一、为什么选择kettle
在将excel中的数据上传到SQL数据库,现在常用的自动化是写python代码,可以查看:https://www.cnblogs.com/qianslup/p/12567284.html
或者手动插入到数据库中。
使用python代码,缺点有:
- 需要掌握pyhton,对于大量不同表格表格上传数据库,维护起来则显得极其繁琐;
- 同时、对字段的连接,拼接等操作需要写代码。
而使用kettle则可以解决python的两个缺点;即使没有编程基础的人,也可以通过图标、拖拽等操作完成这些操作;并可以定时、发送邮件等操作。
如果固有的功能无法满足,也可以书写java脚本,自定义操作。总之、在将Excel上传到数据库,或将Excel的字段简单处理之后上传到数据库;kettle的友善度远高于python。
二、常用操作
会对一些操作谈一些自己的看法与重要性(满分5星)和其他操作的对比,主要这里的评分只代表自己在工作中的看法,换一个工作场景的评分重要性可能会有颠倒性改变,
其他操作的对比主要有SQL语句,Excel、Power Query等。
2.1 常规操作
就以下表中的一些操作简单的说明下。
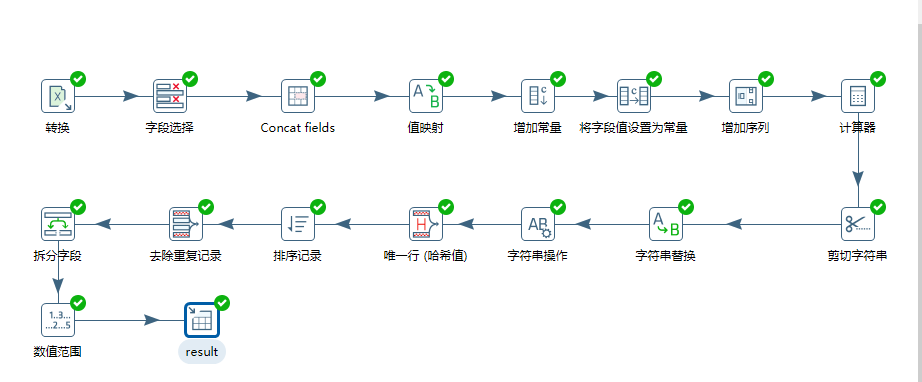
2.2 步骤说明
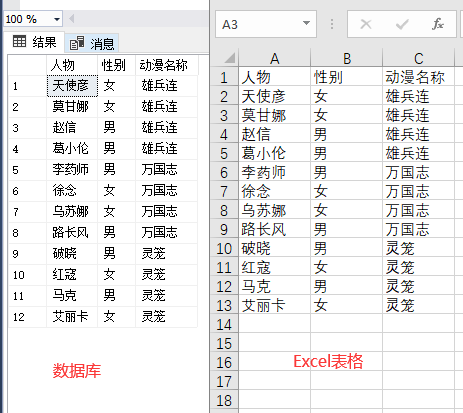
2.2.1 Excel底层数据
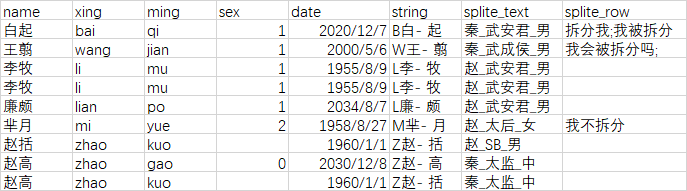
2.2.2 字段选择
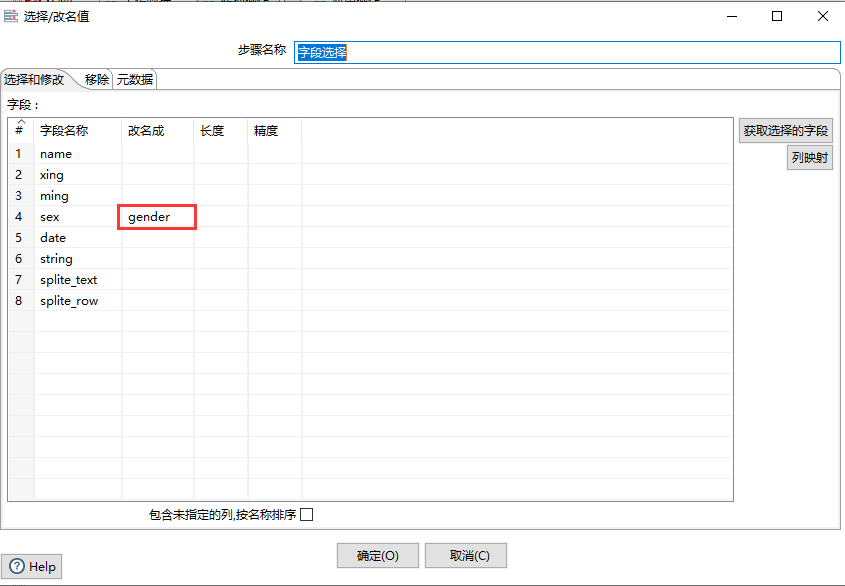
选择或者移除字段里的字;可以设置字段的元数据:类型、长度、精度
重要性:2星。
可代替性较高,如果只是改名与移除字段;这一步操作可以在最后一步上传数据库时被代替。长度与精度基本上使用不到。
对应SQL语句
select name,xing,ming,sex as 'gender',[date],string,splite_text,splite_row into #字段选择 from test.kettle.转换
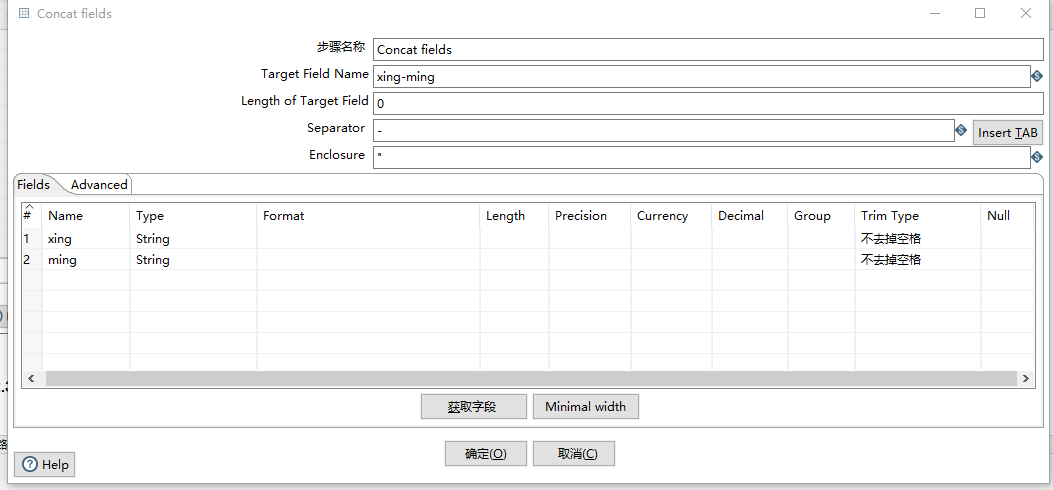
2.2.3 Concat fields
将字段进行拼接并且生成一个新字段
重要性:3星
对应SQL语句
select name,xing,ming,gender,[date],string,splite_text,splite_row, concat(xing,'-',ming) as 'xing-ming' into #concat_fields from #字段选择
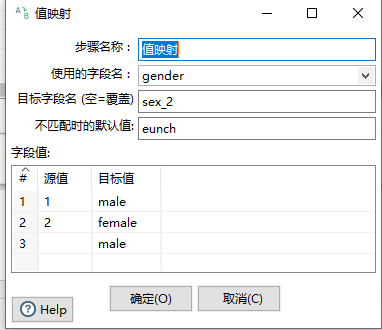
2.2.4 值映射
将字段的值映射为为另外的值
重要性:3星
对应SQL语句
select name,xing,ming,gender,[date],string,splite_text,splite_row,[xing-ming], CASE WHEN gender='1' THEN 'male' WHEN gender='2' THEN 'female' WHEN gender is null then 'male' else 'eunch' end as 'sex_2' into #值映射 from #concat_fields
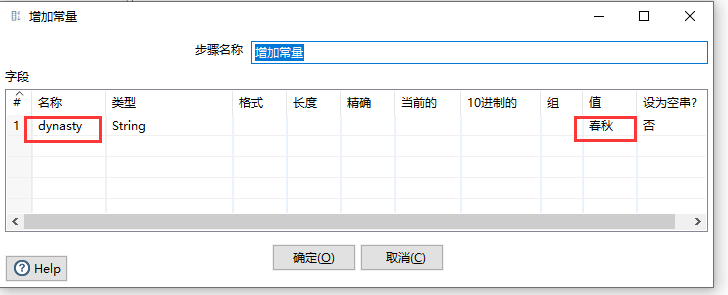
2.2.5 增加常量
给记录增加一个或多个常量
重要性:2星
对应SQL语句
select *,'春秋' AS 'dynasty' into #增加常量 from #值映射
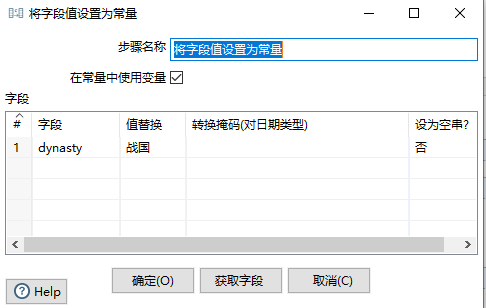
2.2.6 将字段设置为常量
重要性:1 星
对应SQL 语句
select name,xing,ming,gender,[date],string,splite_text,splite_row,[xing-ming], '战国' AS 'dynasty' into #将字段值设置为常量 from #增加常量
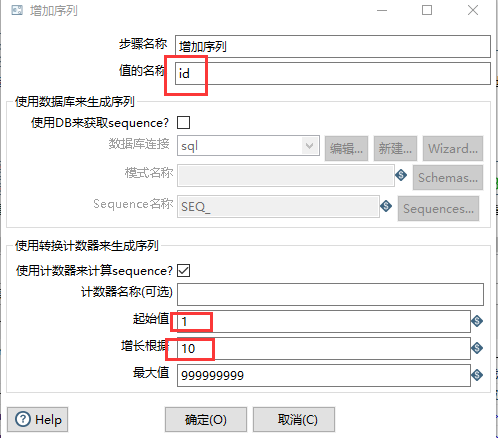
2.2.7 增加序列
重要性:3 星
对应SQL 语句
Alter Table #增加常量 Add id Int Identity(1, 10) ; select * into #增加序列 from #增加常量
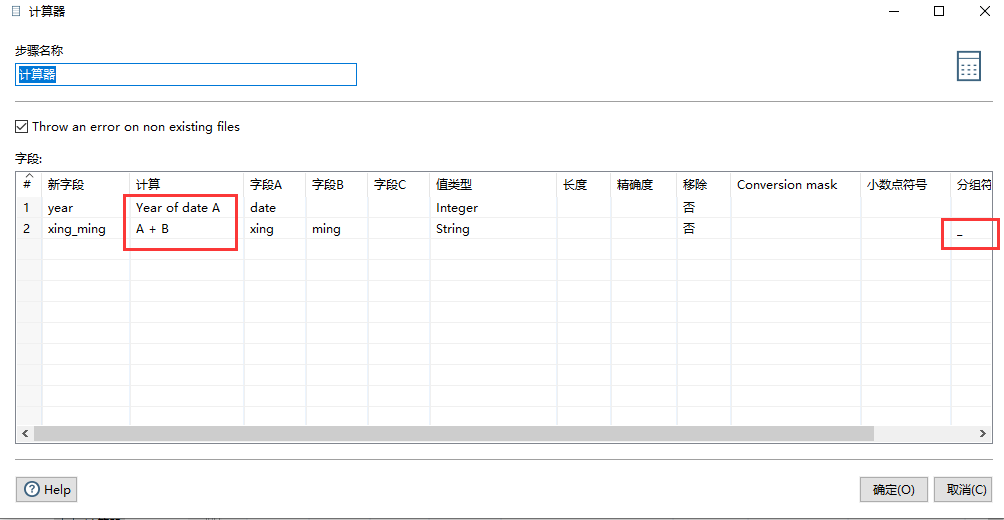
2.2.8 计算器
通过执行简单的计算创建一个新字段
重要性:3 星
对应SQL 语句
select *,year([date]) as 'year',concat(xing,'_',ming) as 'xing_ming' into #计算器 from #增加序列
注意度字段处理了,可部分替代Concat fields。
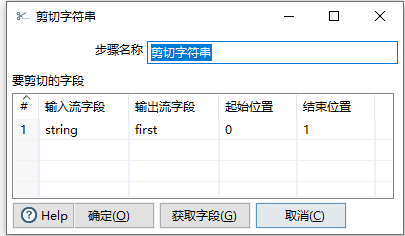
2.2.9 剪切字符串
通过执行简单的计算创建一个新字段
重要性:3星
对应SQL 语句
select *,left([string],1) as [first] into #剪切字符串 from #计算器
2.2.10 字符串替换
将某个字符串替换为其他的字符串
重要性:4星
这个步骤的重要性高的原因是人为原因,总有一些人在填写数据时喜欢用空格代替空值,需要将空格剔除掉。
对应SQL 语句
select *,REPLACE(string, ' ', '') as no_blank into #字符串替换 from #剪切字符串

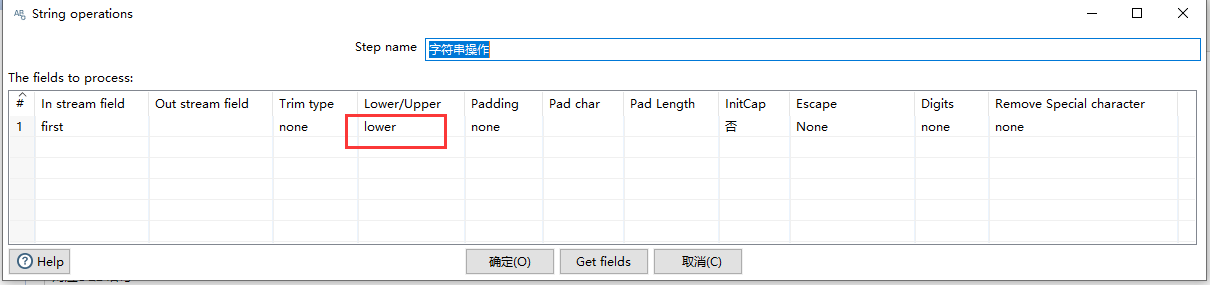
2.2.11 字符串操作
重要性:3星
对应SQL 语句
select * into #字符串操作 from #字符串替换 ; update #字符串操作 set [first] = LOWER([first]);
可以进行多种操作,我这只演示转化为小写。
2.2.12 唯一行 (哈希值)
删除数据流重复的行
相当于排序记录+去除重复记录,但是实现原理不同。
唯一行(哈希值)执行效率更高
重要性:4星
对应SQL 语句,使用开窗函数相对简单一点。
SELECT name,xing,ming,gender,[date],string,splite_text,splite_row,[xing-ming],sex_2,dynasty,id,[year],xing_ming,[first],no_blank into #唯一行_哈希值 from ( select name,xing,ming,gender,[date],string,splite_text,splite_row,[xing-ming],sex_2,dynasty,id,[year],xing_ming,[first],no_blank, row_number() OVER (PARTITION BY name,xing,ming,gender,[date],string,[xing-ming],sex_2,dynasty,[year],xing_ming,[first],no_blank ORDER BY [id]) as 'id排序' from #字符串操作 ) as a where id排序 = 1

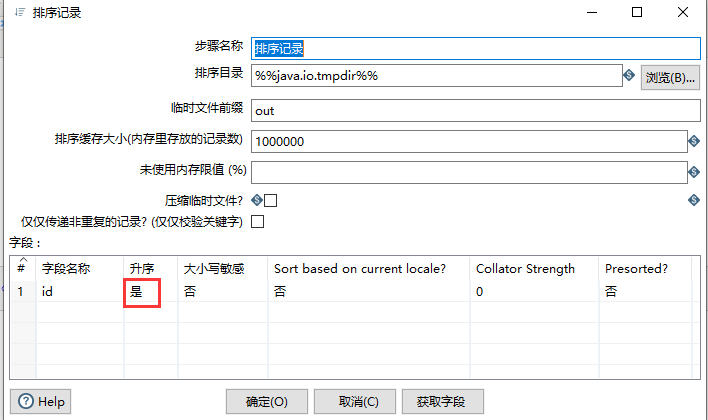
2.2.13 排序记录
基于字段值,对值进行排序
一般和其他操作的预处理步骤
重要性:2星
对应SQL 语句
SELECT * from #唯一行_哈希值 order by id
2.2.14 去除重复记录
删除数据流重复的行,前提是排好序,否则只删除连续的重复行。
重要性:4星
对应SQL 语句,使用开窗函数相对简单一点。
SELECT name,xing,ming,gender,[date],string,splite_text,splite_row,[xing-ming],sex_2,dynasty,id,[year],xing_ming,[first],no_blank into #去除重复行 from ( select name,xing,ming,gender,[date],string,splite_text,splite_row,[xing-ming],sex_2,dynasty,id,[year],xing_ming,[first],no_blank, row_number() OVER (PARTITION BY name ORDER BY [id]) as 'id排序' from #唯一行_哈希值 ) as a where id排序 = 1
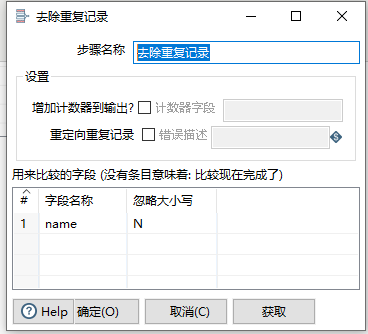
2.2.15 拆分字段
按照分隔符将字段进行拆分
重要性:5星
打5星全靠同行衬托,SQL语句中没有根据某个字符串进行划分,如果想实现这个目的,需要自定义函数。非常的不友好。
自定义可以参考:https://www.cnblogs.com/qianslup/p/14232972.html
对应SQL 语句:
select *, qiansl.splitl(splite_text,'_',1) as 'test_1', qiansl.splitl(splite_text,'_',2) as 'test_2', qiansl.splitl(splite_text,'_',3) as 'test_3' from #去除重复行
对应的Excel操作:
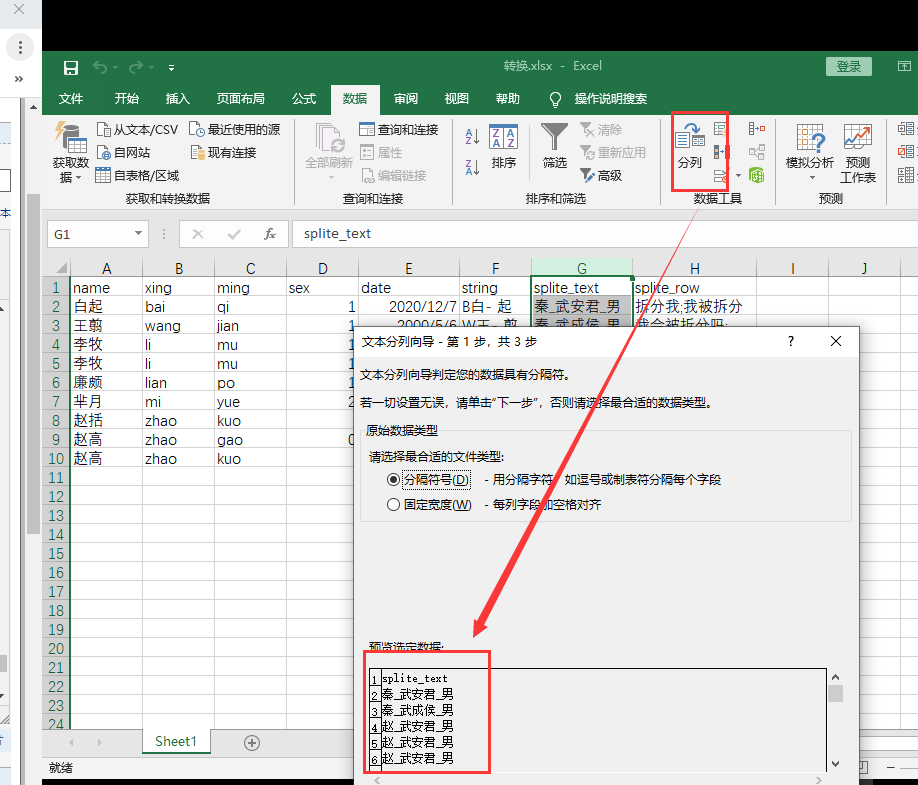
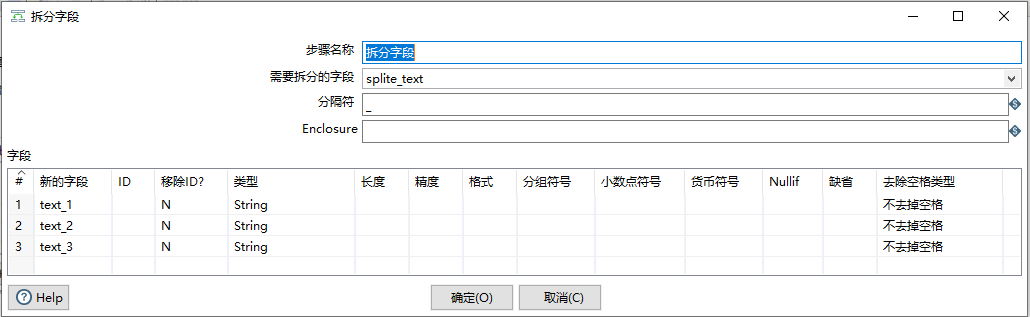
2.2.16 数值范围
重要性:3星
对应SQL 语句,使用开窗函数相对简单一点。
select *, case when [year] <2000 then '2000年以前' when [year]>= 2000 and [year]< 2020 THEN '2000-2020' WHEN [year] >= 2020 THEN '2020年以后' else 'unkonwn' end as '时间段' INTO #数值范围 from #拆分字段
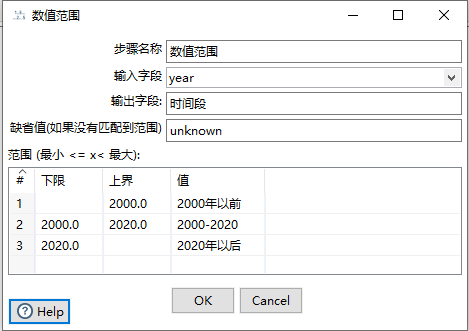
2.2.17 数值范围
重要性:5星
对应SQL 语句;从这一步一样可以起别名,剔除不要的字段。可部分替代“字段选择”
SELECT name,xing,ming,gender as 'sex',[date],string,splite_text,splite_row,[xing-ming],sex_2,dynasty,id,[year],xing_ming,[first],no_blank,text_1,text_2,text_3,[时间段] into result from #数值范围

三、行列转化
行专列、列转行这个操作最好能够知道,kettle里面可以操作,感觉用到的场景不多,所以就不多做介绍。
涉及到的步骤有:行转列、列转行、行扁平化、列拆分为多行
其他可以实现行列转化的有SQL Server:https://www.cnblogs.com/qianslup/p/11001064.html 拉到最后可以看到。
Powert Query: https://www.cnblogs.com/qianslup/p/12397365.html
Hive好像也有类似功能,没有研究过;MY SQL 没有专门的语句,强行写也可以写出来。
四、常用流控制
从多个数据源读取数据,筛选之后上传到数据库,并留下Excel底本。
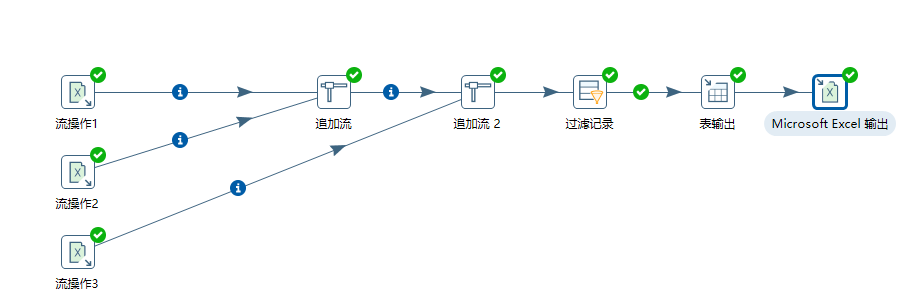
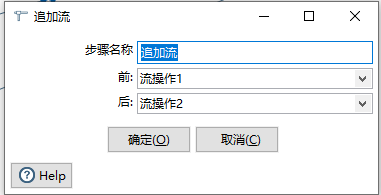
4.1 追加流
将有且仅有两个数据源合并为一个数据源;如果有3个数据源需要合并2次,有n(n>=2)个数据源,需要合并n-1次。
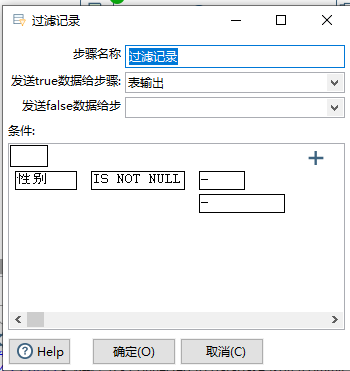
4.2 过滤记录
流进行筛选过滤操作,语句接近SQL语句
4.3 输出
表输出之后又连了Microsoft Excel 输出;两个输出的内容相同。

4.4 结果展示