Transformer 是一类使用注意力机制(self-attention)加速运算的模型. 由 attention is all you need一文提出(google,NIPS,2017)
transformer实现
1、基于encoder-decoder的架构。encoder和decoder均为6层结构。
encoder有两个子层(sublayer), multi-head attention 和 point wise fc.
decoder有三个子层,masked multi-head attention、multi-head attention(用来处理encoder输出) 和 point wise fc.
2、特点:
- 仅使用attention结构,没有使用循环神经网络or卷积
- 能够大幅缩短模型训练时间
3、结构
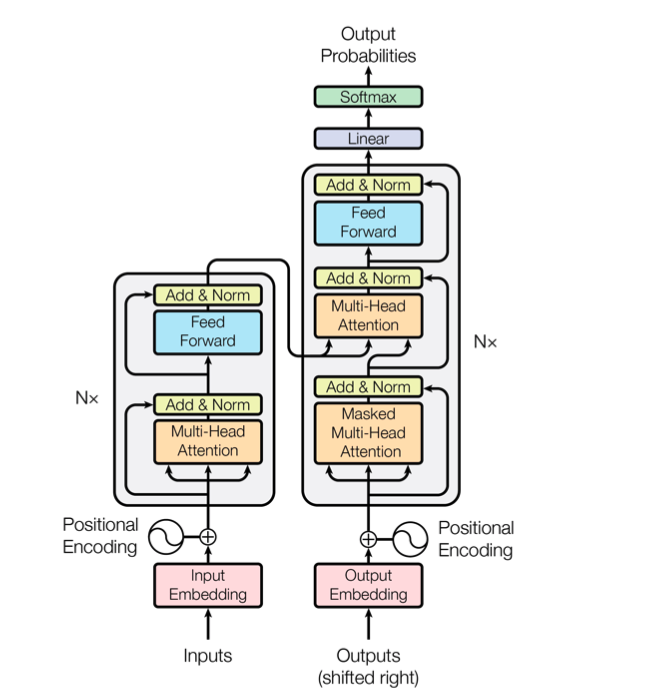
transformer子结构:
multi-head attention
1)scale dot-product attention
attention输入:query, key, value
计算方法:query和key计算weight,weight和value做matmul获取attention的输出;
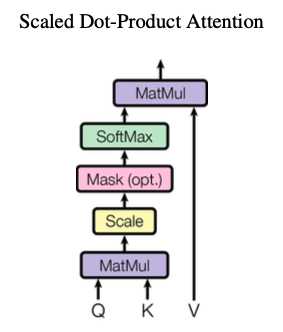
作者认为,当d_k较大时,会把点积结果推向softmax的梯度平缓区,影响了模型训练的稳定性。
因此,在做softmax之前加一个尺度因子,网络为scaled dot production attention.
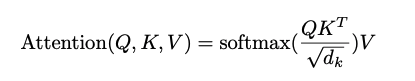
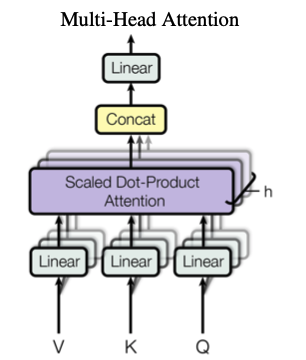
2)multi-head attention
计算方法:
1.query, key, value经过线性投影,获取不同子空间的表示;
2.每个子空间的Q, K, V做attention
3.把attention的结果拼接(concat),然后做线性变换(linear)即可获取multi-head attention的结果

position wise feedforward network
计算方法:FFN ---> ReLu ---> FFN
1.position wise是因为处理的是第i个位置的attention输出,FFN分别作用在每个position
2.同一层内,FFN的网络参数是相同的。在不同层,FFN的参数不同。
FFN(x) = max(0, xW1+b1)W2 + b2
3.attention输出维度d_model=512,经过position wise fc, W1的维度为d_model*d_ff, W2的维度为d_ff*d_model, d_ff={1024, 2048, 4096}
相当于:每个位置attention的结果映射到更大维度的特征空间,然后通过ReLu整流筛选,最后经过fc还原至原来的维度。
Layer Normalization
transformer中每一个子结构均使用了残差连接(res Add)和归一化(Layer Normalization ,2016),每个子层输出: LayerNorm(x + Sublayer(x)).

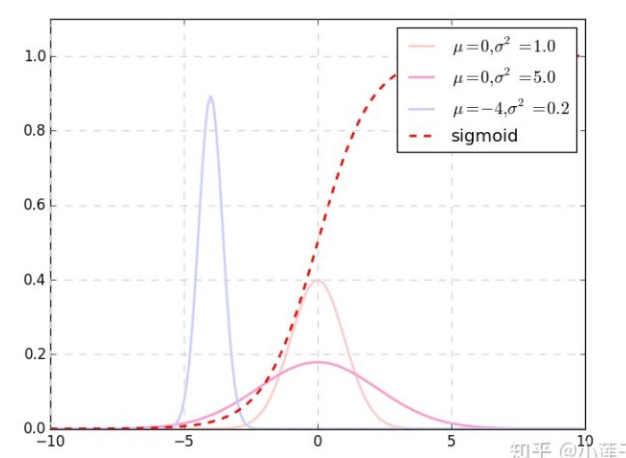
layer norm好处:
① 分布平移后,让激活值落在 f() 梯度敏感的区间,梯度值大,增加训练速度;
② 将数据"白化",消除极端值,提升训练稳定性
③ 梯度敏感区间内隐层输出接近线性,模型表达能力下降。 使用增益g_i和b_i增加模型表达能力。
④ Norm 通常放在非线性函数之前。transformer的非线性在self-attention的softmax和FFN的ReLu。把LN设置在每个子层的输出,不是为了让激活值落在梯度敏感的区间,更重要的目的是为了"白化",让每个词的向量化数值更加均衡,以消除极端情况对模型的影响,获得更稳定的深层网络结构。在和之前的 TWWT 实验一样的配置中,删除了全部的 LN 层后模型不再收敛。LN 正如 LSTM 中的tanh,它为模型提供非线性以增强表达能力,同时将输出限制在一定范围内。 因此,对于 Transformer 来说,LN 的效果已经不是“有多好“的范畴了,而是“不能没有”。
batch norm 和 layer norm 区别:
BN是在一个batch内,统计某个特定神经元节点的输出分布(跨样本);
LN是在一次迭代中,统计同一层所有神经元节点的输出分布(同一样本);

embedding and softmax
1.encoder和decoder的输入均接入embedding层,且embedding的参数相同
2.embedding层把encoder的input和decoder的input计算为高维特征空间的向量表示,d_model=512
3.对于decoder的输出,使用线性变换和softmax归一化,获取预测token的概率
⭐️position encoding
1.加入position encoding是为了增加token在序列中的位置信息,维度和d_model相同,可直接相加。
(1)facebook 版本(postional embedding, Convolutional Sequence to Sequence Learning ):learned and fixed, 只能表征有限长度内的位置,无法对任意位置进行建模.
(2)google版本(encode) : 使用公式建模,无长度限制,具体公式如下:

self-attention
考虑3方面的因素:
1.每一层的计算复杂度
2.可以并行计算的总量,用sequential operations衡量。 需要的sequential operations越少,说明并行计算程度越高。
3.网络中的long range dependencies, 使用max path length衡量。max path length越小,说明长时依赖越小。
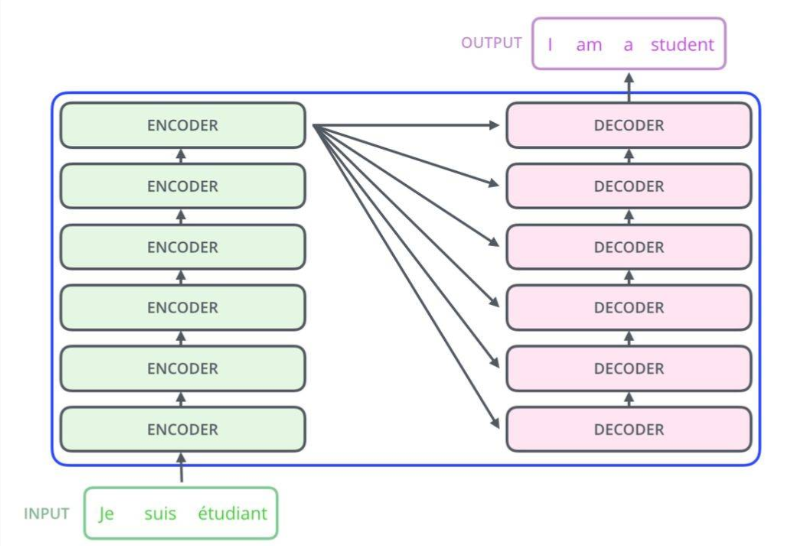
整体结构:

内部结构(6个encoder + 6个decoder):
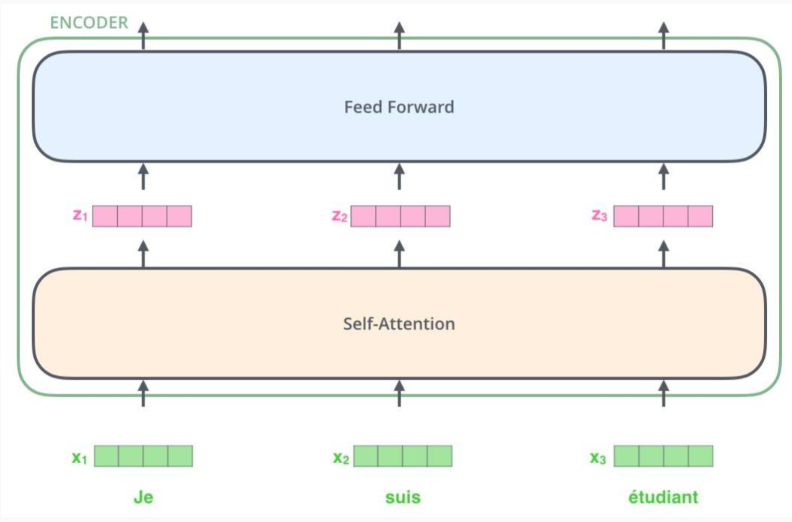
encoder内部结构:

self-attention对单词进行编码时,会关注输入句子中的其他单词;
decoder内部结构:
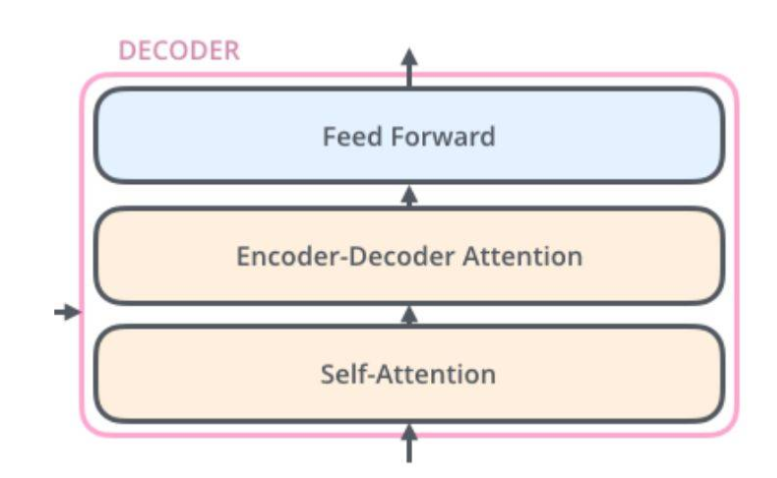
self-attention在解码时,会关注输入句子的其他单词;
encoder-decoder attention在解码时,关注输入句子中相关的部分;
attention
自注意力机制
前处理符号过滤 >> 分词 >> embedding把词转为向量(发生在最底层的encoder) >> 向量流经self-attention和feed forward处理
self-attention (自注意力)
【def】找出一个句子中各单词之间的关系,为其赋予正确的注意力
【计算分为4步】
1.使用embedding vector计算获取query vector(查询向量), key vector(键向量), value vector(值向量)

2.计算出 当前单词查询向量(query vector)和其它单词键向量(key vector)相乘的得分,该得分表名对当前向量进行编码时,对其它单词应该实施多少关注。
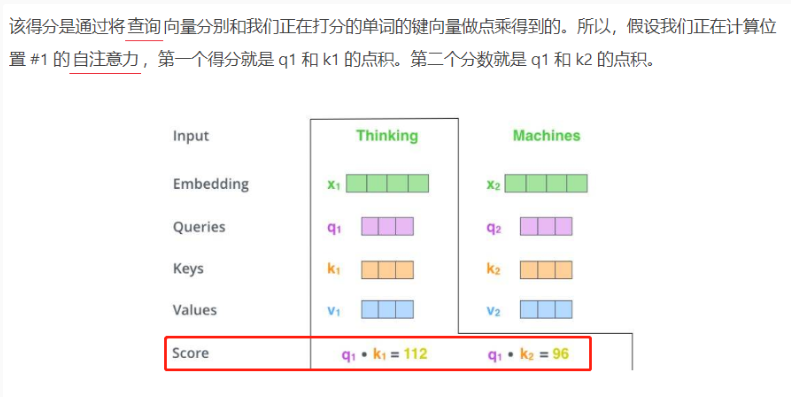
3.把score除以8(使用的键向量的维度(64)的平方根,以得到更稳定的梯度),然后计算softmax。处理后的得分决定了每个单词在这个位置上被「表达」的程度。

4.将每个值向量(value vector)与softmax得分相乘。目的是把[关注]的单词值向量维持在较高水平,把无关单词的值向量维持在较低水平(通过将值向量与softmax得分 0.001 这样极小的数字相乘)。然后对加权后的值向量进行求和,获取当前编码位置的self-attention输出。

【参考】
https://www.jiqizhixin.com/articles/2019-04-07-3
https://towardsdatascience.com/transformers-141e32e69591
https://zhuanlan.zhihu.com/p/60821628
