基本步骤包括:
1.使用python+selenium分析dom结构爬取百度|互动百科文本摘要信息;
2.使用jieba结巴分词对文本进行中文分词,同时插入字典关于关键词;
3.scikit-learn对文本内容进行tfidf计算并构造N*M矩阵(N个文档 M个特征词);
4.再使用K-means进行文本聚类(省略特征词过来降维过程);
5.最后对聚类的结果进行简单的文本处理,按类簇归类,也可以计算P/R/F特征值;
6.总结这篇论文及K-means的缺点及知识图谱的一些内容。
当然这只是一篇最最基础的文章,更高深的分类、聚类、LDA、SVM、随机森林等内容,自己以后慢慢学习吧!这篇作为在线笔记,路漫漫其修远兮,fighting~
一. 爬虫实现
爬虫主要通过Python+Selenium+Phantomjs实现,爬取百度百科和互动百科旅游景点信息,其中爬取百度百科代码如下。
参考前文:[Python爬虫] Selenium获取百度百科旅游景点的InfoBox消息盒
实现原理:
首先从Tourist_spots_5A_BD.txt中读取景点信息,然后通过调用无界面浏览器PhantomJS(Firefox可替代)访问百度百科链接"http://baike.baidu.com/",通过Selenium获取输入对话框ID,输入关键词如"故宫",再访问该百科页面。最后通过分析DOM树结构获取摘要的ID并获取其值。核心代码如下:
driver.find_elements_by_xpath("//div[@class='lemma-summary']/div")
PS:Selenium更多应用于自动化测试,推荐Python爬虫使用scrapy等开源工具。
# coding=utf-8 """ Created on 2015-09-04 @author: Eastmount """ import time import re import os import sys import codecs import shutil from selenium import webdriver from selenium.webdriver.common.keys import Keys import selenium.webdriver.support.ui as ui from selenium.webdriver.common.action_chains import ActionChains #Open PhantomJS driver = webdriver.PhantomJS(executable_path="G:phantomjs-1.9.1-windowsphantomjs.exe") #driver = webdriver.Firefox() wait = ui.WebDriverWait(driver,10) #Get the Content of 5A tourist spots def getInfobox(entityName, fileName): try: #create paths and txt files print u'文件名称: ', fileName info = codecs.open(fileName, 'w', 'utf-8') #locate input notice: 1.visit url by unicode 2.write files #Error: Message: Element not found in the cache - # Perhaps the page has changed since it was looked up #解决方法: 使用Selenium和Phantomjs print u'实体名称: ', entityName.rstrip(' ') driver.get("http://baike.baidu.com/") elem_inp = driver.find_element_by_xpath("//form[@id='searchForm']/input") elem_inp.send_keys(entityName) elem_inp.send_keys(Keys.RETURN) info.write(entityName.rstrip(' ')+' ') #codecs不支持' '换行 time.sleep(2) #load content 摘要 elem_value = driver.find_elements_by_xpath("//div[@class='lemma-summary']/div") for value in elem_value: print value.text info.writelines(value.text + ' ') time.sleep(2) except Exception,e: #'utf8' codec can't decode byte print "Error: ",e finally: print ' ' info.close() #Main function def main(): #By function get information path = "BaiduSpider\" if os.path.isdir(path): shutil.rmtree(path, True) os.makedirs(path) source = open("Tourist_spots_5A_BD.txt", 'r') num = 1 for entityName in source: entityName = unicode(entityName, "utf-8") if u'故宫' in entityName: #else add a '?' entityName = u'北京故宫' name = "%04d" % num fileName = path + str(name) + ".txt" getInfobox(entityName, fileName) num = num + 1 print 'End Read Files!' source.close() driver.close() if __name__ == '__main__': main()
运行结果如下图所示:
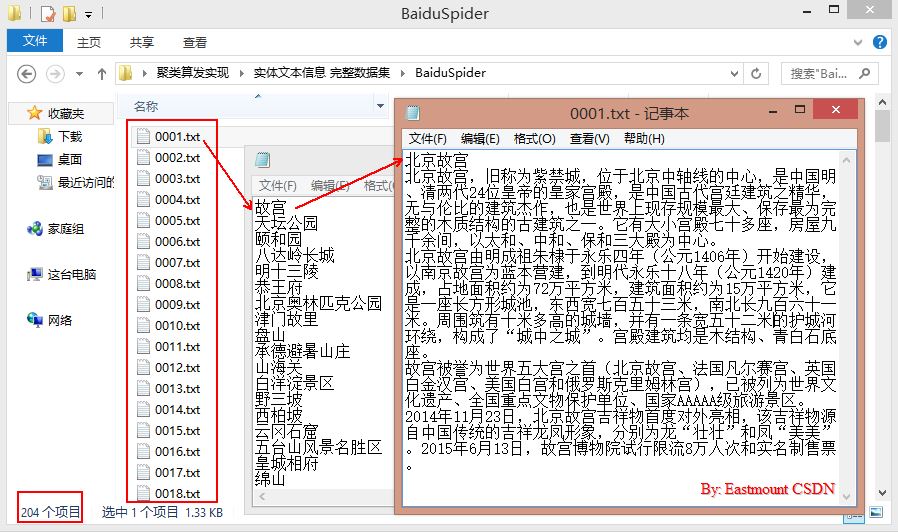
二. 中文分词
中文分词主要使用的是Python+Jieba分词工具,同时导入自定义词典dict_baidu.txt,里面主要是一些专业景点名词,如"黔清宫"分词"黔/清宫",如果词典中存在专有名词"乾清宫"就会先查找词典。
结巴中文分词涉及到的算法包括:
(1) 基于Trie树结构实现高效的词图扫描,生成句子中汉字所有可能成词情况所构成的有向无环图(DAG);
(2) 采用了动态规划查找最大概率路径, 找出基于词频的最大切分组合;
(3) 对于未登录词,采用了基于汉字成词能力的HMM模型,使用了Viterbi算法。
结巴中文分词支持的三种分词模式包括:
(1) 精确模式:试图将句子最精确地切开,适合文本分析;
(2) 全模式:把句子中所有的可以成词的词语都扫描出来, 速度非常快,但是不能解决歧义问题;
(3) 搜索引擎模式:在精确模式的基础上,对长词再次切分,提高召回率,适合用于搜索引擎分词。
同时结巴分词支持繁体分词和自定义字典方法。
参考前文:[python] 使用Jieba工具中文分词及文本聚类概念
#encoding=utf-8 import sys import re import codecs import os import shutil import jieba import jieba.analyse #导入自定义词典 jieba.load_userdict("dict_baidu.txt") #Read file and cut def read_file_cut(): #create path path = "BaiduSpider\" respath = "BaiduSpider_Result\" if os.path.isdir(respath): shutil.rmtree(respath, True) os.makedirs(respath) num = 1 while num<=204: name = "%04d" % num fileName = path + str(name) + ".txt" resName = respath + str(name) + ".txt" source = open(fileName, 'r') if os.path.exists(resName): os.remove(resName) result = codecs.open(resName, 'w', 'utf-8') line = source.readline() line = line.rstrip(' ') while line!="": line = unicode(line, "utf-8") seglist = jieba.cut(line,cut_all=False) #精确模式 output = ' '.join(list(seglist)) #空格拼接 print output result.write(output + ' ') line = source.readline() else: print 'End file: ' + str(num) source.close() result.close() num = num + 1 else: print 'End All' #Run function if __name__ == '__main__': read_file_cut()
按照Jieba精确模式分词且空格拼接,"0003.txt 颐和园"分词结果如下图所示:
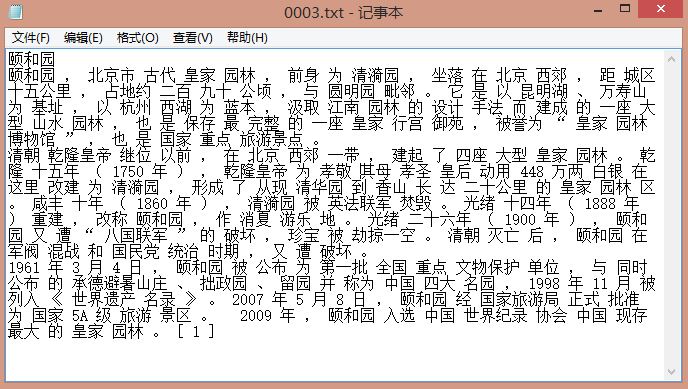
为方便后面的计算或对接一些sklearn或w2v等工具,下面这段代码将结果存储在同一个txt中,每行表示一个景点的分词结果。
# coding=utf-8 import re import os import sys import codecs import shutil def merge_file(): path = "BaiduSpider_Result\" resName = "BaiduSpider_Result.txt" if os.path.exists(resName): os.remove(resName) result = codecs.open(resName, 'w', 'utf-8') num = 1 while num <= 204: name = "%04d" % num fileName = path + str(name) + ".txt" source = open(fileName, 'r') line = source.readline() line = line.strip(' ') line = line.strip(' ') while line!="": line = unicode(line, "utf-8") line = line.replace(' ',' ') line = line.replace(' ',' ') result.write(line+ ' ') line = source.readline() else: print 'End file: ' + str(num) result.write(' ') source.close() num = num + 1 else: print 'End All' result.close() if __name__ == '__main__': merge_file()
每行一个景点的分词结果,运行结果如下图所示:
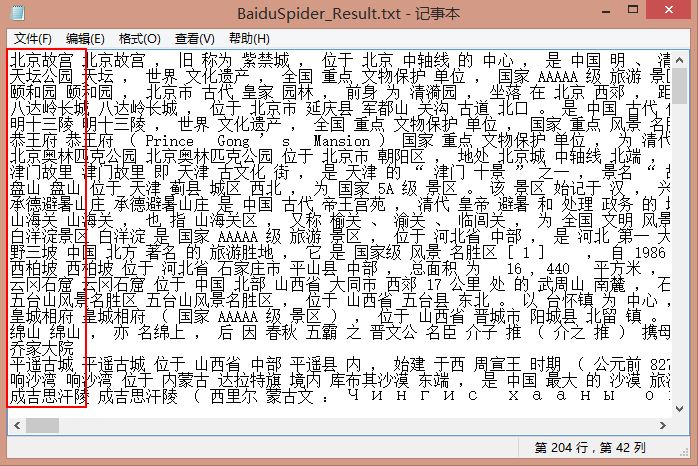
三. 计算TF-IDF
此时,需要将文档相似度问题转换为数学向量矩阵问题,可以通过VSM向量空间模型来存储每个文档的词频和权重,特征抽取完后,因为每个词语对实体的贡献度不同,所以需要对这些词语赋予不同的权重。计算词项在向量中的权重方法——TF-IDF。
相关介绍:
它表示TF(词频)和IDF(倒文档频率)的乘积:
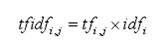
其中TF表示某个关键词出现的频率,IDF为所有文档的数目除以包含该词语的文档数目的对数值。
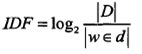
|D|表示所有文档的数目,|w∈d|表示包含词语w的文档数目。
最后TF-IDF计算权重越大表示该词条对这个文本的重要性越大,它的目的是去除一些"的、了、等"出现频率较高的常用词。
参考前文:Python简单实现基于VSM的余弦相似度计算
基于VSM的命名实体识别、歧义消解和指代消解
下面是使用scikit-learn工具调用CountVectorizer()和TfidfTransformer()函数计算TF-IDF值,同时后面"四.K-means聚类"代码也包含了这部分,该部分代码先提出来介绍。
# coding=utf-8 """ Created on 2015-12-30 @author: Eastmount """ import time import re import os import sys import codecs import shutil from sklearn import feature_extraction from sklearn.feature_extraction.text import TfidfTransformer from sklearn.feature_extraction.text import CountVectorizer ''' sklearn里面的TF-IDF主要用到了两个函数:CountVectorizer()和TfidfTransformer()。 CountVectorizer是通过fit_transform函数将文本中的词语转换为词频矩阵。 矩阵元素weight[i][j] 表示j词在第i个文本下的词频,即各个词语出现的次数。 通过get_feature_names()可看到所有文本的关键字,通过toarray()可看到词频矩阵的结果。 TfidfTransformer也有个fit_transform函数,它的作用是计算tf-idf值。 ''' if __name__ == "__main__": corpus = [] #文档预料 空格连接 #读取预料 一行预料为一个文档 for line in open('BaiduSpider_Result.txt', 'r').readlines(): print line corpus.append(line.strip()) #print corpus time.sleep(5) #将文本中的词语转换为词频矩阵 矩阵元素a[i][j] 表示j词在i类文本下的词频 vectorizer = CountVectorizer() #该类会统计每个词语的tf-idf权值 transformer = TfidfTransformer() #第一个fit_transform是计算tf-idf 第二个fit_transform是将文本转为词频矩阵 tfidf = transformer.fit_transform(vectorizer.fit_transform(corpus)) #获取词袋模型中的所有词语 word = vectorizer.get_feature_names() #将tf-idf矩阵抽取出来,元素w[i][j]表示j词在i类文本中的tf-idf权重 weight = tfidf.toarray() resName = "BaiduTfidf_Result.txt" result = codecs.open(resName, 'w', 'utf-8') for j in range(len(word)): result.write(word[j] + ' ') result.write(' ') #打印每类文本的tf-idf词语权重,第一个for遍历所有文本,第二个for便利某一类文本下的词语权重 for i in range(len(weight)): print u"-------这里输出第",i,u"类文本的词语tf-idf权重------" for j in range(len(word)): result.write(str(weight[i][j]) + ' ') result.write(' ') result.close()
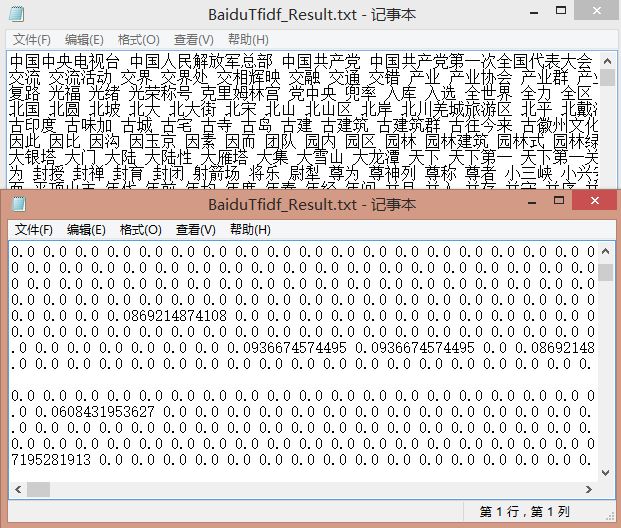
其中输出如下所示,由于文本摘要不多,总共8368维特征,其中共400个景点(百度百科200 互动百科200)文本摘要,故构建的矩阵就是[400][8368],其中每个景点都有对应的矩阵存储TF-IDF值。
缺点:可以尝试出去一些停用词、数字等,同时可以如果文档维数过多,可以设置固定的维度,同时进行一些降维操作或构建稀疏矩阵,大家可以自己去研究下。
推荐一些优秀的关于Sklearn工具TF-IDF的文章:
python scikit-learn计算tf-idf词语权重 - liuxuejiang158
用Python开始机器学习(5:文本特征抽取与向量化) - lsldd大神
官方scikit-learn文档 4.3. Preprocessing data
四. K-means聚类
其中K-means聚类算法代码如下所示,主要是调用sklearn.cluster实现。
强推一些机器学习大神关于Scikit-learn工具的分类聚类文章,非常优秀:
用Python开始机器学习(10:聚类算法之K均值) -lsldd大神
应用scikit-learn做文本分类(特征提取 KNN SVM 聚类) - Rachel-Zhang大神
Scikit Learn: 在python中机器学习(KNN SVMs K均) - yyliu大神 开源中国
【机器学习实验】scikit-learn的主要模块和基本使用 - JasonDing大神
Scikit-learn学习笔记 中文简介(P30-Cluster) - 百度文库
使用sklearn做kmeans聚类分析 - xiaolitnt
使用sklearn + jieba中文分词构建文本分类器 - MANYU GOU大神
sklearn学习(1) 数据集(官方数据集使用) - yuanyu5237大神
scikit-learn使用笔记与sign prediction简单小结 - xupeizhi
http://scikit-learn.org/stable/modules/clustering.html#clustering
代码如下:
# coding=utf-8 """ Created on 2016-01-06 @author: Eastmount """ import time import re import os import sys import codecs import shutil import numpy as np from sklearn import feature_extraction from sklearn.feature_extraction.text import TfidfTransformer from sklearn.feature_extraction.text import CountVectorizer if __name__ == "__main__": ######################################################################### # 第一步 计算TFIDF #文档预料 空格连接 corpus = [] #读取预料 一行预料为一个文档 for line in open('BHSpider_Result.txt', 'r').readlines(): print line corpus.append(line.strip()) #print corpus #time.sleep(1) #将文本中的词语转换为词频矩阵 矩阵元素a[i][j] 表示j词在i类文本下的词频 vectorizer = CountVectorizer() #该类会统计每个词语的tf-idf权值 transformer = TfidfTransformer() #第一个fit_transform是计算tf-idf 第二个fit_transform是将文本转为词频矩阵 tfidf = transformer.fit_transform(vectorizer.fit_transform(corpus)) #获取词袋模型中的所有词语 word = vectorizer.get_feature_names() #将tf-idf矩阵抽取出来,元素w[i][j]表示j词在i类文本中的tf-idf权重 weight = tfidf.toarray() #打印特征向量文本内容 print 'Features length: ' + str(len(word)) resName = "BHTfidf_Result.txt" result = codecs.open(resName, 'w', 'utf-8') for j in range(len(word)): result.write(word[j] + ' ') result.write(' ') #打印每类文本的tf-idf词语权重,第一个for遍历所有文本,第二个for便利某一类文本下的词语权重 for i in range(len(weight)): print u"-------这里输出第",i,u"类文本的词语tf-idf权重------" for j in range(len(word)): #print weight[i][j], result.write(str(weight[i][j]) + ' ') result.write(' ') result.close() ######################################################################## # 第二步 聚类Kmeans print 'Start Kmeans:' from sklearn.cluster import KMeans clf = KMeans(n_clusters=20) s = clf.fit(weight) print s #20个中心点 print(clf.cluster_centers_) #每个样本所属的簇 print(clf.labels_) i = 1 while i <= len(clf.labels_): print i, clf.labels_[i-1] i = i + 1 #用来评估簇的个数是否合适,距离越小说明簇分的越好,选取临界点的簇个数 print(clf.inertia_)
输出如下图所示,20个类簇中心点和408个簇,对应408个景点,每个文档对应聚在相应的类0~19。

五. 结果处理
为了更直观的显示结果,通过下面的程序对景点进行简单结果处理。
# coding=utf-8 import os import sys import codecs ''' @2016-01-07 By Eastmount 功能:合并实体名称和聚类结果 共类簇20类 输入:BH_EntityName.txt Cluster_Result.txt 输出:ZBH_Cluster_Merge.txt ZBH_Cluster_Result.txt ''' source1 = open("BH_EntityName.txt",'r') source2 = open("Cluster_Result.txt",'r') result1 = codecs.open("ZBH_Cluster_Result.txt", 'w', 'utf-8') ######################################################################### # 第一部分 合并实体名称和类簇 lable = [] #存储408个类标 20个类 content = [] #存储408个实体名称 name = source1.readline() #总是多输出空格 故设置0 1使其输出一致 num = 1 while name!="": name = unicode(name.strip(' '), "utf-8") if num == 1: res = source2.readline() res = res.strip(' ') value = res.split(' ') no = int(value[0]) - 1 #行号 va = int(value[1]) #值 lable.append(va) content.append(name) print name, res result1.write(name + ' ' + res + ' ') num = 0 elif num == 0: num = 1 name = source1.readline() else: print 'OK' source1.close() source2.close() result1.close() #测试输出 其中实体名称和类标一一对应 i = 0 while i < len(lable): print content[i], (i+1), lable[i] i = i + 1 ######################################################################### # 第二部分 合并类簇 类1 ..... 类2 ..... #定义定长20字符串数组 对应20个类簇 output = ['']*20 result2 = codecs.open("ZBH_Cluster_Merge.txt", 'w', 'utf-8') #统计类标对应的实体名称 i = 0 while i < len(lable): output[lable[i]] += content[i] + ' ' i = i + 1 #输出 i = 0 while i < 20: print '#######' result2.write('####### ') print 'Label: ' + str(i) result2.write('Label: ' + str(i) + ' ') print output[i] result2.write(output[i] + ' ') i = i + 1 result2.close()
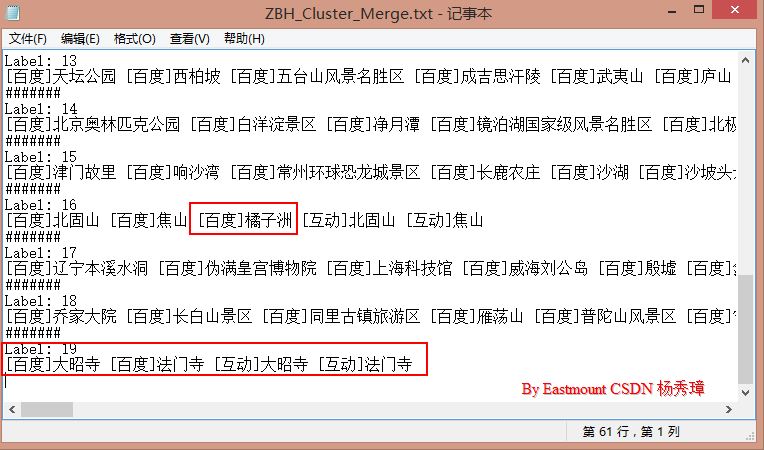
输出结果如下图所示,其中label19可以发现百度百科和互动百科的"大昭寺、法门寺"文本内容都划分为一类,同时也会存在一些错误的类别,如Label15中的"橘子洲"。
PS:如果你想进行准确率、回归率、F特征值比较,可以进一步去学习sklearn官方文档。通常的文本数据集的类标如"教育、体育、娱乐",把不同内容的新闻聚在一类,而这个略有区别,它主要是应用于我实际的毕设。
六. 总结与不足
Kmeans聚类是一种自下而上的聚类方法,它的优点是简单、速度快;缺点是聚类结果与初始中心的选择有关系,且必须提供聚类的数目。
Kmeans的第二个缺点是致命的,因为在有些时候,我们不知道样本集将要聚成多少个类别,这种时候kmeans是不适合的,推荐使用hierarchical 或meanshift来聚类。第一个缺点可以通过多次聚类取最佳结果来解决。
推荐一些关于Kmeans及实验评估的文章:
浅谈Kmeans聚类 - easymind223
基于K-Means的文本聚类(强推基础介绍) - freesum
基于向量空间模型的文本聚类算法 - helld123
KMeans文档聚类python实现(代码详解) - skineffect
Kmeans文本聚类系列之全部C++代码 - finallyliuyu
文本聚类—kmeans - zengkui111