基本流程
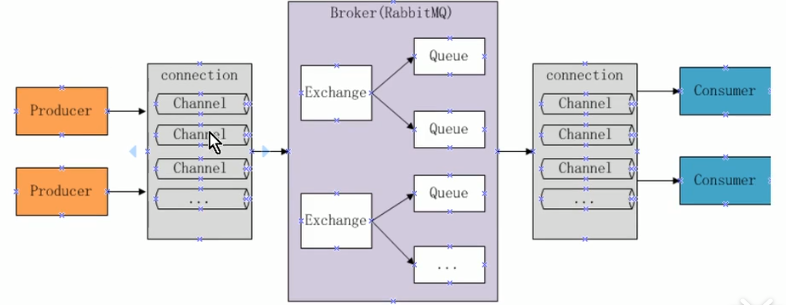
WebUI管理,可视化的管理查看队列状态
rabbitmq的命令
rabbitmq-plugins enable rabbitmq_management
重启后访问:http://localhost:15672/
用户名:guest
密码: guest
重启rabbitmq服务
rabbitmq-server restart
角色,用户设为administrator才能远程访问
management
policymaker
monitoring
administrator
添加用户,分配角色,并设置用户的权限
rabbitmqctl add [name] [password]
rabbitmqctl set_user_tags name administrator
rabbitmqctl set_permissions -p / [name] "." "." ".*" name用户的所有ip地址可以访问
其他命令
rabbitmqctl list_queues 查看队列,当队列中存在多条消息时,执行一次接受,会将所有消息都接收,接受之后,队列中没有消息
#sender.py
import pika
#连接远程rabbitmq时必须要添加用户名和密码,访问本地的不用。先使用上述命令在远程添加用户,然后使用这个用户名和密码连接
credentials = pika.PlainCredentials("zwh", "zwn123")
#创建socket连接
connection = pika.BlockingConnection(pika.ConnectionParameters('192.108.12..23'), credentials=credentials)
#建立rabbit协议通道
channel = connection.channel()
#声明队列durable
channel.queue_declare(queue='hello', durable=True) #durable=True表示持久化保存队列信息,但是队列中的消息不会保存
#发布消息,指定连接的交换机并发布消息
channel.basic_publish(exchange='', routing_key='hello', body='hello world', #routing_key指定队列
properties=pika.BasicProperties(
delivery_mode=2)) #持久化保存队列中的消息
connection.close()
#receive.py
import pika
#连接远程rabbitmq时必须要添加用户名和密码,访问本地的不用。先使用上述命令在远程添加用户,然后使用这个用户名和密码连接
credentials = pika.PlainCredentials("zwh", "zwn123")
#创建socket连接
connection = pika.BlockingConnection(pika.ConnectionParameters('192.108.12..23'), credentials=credentials)
#建立rabbit协议通道
channel = connection.channel()
#声明队列
channel.queue_declare(queue='hello')
def callback(ch, method, properties, body): #ch是发送方通道的实例,body是数据的内容(bytes格式)
print("处理数据”)
ch.basic_ack(delivery_tag=method.delivery_tag
channel.basic_consume(callback,
queue='hello',
no_ack=True, #处理完后不需要发确认消息,默认是false即需要确认消息,将处理的状态告诉sender,还需要在callback中使用basic_ack手动确认)
# 如果Rabbit只管按顺序把消息发到各个消费者身上,不考虑消费者负载的话,很可能出现,一个机器配置不高的消费者那里堆积了很多消息处理不完,同时配置高的消费者却一直很轻松。为解决此问题,可以在各个消费者端,配置perfetch=1,意思就是告诉RabbitMQ在我这个消费者当前消息还没处理完的时候就不要再给我发新消息了
channel.basic_qos(prefetch_count=1)
channel.start_consuming() #同步消费,一直监听着消息队列,不能干别的,异步见后面PRC

- 当接收者A要回发确认消息时(即no_ack=False),队列中的消息被接受后不会消失,会被打上标记,被接收者A拿走,其他的接收者不会拿走消息,当接收者A处理失败时,消息自动被其他接收者拿走,处理成功时,返回标记,队列收到销毁该消息
- 当接受者A不要回发确认消息时(即no_ack=True),取走队列中的消息后,队列就不管消息是不是被成功处理
- sender和receiver最后都声明队列,因为sender和receiver都可以先循行,后运行的那个不用声明队列,如果声明,队列的参数必须一样
- 要持久化消息分两步:1. 持久化队列channel.queue_declare(queue='hello', durable=True) 2. 持久化消息properties=pika.BasicProperties(delivery_mode=2)
- 如果Rabbit只管按顺序把消息发到各个消费者身上,不考虑消费者负载的话,很可能出现,一个机器配置不高的消费者那里堆积了很多消息处理不完,同时配置高的消费者却一直很轻松。为解决此问题,可以在各个消费者端,配置perfetch=1,意思就是告诉RabbitMQ在我这个消费者当前消息还没处理完的时候就不要再给我发新消息了
连接参数
'''python
pika.ConnectionParameters(host=""127.0.0.1, port=3336, heartbeat = 0)
'''
heartbeat用来控制连接时常,如果处理函数时间过长,超过heartbeat默认的时间,连接就会断开,将其设置为0表示无论处理时间多长连接都不会断
channel详解
方法:
- exchangeDeclare()
- basicQos()
- basicPublish()
- basicAck()
- basicNack(delivery.getEnvelope().getDeliveryTag(), false, true)
- basicReject(delivery.getEnvelope().getDeliveryTag(), false)
- basicConsume(QUEUE_NAME, true, consumer)
- exchangeBind()
- queueDeclare(QUEUE_NAME, false, false, false, null)
详情见:https://www.cnblogs.com/piaolingzxh/p/5448927.html
一对多消息(使用exchange)
Exchange的定义是有类型的,决定那些queue符合条件可以接受消息,routingKey更像re表达式,匹配到那个
- fanout: 所有bind到此exchange的queue都可以接收消息,所以不需要指定队列了
- direct: 通过routingKey和exchange决定的哪些可以接收消息
- topic:所有符合routingKey(此时可以是一个表达式)的routingKey所bind的queue可以接收消息
表达式符号说明:#代表一个或多个字符,*代表任何字符
例:#.a会匹配a.a,aa.a,aaa.a等
*.a会匹配a.a,b.a,c.a等
注:使用RoutingKey为#,Exchange Type为topic的时候相当于使用fanout - headers: 通过headers 来决定把消息发给哪些queue
fanout(广播)
*sender广播时,如果receiver没有运行接受消息,等运行之后就接收不到了

#sender
import pika
import sys
connection = pika.BlockingConnection(pika.ConnectionParameters(
host='localhost'))
channel = connection.channel()
channel.exchange_declare(exchange='logs',
type='fanout')
message = ' '.join(sys.argv[1:]) or "info: Hello World!"
channel.basic_publish(exchange='logs',
routing_key='',
body=message)
print(" [x] Sent %r" % message)
connection.close()
#receiver
import pika
connection = pika.BlockingConnection(pika.ConnectionParameters(
host='localhost'))
channel = connection.channel()
channel.exchange_declare(exchange='logs', #接受者也声明交换机是因为接收者可能先于发送者运行
type='fanout')
result = channel.queue_declare(exclusive=True) #不指定queue名字,rabbit会随机分配一个名字,exclusive=True会在使用此queue的消费者断开后,自动将queue删除
queue_name = result.method.queue
channel.queue_bind(exchange='logs',
queue=queue_name)
print(' [*] Waiting for logs. To exit press CTRL+C')
def callback(ch, method, properties, body):
print(" [x] %r" % body)
channel.basic_consume(callback,
queue=queue_name,
no_ack=True)
channel.start_consuming()
有选择的接收消息(组播exchange type=direct) and type=topic
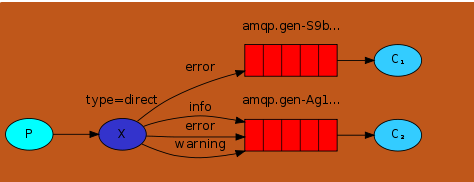
RabbitMQ还支持根据关键字发送,即:发送者将数据发送到exchange时的消息绑定着关键字,不同类型的exchange解析 关键字 判定应该将数据发送至指定队列,这些队列绑定均绑定者不同的关键字,通过routing_key来绑定,它更像是一个正则表达式(exchange为topic时,关键字包含通配符,为direct时,关键字为常量,匹配到什么队列的关键字就给什么队列发消息
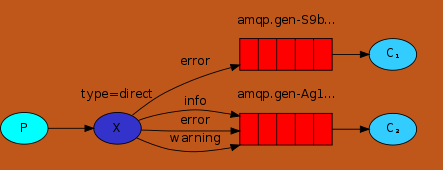
#sender
import pika
import sys
connection = pika.BlockingConnection(pika.ConnectionParameters(
host='localhost'))
channel = connection.channel()
channel.exchange_declare(exchange='direct_logs',
type='direct')
severity = sys.argv[1] if len(sys.argv) > 1 else 'info' #通过脚本传递的参数第一个值是关键字,通过routing_key来决定将消息传递给那些队列
message = ' '.join(sys.argv[2:]) or 'Hello World!'
channel.basic_publish(exchange='direct_logs',
routing_key=severity,
body=message)
print(" [x] Sent %r:%r" % (severity, message))
connection.close()
#receiver
import pika
import sys
connection = pika.BlockingConnection(pika.ConnectionParameters(
host='localhost'))
channel = connection.channel()
channel.exchange_declare(exchange='direct_logs',
type='direct')
result = channel.queue_declare(exclusive=True)
queue_name = result.method.queue
severities = sys.argv[1:]
if not severities:
sys.stderr.write("Usage: %s [info] [warning] [error]
" % sys.argv[0])
sys.exit(1)
for severity in severities:
channel.queue_bind(exchange='direct_logs',
queue=queue_name,
routing_key=severity) #绑定多个关键字,每一次绑定要分开绑
print(' [*] Waiting for logs. To exit press CTRL+C')
def callback(ch, method, properties, body):
print(" [x] %r:%r" % (method.routing_key, body))
channel.basic_consume(callback,
queue=queue_name,
no_ack=True)
channel.start_consuming()
RPC: remote produce call
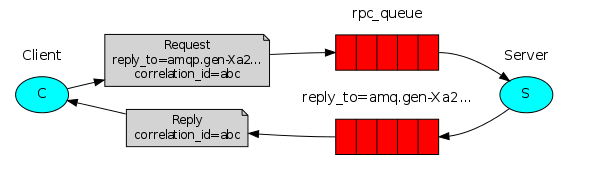
import pika
import time
connection = pika.BlockingConnection(pika.ConnectionParameters(
host='localhost'))
channel = connection.channel()
channel.queue_declare(queue='rpc_queue')
def fib(n):
if n == 0:
return 0
elif n == 1:
return 1
else:
return fib(n-1) + fib(n-2)
def on_request(ch, method, props, body):
n = int(body)
print(" [.] fib(%s)" % n)
response = fib(n)
ch.basic_publish(exchange='',
routing_key=props.reply_to,
properties=pika.BasicProperties(correlation_id =
props.correlation_id),
body=str(response))
ch.basic_ack(delivery_tag = method.delivery_tag)
channel.basic_qos(prefetch_count=1) #一次只拿一个消息,当前任务没有处理完就不会去队列中拿消息,默认情况下不考虑处理的快慢,各个消费者拿的消息个数是相同的
channel.basic_consume(on_request, queue='rpc_queue')
print(" [x] Awaiting RPC requests")
channel.start_consuming()
#client.py
import pika
import uuid
class FibonacciRpcClient(object):
def __init__(self):
self.connection = pika.BlockingConnection(pika.ConnectionParameters(
host='localhost'))
self.channel = self.connection.channel()
result = self.channel.queue_declare(exclusive=True)
self.callback_queue = result.method.queue
self.channel.basic_consume(self.on_response, no_ack=True, #准备消费,设置消费函数及各种配置,但还没有开始,同步还是异步消费还没有定
queue=self.callback_queue)
def on_response(self, ch, method, props, body):
if self.corr_id == props.correlation_id: #相等的话就是当前发的命令的结果,不是别的命令的结果
self.response = body
def call(self, n):
self.response = None
self.corr_id = str(uuid.uuid4()) # 唯一标识符,标识要发送的数据,可能会发送多条,通过这个进行区分数据
self.channel.basic_publish(exchange='',
routing_key='rpc_queue', #此处没有声明rpc_queue,则一定是客户端声明了
properties=pika.BasicProperties(
reply_to = self.callback_queue, #指定返回的数据发送到哪个队列
correlation_id = self.corr_id, #该数据的标识符
),
body=str(n))
while self.response is None:
self.connection.process_data_events() #检查队列里有没有新消息,但不会阻塞(异步),使用channel.start_consuming()的话会一直阻塞(同步),
return int(self.response)
fibonacci_rpc = FibonacciRpcClient()
print(" [x] Requesting fib(30)")
response = fibonacci_rpc.call(30)
print(" [.] Got %r" % response)