SELECT
基本结构
--语句顺序 SELECT COLUNM_NAME --COLUNM_NAME 字段名 FROM TABLE_NAME --表名 WHERE --限制条件 GROUP BY --分组 HAVING --对分组后的结果进行筛选 ORDER BY --显示顺序,可以使用 select 中的别名 --执行顺序 -- FROM -- WHERE -- GROUP BY -- HAVING--SELECT -- ORDER BY --OEDER BY 执行顺序在 SELECT 之后,所以可以使用别名。
SELECT 子句
SELECT (ALL) * --查询所有字段,ALL可以不写,包含重复行。 select select_list --select_list:指定字段 SELECT DISTINCT * --查询所有字段,ALL可以不写,不包含重复字段。 SELECT TOP 10 * -- 返回前 10 个未定义的行,因为此时没有使用 ORDER BY 子句 SELECT PERCENT 10.1 * --前 10.1% 的行。 小数部分的值向上舍入到下一个整数值
GROUP BY 子句
此时select 字句中的字段要么是在group by中的字段、要么是聚合函数。
1.表格:
CREATE TABLE Sales ( Country varchar(50), Region varchar(50), Sales int ); INSERT INTO sales VALUES (N'Canada', N'Alberta', 100); INSERT INTO sales VALUES (N'Canada', N'British Columbia', 200); INSERT INTO sales VALUES (N'Canada', N'British Columbia', 300); INSERT INTO sales VALUES (N'United States', N'Montana', 100);
2.允许形式:
SELECT ColumnA, ColumnB FROM T GROUP BY ColumnA, ColumnB; SELECT ColumnA + ColumnB FROM T GROUP BY ColumnA, ColumnB; SELECT ColumnA + ColumnB FROM T GROUP BY ColumnA + ColumnB; SELECT ColumnA + ColumnB + constant FROM T GROUP BY ColumnA, ColumnB;
ROW_NUMBER() OVER(ORDER BY 字段1 DESC) as RN --是先把字段1降序,再为降序以后的每条记录返回一个序号 ROW_NUMBER() OVER (partition BY 字段1 ORDER BY 字段2) AS RN --表示根据字段1分组,在分组内部根据字段2排序,返回排序值
3.GROUP BY ROLLUP
为每个列表达式的组合创建一个组。 此外,它将结果“汇总”到小计和总计。 为此,它会从右向左减少创建的组和聚合的列表达式的数量。
例如,GROUP BY ROLLUP (col1, col2, col3, col4) 为以下列表中的每个列表达式组合创建组。
- col1、col2、col3、col4
- col1、col2、col3、NULL --col1、col2、col3的小计
- col1、col2、NULL、NULL --col1、col2的小计
- col1、NULL、NULL、NULL --col1的小计
- NULL、NULL、NULL、NULL - 这是总计
4.GROUP BY CUBE
GROUP BY CUBE 为所有可能的列组合创建组。 对于 GROUP BY CUBE (a, b),结果具有 (a, b)、(NULL, b)、(a, NULL) 和 (NULL, NULL) 唯一值的组
5.GROUP BY GROUPING SETS()
GROUPING SETS 选项可将多个 GROUP BY 子句组合到一个 GROUP BY 子句中。 其结果与针对指定的组执行 UNION ALL 运算等效。
SELECT Country, Region, SUM(Sales) AS TotalSales FROM Sales GROUP BY GROUPING SETS ( ROLLUP (Country, Region), CUBE (Country, Region) ); --等效于 SELECT Country, Region, SUM(Sales) AS TotalSales FROM Sales GROUP BY ROLLUP (Country, Region) UNION ALL SELECT Country, Region, SUM(Sales) AS TotalSales FROM Sales GROUP BY CUBE (Country, Region);
SQL 不会合并为 GROUPING SETS 列表生成的重复组。在 GROUP BY ( (), CUBE (Country, Region) ) 中,两个元素都返回总计行并且这两行都会列在结果中。
6.GROUP BY ()
指定生成总计的空组。 这作为 GROUPING SET 的元素之一来说非常有用。 例如,此语句给出每个国家/地区的总销售额,然后给出了所有国家/地区的总和。
SELECT Country, SUM(Sales) AS TotalSales FROM Sales GROUP BY GROUPING SETS ( Country, () );
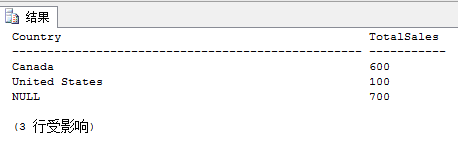
7.配合子句
经常与order by 字句、having 字句连用。
HAVING 子句
对GROUP BY 字句中的结果进行筛选。
HAVING 子句
可以使用select 子句中的别名
| 类别 | 作为特征的语法元素 |
|---|---|
| 基本语法 | ORDER BY |
| 指定升序和降序 | DESC • ASC |
| 指定排序规则 | COLLATE |
| 指定条件顺序 | CASE 表达式 |
| 在排名函数中使用 ORDER BY | 排名函数 |
| 限制返回的行数 | OFFSET • FETCH |
| 将 ORDER BY 与 UNION、EXCEPT 和 INTERSECT 一起使用 | ORDER BY 必须放到最后使用 |
在与 SELECT…INTO 语句一起使用以从另一来源插入行时,ORDER BY 子句不能保证按指定的顺序插入这些行。
在视图中使用 OFFSET 和 FETCH 并不会更改该视图的 Updateability 属性?
OVER 子句
参考:https://docs.microsoft.com/zh-cn/sql/t-sql/queries/select-over-clause-transact-sql?view=sql-server-2017
APPLY 子句
参考:https://docs.microsoft.com/zh-cn/sql/t-sql/queries/from-transact-sql?view=sql-server-2017
JOIN 子句
1.LEFT JOIN
2.RIGHT JOIN
3.FULL JOIN
4.CROSS JOIN
5.INNER JOIN
PIVOT 与UNPIVOT 子句.
参考:https://www.cnblogs.com/hbwy/p/4914000.html
1.PIVOT
行转列
TABLE_SOURCE AS P PIVOT( 聚合函数(value_column) FOR P.pivot_column IN(<column_list>) AS T
SELECT * FROM Guocheng .DBO.每日消费 AS P PIVOT (SUM(数值) FOR 数据类型 in ([展现],[点击],[消费])) as t where 日期 >='2019-06-08'

2.UNPIVOT
列转行
TABLE_SOURCE AS P UNPIVOT( value_column FOR P.pivot_column IN(<column_list>) AS U )
select * from (SELECT * FROM Guocheng .DBO.每日消费 AS P PIVOT (SUM(数值) FOR 数据类型 in ([展现],[点击],[消费])) as t where 日期 >='2019-06-08' ) as u UNPIVOT (数值 FOR 数据类型 in ([展现],[点击],[消费]) ) as UN
 .
.