1. 匹配:like 关键字
#假设存在表 my_test_copy select * from my_test_copy;
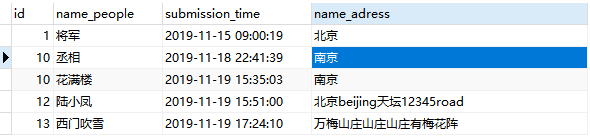
则使用like关键词匹配:注意下划线 '_'和百分号 '%'
# 下划线'_'匹配任意单个字符 # 百分号'%'匹配任意数目的字符 select * from my_test_copy where name_people like '_满_'; #有值 select * from my_test_copy where name_people like '%满%'; #有值,百分号可以匹配任意数目的字符 select * from my_test_copy where name_people like '%楼'; #有值,百分号可以匹配任意数目的字符 select * from my_test_copy where name_people like '_楼'; #为空,因为下划线只能代表一个字符 select * from my_test_copy where name_people like '_满楼'; #有值
2. 正则表达式:'rlike' 和 'regexp'同义,用于标识正则表达式模式
(1)'rlike' 和 'regexp'
select 'abc' regexp 'ab'; # regexp左操作数是要匹配的字符串,右操作数是匹配模式 select * from my_test_copy where name_people regexp '花'; select * from my_test_copy where name_people rlike '花';

(2)直接匹配
select 'abc' regexp 'b'; #返回1 select * from my_test_copy where name_people regexp '满'; #有值
(3)'^'符号,匹配开头,从字符串开始进行匹配
select * from my_test_copy where name_adress regexp '^天坛'; #为空,用于查询以....开头的字符串,而没有以'天坛'开头的字符串 select * from my_test_copy where name_adress regexp '^北'; #有值,用于查询以....开头的字符串

(4)'$'符号,匹配结尾
select * from my_test_copy where name_adress regexp '北$'; #为空,用于查询以....结尾的字符串 select * from my_test_copy where name_adress regexp '京$'; #有值
(5)点号 '.' 符号,匹配任意一个字符
select * from my_test_copy where name_adress regexp '北.'; #有值 select * from my_test_copy where name_adress regexp '.京$'; #有值
(6)'+'符号,+前面的模式至少出现1次或以上
select * from my_test_copy where name_adress regexp 'beijing+'; #有值 select * from my_test_copy where name_adress regexp '京+'; #有值
(7)'*'符号,*前面的模式出现0次或以上
select * from my_test_copy where name_adress regexp '北京*'; #有值,'北'出现,且'京'接着'北'出现0次以上 select * from my_test_copy where name_adress regexp '人*'; #有值,出现0次
(8)'?'符号,'?'前面的模式出现0次或1次
select 'abc' regexp '^(ab)?c$'; #有值 select 'aaabc' regexp '^a*b?c$'; #有值 select 'ababc' regexp '^(ab)+c$'; #有值 select * from my_test_copy where name_adress regexp '人?'; #有值,出现0次 select * from my_test_copy where name_adress regexp '京?'; #有值,出现1次 select * from my_test_copy where name_adress regexp '(山庄)?'; #有值,出现0次或1次(山庄) select * from my_test_copy where name_adress regexp '山庄?'; #有值,出现了'山'和1次'庄'
(9)'()'符号,表示一个整体
select '33123400' regexp '(34)1'; #返回0:表示没找到 select 'ac' regexp '^(ab)?c$'; #为0,表示未找到 select 'ababc' regexp '^(ab)?c$'; # 结果为0,'?'表示出现0次或1次 开头'(ab)',而这个句子中出现了2次'ab',不符合条件,可以写成 select 'ababc' regexp '^(ab){1,3}c$'; # {1,3}表示(ab)出现的次数在1-3次都可以
(10)'[]'符号,表示对其中的任意一个字符进行匹配,且仅能匹配一个字符
select 'heo' regexp '^h[abcde]o$'; #为1 select 'hello' regexp '^h[abcde]o$'; #为0,,虽然能匹配'e',但是两个'l'没有匹配 select 'hello' regexp '^h[abcdehijklmn]o$'; #为0,,虽然能匹配'e'和'l',但是'[]'每次只能匹配其中一个字符 select * from my_test_copy where name_adress regexp '万梅[山庄阵]'; #有值,匹配到'万梅山'
(11)'[]'中可以使用'-'表示区间,表示该区间的任意一个字符,my_test是另一个表
select 'abcde' regexp '^a[a-k]'; select 'abcde' regexp '[a-k]'; #查找是否存在字母 select * from my_test where phone_number regexp '[0-9]'; #有值,匹配到数字 select * from my_test where phone_number regexp '12[a-z]'; #为空
(12)若'[]'需要匹配']',则']'必须紧跟在'['之后
select 'aacc' regexp 'a[]a-z]'; #有值 select 'aa]cc' regexp 'a[]]'; #有值 select 'aa]cc' regexp 'a[bcc]dd]'; #为0,因为']'不是紧跟着'[' select 'aa]cc' regexp 'a[]bcac]'; #为1 select 'aa]cc' regexp 'a[bc]]'; #为0,']'放在末尾也不行
(13)若'[]'需要匹配'-',则'-'需要放在'[]'两端,放在中间可能会报错:[Err] 3697 - The regular expression contains an [x-y] character range where x comes after y.
select 'aaa-ccc-ddd' regexp 'a[-]'; #有值 select 'aaa-ccc-ddd' regexp 'a[-cdf]'; #有值,匹配到'a-' select 'aaa-ccc-ddd' regexp 'a[d-a]'; #[Err] 3697 - The regular expression contains an [x-y] character range where x comes after y.
(14)[^]表示不含'[]'中的任意字符
#例如:不含数字 select 'aaabbb' regexp '[^0-9]'; #为1 select 'aaabbb' regexp '[^0-9]$'; #为1,不以数字结尾 select 'aaabbb233' regexp '[^0-9]$'; #为0 select 'aaabbb' regexp '^[^0-9]'; #为1,不以数字开头 select '23aaabbb' regexp '^[^0-9]'; #为0 select * from my_test_copy where name_adress regexp '[^北京]'; #表示不能只有'北京' select * from my_test_copy where name_adress regexp '^[^北]'; #表示开头不含'北' select * from my_test_copy where name_adress regexp '万梅[^山]'; #表示不含'万梅山'
(15)'|' 匹配分隔的任意一个字符
select 'abc' regexp 'b|a|c'; select * from my_test_copy where name_adress regexp '北京|南京'; #表示含有'北京'或'南京'的
(16)'{t}' 匹配前面的字符t次
select 'ababc' regexp '^(ab){2}c$'; #为1 select 'ababc' regexp '^ab{2}c$'; #为0,因为'b'没有出现2次 select 'abbbc' regexp '^ab{3}c$'; #为1
(17)'{t,s}'匹配前面的字符t-s次均可,t<=s
select 'abbbc' regexp '^ab{2,4}c$'; #为1,因为'b'出现3次 select 'abc' regexp '^ab{2,4}c$'; #为0,因为'b'出现1次,不在2-4之间 select 'abbbbbbc' regexp '^ab{1,}c$'; #为1,{1,}缺省,表示出现1次及以上
(18){t,s}中不能出现空格,否则报错:[Err] 3692 - Incorrect description of a {min,max} interval.
select 'aoe' regexp '^ao{0 , 1}c$'; # [Err] 3692 - Incorrect description of a {min,max} interval.
#欢迎交流
参考:
https://www.cnblogs.com/liuwei6/p/7279542.html
https://blog.csdn.net/a1311010193/article/details/101388446
https://www.runoob.com/mysql/mysql-regexp.html