上一致! #然后在manager-node管理节点上看一下集群节点的状态,这里我们看到两个管理节点和工作节点都已经加入集群了。 [root@manager-node1 ~]# docker node ls ID HOSTNAME STATUS AVAILABILITY MANAGER STATUS ENGINE VERSION chz1o1jfusf64y3z2xo4cf5hj * manager-node1 Ready Active Leader 19.03.12 imnk5zo056q2hvqhizrc6fmof manager-node2 Ready Active Reachable 19.03.12 rn69cydbcwinf1bjf8mmefdry node1 Ready Active 1.13.1 zjjh4qgpmgz0xnycoo05i1hsl node2 Ready Active 1.13.1
#注意在Swarm集群中,节点的高可用用的是Raft协议,此协议保证大多数节点存活,但是有个要求就是节点数量要>1。意思就是集群数量要大于3台,
所以生产中,管理节点数量最少都得3台,不然起不到高可用的作用。可以通过实验进行验证。
节点可用性状态的变更和节点的下线
swarm集群中node的availability状态可以为 active或者drain,其中:active状态下,node可以接受来自manager节点的任务分派;drain状态下,node节点会结束task,且不再接受来自manager节点的任务分派(也就是下线节点)。#将node1节点下线。如果要删除node1节点,命令是"docker node rm --force node1" [root@manager-node1 ~]# docker node update --availability drain node1 [root@manager-node1 ~]# docker node ls ID HOSTNAME STATUS AVAILABILITY MANAGER STATUS ENGINE VERSION chz1o1jfusf64y3z2xo4cf5hj * manager-node1 Ready Active Leader 19.03.12 imnk5zo056q2hvqhizrc6fmof manager-node2 Ready Active Reachable 19.03.12 rn69cydbcwinf1bjf8mmefdry node1 Ready Drain 1.13.1 zjjh4qgpmgz0xnycoo05i1hsl node2 Ready Active 1.13.1 #如上,当node1的状态改为drain后,那么该节点就不会接受task任务分发,就算之前已经接受的任务也会转移到别的节点上。 #再次修改为active状态(及将下线的节点再次上线) [root@manager-node1 ~]# docker node update --availability active node1
5.在Swarm中部署服务和动态扩缩容服务(这里以nginx服务为例)
部署服务
#Docker 1.12版本开始提供服务的Scaling、health check、滚动升级等功能,并提供了内置的dns、vip机制,实现service的服务发现和负载均衡能力。 在启动容器之前,先来创建一个覆盖网络,用来保证在不同主机上的容器网络互通的网络模式 [root@manager-node1 ~]# docker network create -d overlay ngx_net 98uvwubk9tdavnuk773vld2cs [root@manager-node1 ~]# docker network ls NETWORK ID NAME DRIVER SCOPE cb7dc85b72db bridge bridge local 2b17077d3733 docker_gwbridge bridge local 79232f7835db host host local w0z1t4vgkctw ingress overlay swarm 98uvwubk9tda ngx_net overlay swarm 58d353d474cd none null local #在manager-node节点上使用上面这个覆盖网络创建nginx服务: 其中,--replicas 参数指定服务由几个实例组成。 注意:不需要提前在节点上下载nginx镜像,这个命令执行后会自动下载这个容器镜像(比如此处创建tomcat容器,就将下面命令中的镜像改为tomcat镜像)。 以下命令就创建了一个具有一个副本(--replicas 1 )的nginx服务,使用镜像nginx [root@manager-node1 ~]# docker service create --replicas 1 --network ngx_net --name my-test -p 80:80 nginx #使用 docker service ls 查看正在运行服务的列表 [root@manager-node1 ~]# docker service ls ID NAME MODE REPLICAS IMAGE PORTS l5m69s1p88ae my-test replicated 1/1 nginx:latest *:80->80/tcp #查询Swarm中服务的信息 -pretty 使命令输出格式化为可读的格式,不加 --pretty 可以输出更详细的信息: [root@manager-node1 ~]# docker service inspect --pretty my-test ID: l5m69s1p88aegop9gp8z56nrm Name: my-test Service Mode: Replicated Replicas: 1 Placement: UpdateConfig: Parallelism: 1 On failure: pause Monitoring Period: 5s Max failure ratio: 0 Update order: stop-first RollbackConfig: Parallelism: 1 On failure: pause Monitoring Period: 5s Max failure ratio: 0 Rollback order: stop-first ContainerSpec: Image: nginx:latest@sha256:4cf620a5c81390ee209398ecc18e5fb9dd0f5155cd82adcbae532fec94006fb9 Init: false Resources: Networks: ngx_net Endpoint Mode: vip Ports: PublishedPort = 80 Protocol = tcp TargetPort = 80 PublishMode = ingress #查询服务在哪个节点正在运行该服务。如下该容器被调度到manager-node1节点上启动了,然后访问http://172.31.46.38即可访问这个容器应用(如果调度到其他节点,访问也是如此) [root@manager-node1 ~]# docker service ps my-test ID NAME IMAGE NODE DESIRED STATE CURRENT STATE ERROR PORTS nb8f24ab7byc my-test.1 nginx:latest manager-node1 Running Running 19 hours ago
在Swarm中动态扩展服务(scale)
当然,如果只是通过service启动容器,swarm也算不上什么新鲜东西了。Service还提供了复制(类似kubernetes里的副本)功能。可以通过 docker service scale 命令来设置服务中容器的副本数:
#比如将上面的my-test容器动态扩展到5个,命令如下: [root@manager-node1 ~]# docker service scale my-test=5 #查看服务的运行节点情况,可以看到,之前my-test容器只在manager-node1节点上有一个实例,而现在又增加了4个实例。 这5个副本的my-test容器分别运行在这4个节点上,登陆这4个节点,就会发现已经存在运行着的my-test容器。 [root@manager-node1 ~]# docker service ps my-test ID NAME IMAGE NODE DESIRED STATE CURRENT STATE ERROR PORTS nb8f24ab7byc my-test.1 nginx:latest manager-node1 Running Running 19 hours ago sg957wty6pec my-test.2 nginx:latest node2 Running Running 3 minutes ago k54lm9gpqzra my-test.3 nginx:latest manager-node2 Running Running 3 minutes ago qtn9abnt8mjr my-test.4 nginx:latest node1 Running Running 3 minutes ago ksihqnoa6k8l my-test.5 nginx:latest node2 Running Running 3 minutes ago
特别需要清楚的一点:如果一个节点宕机了(即该节点就会从swarm集群中被踢出),则Docker应该会将在该节点运行的容器,调度到其他节点,以满足指定数量的副本保持运行状态。比如:将node1宕机后或将node1的docker服务关闭,那么它上面的task实例就会转移到别的节点上。当node1节点恢复后,它转移出去的task实例不会主动转移回来,只能等别的节点出现故障后转移task实例到它的上面。即在swarm cluster集群中启动的容器,在worker node节点上删除或停用后,该容器会自动转移到其他的worker node节点上在Swarm中动态缩容服务
#如下,将my-test容器变为1个。 [root@manager-node1 ~]# docker service scale my-test=1 [root@manager-node1 ~]# docker service ps my-test ID NAME IMAGE NODE DESIRED STATE CURRENT STATE ERROR PORTS nb8f24ab7byc my-test.1 nginx:latest manager-node1 Running Running 19 hours ago sg957wty6pec my-test.2 nginx:latest node2 Remove Running 30 seconds ago qtn9abnt8mjr my-test.4 nginx:latest node1 Remove Running 30 seconds ago ksihqnoa6k8l my-test.5 nginx:latest node2 Remove Running 30 seconds ago #登录node2节点,使用docker ps查看,会发现容器被stop而非rm,即Swarm缩容只是停掉对应容器,而非删除。 #删除容器服务,如下这样就会把所有节点上的所有容器(task任务实例)全部删除了 [root@manager-node1 ~]# docker service rm my-test
除了上面使用scale进行容器的扩容或缩容之外,还可以使用docker service update 命令。 可对 服务的启动 参数 进行 更新/修改。
#使用如下命令,也可以对容器的规模进行更新。 [root@manager-node1 ~]# docker service update --replicas 3 my-test #也可用于直接 升级 镜像 [root@manager-node1 ~]# docker service update --image nginx:new my-test
6.Swarm中使用Volume
方法1:
#通过下面创建数据卷,默认会在/var/lib/docker/volumes/目录下创建你要的数据卷目录。 [root@manager-node1 ~]# docker volume create --name myvolume #使用下面命令,Swarm创建service的时候指定数据卷。参数src表示指定的数据卷,写成source也可以;dst表示容器内的路径,也可以写成destination [root@manager-node ~]# docker service create --replicas 2 --network ngx_net --mount type=volume,src=myvolume,dst=/wangshibo --name test-nginx nginx
1) 挂载volume后,宿主机和容器之间就可以通过volume进行双向实时同步.2) 如果replicas是多份,则每个节点宿主机上都会有一个volume路径,即每个节点宿主机的/var/lib/docker/volumes/myvolume/_data和分布到它上面的 容器里的/wangshibo进行实时同步.方法2:
#命令格式如下,其中,参数destination表示容器里面的路径,source表示本地硬盘路径 docker service create --mount type=bind,source=/host_data/,destination=/container_data/ #注意此方法设置后,在容器里的同步目录下没有写权限,更新内容时只要放到宿主机的挂在目录下即可!
8.总结
Swarm上手很简单,Docker swarm可以非常方便的创建类似kubernetes那样带有副本的服务,确保一定数量的容器运行,保证服务的高可用。
然而,光从官方文档来说,功能似乎又有些简单;
swarm、kubernetes、messos总体比较而言:
1)Swarm的优点和缺点都是使用标准的Docker接口,使用简单,容易集成到现有系统,但是更困难支持更复杂的调度,比如以定制接口方式定义的调度。
2)Kubernetes 是自成体系的管理工具,有自己的服务发现和复制,需要对现有应用的重新设计,但是能支持失败冗余和扩展系统。
3)Mesos是低级别
battle-hardened调度器,支持几种容器管理框架如Marathon, Kubernetes, and
Swarm,现在Kubernetes和Mesos稳定性超过Swarm,在扩展性方面,Mesos已经被证明支持超大规模的系统,比如数百数千台主机,但是,如果你需要小的集群,比如少于一打数量的节点服务器数量,Mesos也许过于复杂了。