参考:https://www.cnblogs.com/liangmingshen/p/9706181.html
参考:https://blog.csdn.net/mieleizhi0522/article/details/82142856
一、定义:
生成器:在Python中,一边循环一边计算的机制,称为生成器:generator。
生成器是一个特殊的程序,可以被用作控制循环的迭代行为,python中生成器是迭代器的一种,使用yield返回值函数,每次调用yield会暂停,而可以使用next()函数和send()函数恢复生成器。
生成器类似于返回值为数组的一个函数,这个函数可以接受参数,可以被调用,但是,不同于一般的函数会一次性返回包括了所有数值的数组,生成器一次只能产生一个值,这样消耗的内存数量将大大减小,而且允许调用函数可以很快的处理前几个返回值,
因此生成器看起来像是一个函数,但是表现得却像是迭代器。
yiled:如果你还没有对yield有个初步分认识,那么你先把yield看做“return”,这个是直观的,它首先是个return,普通的return是什么意思,就是在程序中返回某个值,返回之后程序就不再往下运行了。
看做return之后再把它看做一个是生成器(generator)的一部分(带yield的函数才是真正的迭代器)
二 、 为什么要有生成器
列表所有数据都在内存中,如果有海量数据的话将会非常耗内存。
如:仅仅需要访问前面几个元素,那后面绝大多数元素占用的空间都白白浪费了。
如果列表元素按照某种算法推算出来,那我们就可以在循环的过程中不断推算出后续的元素,这样就不必创建完整的list,从而节省大量的空间。
简单一句话:我又想要得到庞大的数据,又想让它占用空间少,那就用生成器!
三、创建生成器
3.1 通过()创建
第一种方法很简单,只要把一个列表生成式的[]改成(),就创建了一个generator:
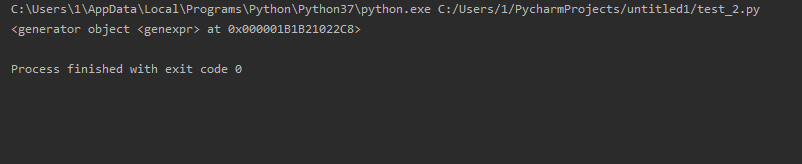
g = (x * x for x in range(5)) print(g)
3.2 通过yiled
如果一个函数中包含yield关键字,那么这个函数就不再是一个普通函数,而是一个generator。调用函数就是创建了一个生成器(generator)对象。
四、生成器的工作原理
4.1 基本概念
4.1.1 生成器(generator)能够迭代的关键是它有一个next()方法,
工作原理就是通过重复调用next()方法,直到捕获一个异常。
4.1.2 带有 yield 的函数不再是一个普通函数,而是一个生成器generator。
可用next()调用生成器对象来取值。next 两种方式 t.__next__() | next(t)。
可用for 循环获取返回值(每执行一次,取生成器里面一个值)
(基本上不会用next()来获取下一个返回值,而是直接使用for循环来迭代)。
4.1.3 yield相当于 return 返回一个值,并且记住这个返回的位置,下次迭代时,代码从yield的下一条语句开始执行。
4.1.4 send() 和next()一样,都能让生成器继续往下走一步(下次遇到yield停),但send()能传一个值,这个值作为yield表达式整体的结果
4.2 代码说明
4.2.1 next与for循环
generator = (x*x for x in range(5)) # 到第6个next才会出错。出错则停止 print(next(generator)) print(next(generator)) print(next(generator)) print(next(generator)) print(next(generator)) print(next(generator))

注意:重复调用next()方法,直到捕获一个异常。但是在用for来调用时,出现异常不会显示。
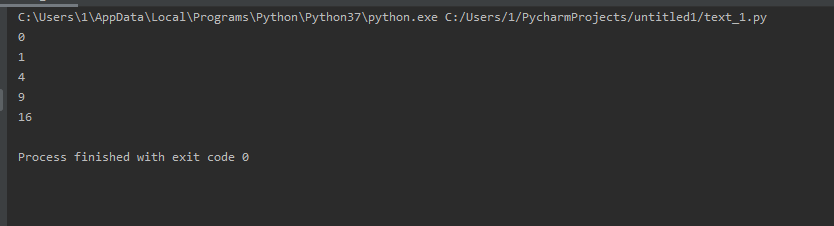
generator_ex = (x*x for x in range(5)) for i in generator_ex: print(i)
for 循环不出错的原因
# 首先获得Iterator对象: it = iter([1, 2, 3, 4, 5]) # 循环: while True: try: # 获得下一个值: x = next(it) except StopIteration: # 遇到StopIteration就退出循环 break
和下面的等价
for x in [1, 2, 3, 4, 5]: pass
4.2.2 yield函数
def foo(): print("starting...") while True: res = yield 4 print("res:",res) g = foo() print(next(g)) print("*"*20) print(next(g)) print(g.send(7))

代码说明:
先大致说一下send函数的概念:还有上面那个res的值为什么是None,这个变成了7,到底为什么,这是因为,
send是发送一个参数给res的,
return的时候,并没有把4赋值给res,下次执行的时候只好继续执行赋值操作,只好赋值为None了,
而如果用send的话,开始执行的时候,先接着上一次(return 4之后)执行,先把7赋值给了res,然后执行next的作用,遇见下一回的yield,return出结果后结束。
执行顺序:
1.程序开始执行以后,因为foo函数中有yield关键字,所以foo函数并不会真的执行,而是先得到一个生成器g(相当于一个对象)
2.直到调用next方法,foo函数正式开始执行,先执行foo函数中的print方法,然后进入while循环
3.程序遇到yield关键字,然后把yield想想成return,return了一个4之后,程序停止,并没有执行赋值给res操作,此时next(g)语句执行完成,所以输出的前两行(第一个是while上面的print的结果,第二个是return出的结果)是执行print(next(g))的结果,
4.程序执行print("*"*20),输出20个*
5.又开始执行下面的print(next(g)),这个时候和上面那个差不多,不过不同的是,这个时候是从刚才那个next程序停止的地方开始执行的,也就是要执行res的赋值操作,这时候要注意,这个时候赋值操作的右边是没有值的(因为刚才那个是return出去了,
并没有给赋值操作的左边传参数),所以这个时候res赋值是None,所以接着下面的输出就是res:None,
6.程序会继续在while里执行,又一次碰到yield,这个时候同样return 出4,然后程序停止,print函数输出的4就是这次return出的4。
7.用send的话,开始执行的时候,先接着上一次(return 4之后)执行,先把7赋值给了res,然后执行next的作用,遇见下一回的yield,return出结果后结束。
五、 判断生成器函数
我们已经知道,可以直接作用于for循环的数据类型有以下几种:
一类是集合数据类型,如list,tuple,dict,set,str等
一类是generator,包括生成器和带yield的generator function
这些可以直接作用于for 循环的对象统称为可迭代对象:Iterable
可以使用isinstance()判断一个对象是否为可Iterable对象
from collections import Iterable iter_1 = (isinstance([], Iterable)) and (isinstance([], Iterable)) and isinstance('abc', Iterable) and isinstance((x for x in range(10)), Iterable) print(iter_1)

所以这里讲一下迭代器
一个实现了iter方法的对象是可迭代的,一个实现next方法并且是可迭代的对象是迭代器。
可以被next()函数调用并不断返回下一个值的对象称为迭代器:Iterator。
所以一个实现了iter方法和next方法的对象就是迭代器。
生成器都是Iterator对象,但list、dict、str虽然是Iterable(可迭代对象),却不是Iterator(迭代器)
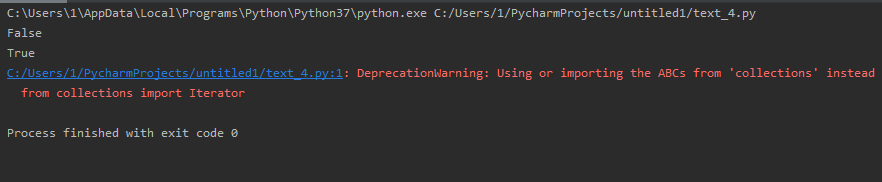
from collections import Iterator iter_1 = (isinstance([], Iterator)) or (isinstance([], Iterator)) or isinstance('abc', Iterator) print(iter_1) iter_2 = isinstance((x for x in range(10)), Iterator) print(iter_2)
把list、dict、str等Iterable变成Iterator可以使用iter()函数:

这是因为Python的Iterator对象表示的是一个数据流,Iterator对象可以被next()函数调用并不断返回下一个数据,直到没有数据时抛出StopIteration错误。可以把这个数据流看做是一个有序序列,但我们却不能提前知道序列的长度,只能不断通过next()函数实现按需计算下一个数据,所以Iterator的计算是惰性的,只有在需要返回下一个数据时它才会计算。
Iterator甚至可以表示一个无限大的数据流,例如全体自然数。而使用list是永远不可能存储全体自然数的。
小结:
- 凡是可作用于
for循环的对象都是Iterable类型; - 凡是可作用于
next()函数的对象都是Iterator类型,它们表示一个惰性计算的序列; - 集合数据类型如
list、dict、str等是Iterable但不是Iterator,不过可以通过iter()函数获得一个Iterator对象。
六、 考虑用生成器来改写直接返回列表的函数
如果函数要产生一些列结果,最简单的就是把结果放到列表里,并返回给调用者。
比如。我们要查出每个单词的首字母在句子中的位置。
# 使用列表 def index_word_list(text): result = [] if text: result.append(0) for index, letter in enumerate(text): if letter == " ": result.append(index+1) return result text = 'fore score and seven years ago...' result_list = index_word_list(text) print('result_list:',result_list) # 使用生成器 def index_words_iter(text): if text: yield 0 for index, letter in enumerate(text): if letter == " ": yield index + 1 text = 'fore score and seven years ago...' result_iter = list(index_words_iter(text)) print('result_iter:',result_iter)
使用生成器相比较于使用列表:
1.代码更清晰
2.占用更少的内存。如果输入量非常大,程序可能因为耗尽内存而崩溃;而输入量的大小,则不会影响执行时消耗的内存。
对yield的总结
(1)通常的for..in...循环中,in后面是一个数组,这个数组就是一个可迭代对象,类似的还有链表,字符串,文件。他可以是a = [1,2,3],也可以是a = [x*x for x in range(3)]。
它的缺点也很明显,就是所有数据都在内存里面,如果有海量的数据,将会非常耗内存。
(2)生成器是可以迭代的,但是只可以读取它一次。因为用的时候才生成,比如a = (x*x for x in range(3))。!!!!注意这里是小括号而不是方括号。
(3)生成器(generator)能够迭代的关键是他有next()方法,工作原理就是通过重复调用next()方法,直到捕获一个异常。
(4)带有yield的函数不再是一个普通的函数,而是一个生成器generator,可用于迭代
(5)yield是一个类似return 的关键字,迭代一次遇到yield的时候就返回yield后面或者右面的值。而且下一次迭代的时候,从上一次迭代遇到的yield后面的代码开始执行
(6)yield就是return返回的一个值,并且记住这个返回的位置。下一次迭代就从这个位置开始。
(7)带有yield的函数不仅仅是只用于for循环,而且可用于某个函数的参数,只要这个函数的参数也允许迭代参数。
(8)send()和next()的区别就在于send可传递参数给yield表达式,这时候传递的参数就会作为yield表达式的值,而yield的参数是返回给调用者的值,也就是说send可以强行修改上一个yield表达式值。
(9)send()和next()都有返回值,他们的返回值是当前迭代遇到的yield的时候,yield后面表达式的值,其实就是当前迭代yield后面的参数。
(10)第一次调用时候必须先next()或send(),否则会报错,send后之所以为None是因为这时候没有上一个yield,所以也可以认为next()等同于send(None)