1. HDFS的元数据管理
按照类型分为:文件,目录自身属性的信息。文件记录的信息,储存相关的信息。datanode的信息。
按照形式分为:内存元数据,元数据文件,分别存在内存和磁盘上面。
HDFS磁盘上元数据分为两类,用于持久化存储:
fsimage镜像文件:是元数据的一个持久化的检查点,包含hadoop文件系统中所有的目录和文件元数据信息,但是不包含文件块位置的信息,文件块位置的信息只在内存中,由datanode启动时,namenode向其询问得到,并间断的进行更新。
edit编辑日志:存放的是hadoop文件系统中的左右更改操作(文件创建,删除或者修改),文件系统执行的更改操作都会先被记录到edit文件中。
fsimage和edit文件都是经过序列化的,在NameNode启动的时候,他会将fsimage文件中的内容加载到内存中,之后再执行edit文件中的各项操作,使得内存中的数据和实际的数据同步,存在内存中的元数据支持客户端的读操作,也是最完整的元数据。
当客户端进行更改操作时候,操作记录会先被记录到edit日志文件,当客户端操作成功后,相应的元数据被记录到内存元数据中,因为fsimage都会很大,如果都直接加载fsimage中,会使文件变得更大,从而系统运行缓慢。
2. 元数据目录相关文件
在Hadoop的hdfs首次配置好后并不能马上启动,先要对文件系统进行格式化。需要在NameNode节点上进行以下操作:


$HADOOP_HOME/bin/hdfs namenode –format
这里的文件系统在物理上还不存在,这里的格式化也不是传统意义上面的格式化,而是清除和准备的工作。
格式化完成之后,将会在$dfs.namenode.name.dir/current 目录下创建如下的文件结构。
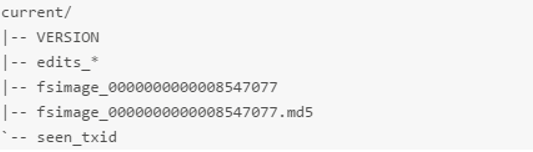
其中的 dfs.namenode.name.dir 是在 hdfs-site.xml 文件中配置的,默认值如下

dfs.namenode.name.dir 属性可以配置多个目录,各个目录存储的文件结构和内容都完全一样,相当于备份,这样做的好处是当其中一个目录损坏了,也不会影响到 Hadoop 的元数据,特别是当其中一个目录是 NFS(网络文件系统 Network File System,NFS)之上,即使你这台机器损坏了,元数据也得到保存。
2. second namenode
首先注意一点,second namenode不是作为name的备份节点,他的作用是辅助namenode管理元数据。
集群运行久了之后可能出现以下问题:
- edit log文件会变得非常大
- namenode重启会花很久,因为很多更改记录需要合并到fsimage上面。
- 如果namenode挂掉了,fsimage会很旧。
因此出现了second namenode它的作用是合并namenode的edit logs到fsimage中。
a. checkpoint
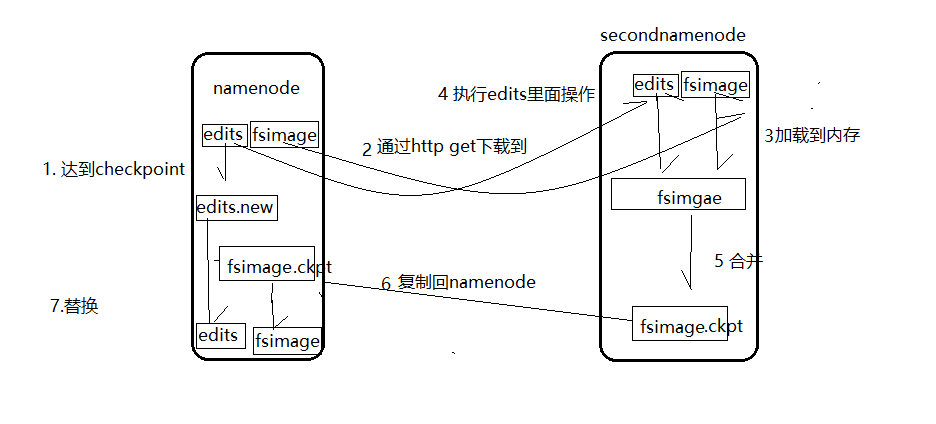
每到触发条件,secondname会将namenode最新的edit log和fsimage下载到本地,并加载到内存,在内存进行merge。这个过程称为checkpoint。
- NameNode管理着元数据,其中持久化着两种元数据,分别是edit log日志操作文件和fsimage元数据镜像文件,新的操作日志不会与fsimage合并,而是先写入edit log操作成功后会更新内存。
-
有 dfs.namenode.checkpoint.period 和 dfs.namenode.checkpoint.txns 两个配置,只要达到这两个条件任何一个,secondarynamenode 就会执行 checkpoint 的操作。
- 当触发checkpoint时,namenode会生成一个edits.new 文件,secondnamenode会将edits和fsimage复制到本地(http get方式)
- secondnamenode将下载的fsimage加载到内存然后一条一条执行edits中的操作,使得fsimage保持最新,这个过程就是fsimage和edits的合并,最后会生成一个新的fsimage.ckpt.
- secondnamenode将新的fsiamge.ckpt复制到namenode。
- 此时edits.new和fsimage会替换掉原来的文件。
 b. checkpoint触发条件
b. checkpoint触发条件
Checkpoint 操作受两个参数控制,可以通过 core-site.xml 进行配置: <property> <name> dfs.namenode.checkpoint.period</name> <value>3600</value> <description> 两次连续的 checkpoint 之间的时间间隔。默认 1 小时 </description> </property> <property> <name>dfs.namenode.checkpoint.txns</name> <value>1000000</value> <description> 最大的没有执行 checkpoint 事务的数量,满足将强制执行紧急 checkpoint,即使 尚未达到检查点周期。默认设置为 100 万。 </description> </property
3. 动态拓容,缩容
a. 拓容
- 修改hostname
- 修改host
- 设置免密登录
- 修改主节点slave文件
- 解压hadoop,把配置文件分发过来
- 添加datanode:在namenode的机器hadoop配置文件下简历dfs.hosts文件。在hdfs-sits中添加属性。表示允许连接到namenode的datanode列表。
- 负载均衡
- 添加nodemanager
b. 缩容
新建dfs.hosts.exlude写入主机名,在hdfs-site中添加属性
刷新集群
4. 安全模式
安全模式只能进行读操作,不能进行更改。namenode启动时会先进入安全模式,集群检查数据块的完整性,datanode启动时会像namenode汇报可用的block块信息,当达到标准时离开安全模式。假设我们设置副本数为5个现在只存在3个副本,3/5=0.6,在dfs-default中定义了一个最小副本率0.999,这时候datanode回复制到其他的datanode,使副本率不小于0.999,如果副本数多余5个,也会删除多余的副本。