上篇博客说到绘制用户画像时根据用户行为计算标签权重很重要,计算标签权重最常用的算法是TF-IDF标签权重算法,但是如何计算并没有详细介绍,那么这篇博客咱们就来详细说说基于TF-IDF算法计算用户标签权重。
TF-IDF算法用以评估一个字词对于一个文件集或一个语料库中的其中一份文件的重要程度,常用于计算标签的重要程度,一个标签的重要程度随着它在一篇文章出现的次数成正比,随着它在整个文档集中出现的次数成反比。
我们用W(P,T)表示一个标签T被用于标记商品P的次数,用TF(P,T)表示这个标签在商品P所有标签中所占的比重。
TF为词频即词条在某文档中出现的频率,TF(P,T)=W(P,T)/ΣW(P,Ti),即TF=该标签标记该商品的次数 / 该商品全部标签个数
IDF为逆向文件频率即标签T在全部标签中的稀缺程度,IDF(P,T)=ΣW(Pi,Ti) / ΣW(Pi,T),即IDF=全部商品个数 / 包含T标签的商品数
实例
标签A:商品1 商品2 商品4 商品6
商品1:标签A 标签C 标签D
商品2:标签B 标签C 标签E
商品3:标签A 标签D
对于标签A,TF(1,A)=1/3,IDF(1,A)=3/2,则该标签对于该商品的重要程度即该标签的权重值=TF*IDF=1/3 * 3/2= 1/2
用户行为表结构
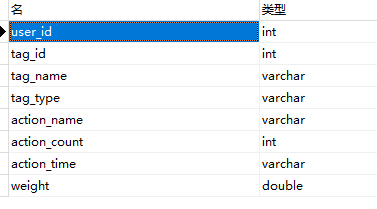
user_id:用户id
tag_id:标签id
tag_name:标签名称,用户某一行为与该标签联系
tag_type:标签类型
action_name:用户行为名称,如搜索,点击,收藏等
action_count:用户该行为的次数
action_time:用户该行为的时间,某年某月某日
weight:该标签的权重
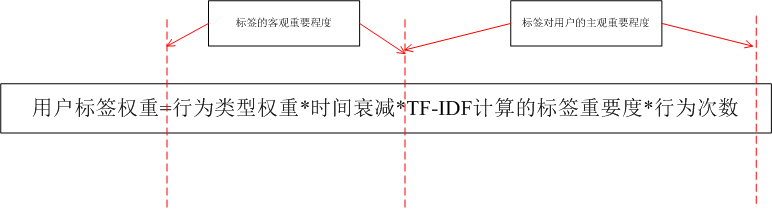
行为类型权重
用户浏览、搜索、收藏、取消收藏等不同行为反映用户对商品的喜爱程度,不同行为的权重也不同,权重值的设置该应根据具体应用场景来设置其值。比如浏览、搜索、收藏代表用户喜欢商品,应设为正值,但是收藏>搜索>浏览,取消收藏代表用户不喜欢该类商品,其权重应设为负值。

时间衰减
一般考虑时间,用户的行为会随着时间的过去,历史行为和当前的相关性不断减弱,例如去年发生的行为和今年发生的行为应该是有衰减逻辑在里面的,在建立与时间衰减相关的函数时,我们可套用牛顿冷却定律数学模型。如果周期小或业务场景稳定,也可以选择忽略这个因素。
行为次数
记录用户在同一天中,同一行为的次数。
标签重要度
代码实现
package recommender;
import java.util.Arrays;
import java.util.List;
/**
* Created by bee on 2020/2/5.
*/
public class test {
/**
*calculate the tag frequency
*/
public double tf(List<String> product, String term) {
double termFrequency = 0;
for (String str : product) {
if (str.equalsIgnoreCase(term)) {
termFrequency++;
}
}
return termFrequency / product.size();
}
/**
*calculate the document frequency
*/
public int df(List<List<String>> tags, String term) {
int count = 0;
if (term != null && term != "") {
for (List<String> product : tags) {
for (String tag : product) {
if (term.equalsIgnoreCase(tag)) {
count++;
break;
}
}
}
} else {
System.out.println("要计算的tag不能为空");
}
return count;
}
/**
*calculate the inverse document frequency
*/
public double idf(List<List<String>> tags, String term) {
return Math.log(tags.size()/(double)df(tags,term));
}
/**
* calculate tf-idf
*/
public double tfIdf(List<String> product, List<List<String>> tags, String term) {
return tf(product, term) * idf(tags, term);
}
public static void main(String[] args) {
List<String> product1 = Arrays.asList("男鞋", "潮流", "秋季", "皮鞋", "英伦","简约");
List<String> product2 = Arrays.asList("简约", "秋季", "运动鞋", "男鞋", "休闲", "时尚");
List<String> product3 = Arrays.asList("女鞋", "日韩", "可爱", "娃娃鞋", "甜美", "名媛风");
List<List<String>> tags = Arrays.asList(product1, product2, product3);
test calculator = new test();
double tfidf = calculator.tfIdf(product1, tags, "简约");
System.out.println("TF-IDF (简约) = " + tfidf);
double count = (1.0/6) * Math.log(3.0/2);
System.out.println(count);
}
}
运行结果
