本章我们在Linux系统环境下,对数据的清洗和整理做简单的讲解。
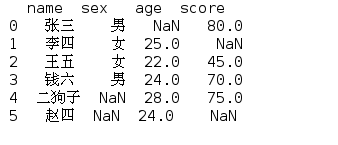
首先我们创建一个数据或者文件,个人信息文件info.csv
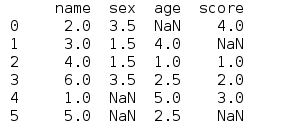
df=pd.read_csv('info.csv') print(df)
(根据文件路径的不同,自行更改文件读取的路径。)
1.缺失值的填充
print(df.fillna(0))
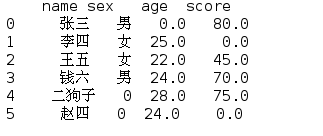
虽然都填充为0,但这样显然有些不太合适,我们希望在性别添加男或女,年龄和分数希望是一个平均数。
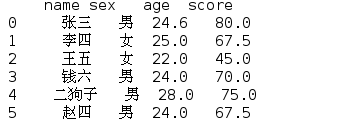
m=df['age'].mean() n=df['score'].mean() df1=df.fillna(value={'sex':'男','age':m,'score':n}) print(df1)
得到了:
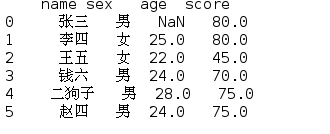
当然,也可以用fillna的参数method=‘ffill’,在列方向上以前一个值作为值赋给NaN。
print(df.fillna(method='ffill'))
得到第一行无法改变外:
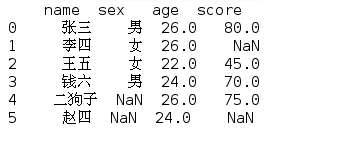
2.值的替换replace(to_replace=x)
a=df[df['age']>24] df1=df.replace(to_replace={'age':a},value=26) print(df1)
得到:包括未被赋值的
3.删除空值的行和列dropna()
df.dropna()#每行只要有空值,默认axis=0,就将这行删除
df.dropna(axis=1)#每列只要有空值,整列丢弃
df.dropna(how='all')# 一行中全部为NaN的,才丢弃该行
df.dropna(thresh=3)# 每行至少3个非空值才保留
4.重复值的处理duplicated(),unique(),drop_duplictad()
print(df.nunique())
得到各个列的种类个数:

df.drop_duplicates(['k1'])# 保留k1列中的唯一值的行,默认保留第一行
df3=df.drop_duplicates('age') print(df3)
输出:
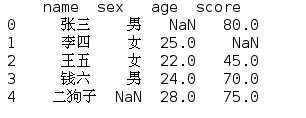
其中最后一行中,age=24的被删除掉。
5.排序sort
print(df.sort_index(axis=1))
会根据列名进行排序,sort_index()默认的时axis=0。
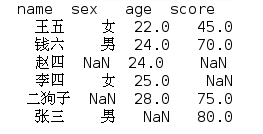
对值进行排序:
print(df.sort_values(by=['age']))
得到:(空值默认排到最后)
排名次:
print(df.rank())
得到:(默认axis=0)
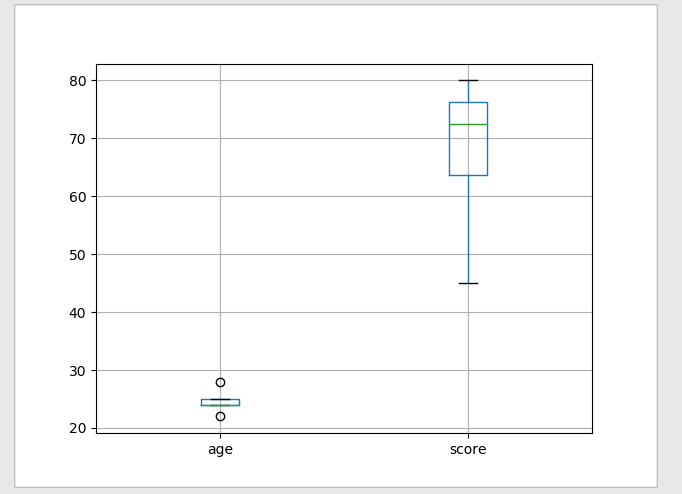
视图展示:m=df['age'].mean() n=df['score'].mean() df1=df.fillna(value={'sex':'男','age':m,'score':n}) df1.boxplot() plt.show()
视图: