一、节点间平衡
1、Apache
开启数据均衡命令:
bin/start-balancer.sh –threshold 10
对于参数10,代表的是集群中各个节点的磁盘空间利用率相差不超过10%,可根据实际情况进行调整。
停止数据均衡命令:
bin/stop-balancer.sh
2、CDH
CDH在HDFS中提供了Balancer角色,使我们可以免于用命令行执行start-balancer.sh来手动配置。
Cloudera Manager里与Balancer有关的配置项有以下这些。
Balancing Threshold:Balancer平衡的阈值。平衡过程结束后,所有节点的磁盘占用率与集群的平均占用率之差必须小于threshold(按百分比计)。默认值是10。 Rebalancing Policy:计算平衡度的策略,有DataNode和BlockPool两种。前者是按节点级别来算,后者是按块池级别来算。后者只有对HDFS Federation才有效,所以我们选前者。 Included/Excluded Hosts:分别用来指定参与平衡的节点和被排除的节点。这样可以先人为判断数据分布情况,然后只让我们认为需要平衡的节点来操作。 dfs.balancer.moverThreads/dispatcherThreads:分别表示移动数据的线程池大小,和调度数据移动方案的线程池大小,默认值1000和200。 dfs.datanode.balance.max.concurrent.moves:表示能够同时移动的块(英文说法叫in-flight)数量,默认值50。 dfs.balancer.max-size-to-move:表示在Balancer的一次迭代(下面会提到)中,一个DataNode的最大数据交换量,默认值10G。 另外,还有一个出现在DataNode参数但又与平衡相关的:dfs.datanode.balance.bandwidthPerSec,即每个节点可以用来做平衡的最大带宽,默认1MB/s。这个值在多数情况下是偏小的,可以适当增大,如10甚至20。千万注意不能挤占太多带宽,以保证正常业务的运行。
我们使用CDH5.12.1,如下
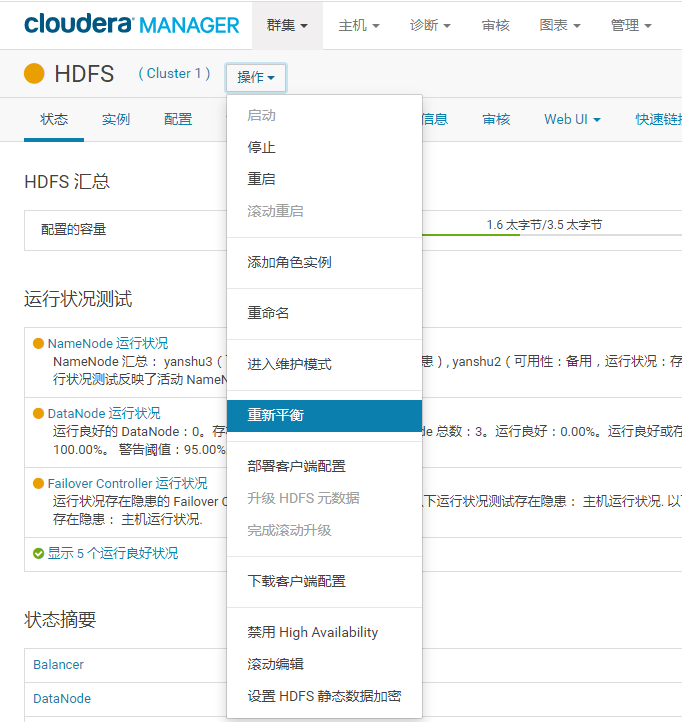
二、节点内(磁盘间)平衡
1、hadoop2.x
1.1 背景
当HDFS的datanode节点挂载多个磁盘时,往往会出现两种数据不均衡的情况:
(1) 不同datanode节点间数据不均衡;
(2) 挂载数据盘的磁盘间数据不均衡。
特别是这种情况:当datanode原来是挂载单数据磁盘,当磁盘占用率很高之后,再挂载新的数据盘。由于hadoop 2.x 版本并不支持 HDFS 的磁盘间数据均衡,因此,会造成老数据磁盘占用率很高,新挂载的数据盘几乎很空。在这种情况下,挂载新的数据盘就失去了扩容HDFS数据盘的意义。
1.2 解决方法
虽然hadoop官方并没有在hadoop 2.X 提供标准的磁盘间数据均衡方法,但是我们也可以通过一些其它途径来达到磁盘间数据均衡。
总体方法:通过升降HDFS数据的副本数量,“一减一增”过程中,“一减”过程中会将老数据盘的数据块删除一个副本,“一增”过程中会将增加的一个副本数据均衡写入到老数据盘和新数据盘。通过“一减一增”,使得一部分老数据盘的数据转移到新的数据盘。
升降数据副本:比如默认HDFS的副本数是3份。
(1)使用命令将HDFS的副本数降为2,此时HDFS会删除老数据盘上面的1份副本;
(2)再使用命令将HDFS的副本数升为3,此时HDFS会将新增的1份副本均匀分布在所有的磁盘(新老数据盘机会 均等地分布这一份副本数据);
理论上使用这种方法将整个HDFS数据执行一遍。(假设原来是一块数据盘,现在每个datanode新增一块数据盘)老的数据盘会减少 六分之一,减少的六分之一数据将会增加到新的数据盘。具体的计算过程如下:
假设原来磁盘的数据量为n GB,那么经过3副本降为2副本之后,老磁盘的数据量为:
n * 2/3
再经过副本2增加为3之后,老磁盘的数据量为:
n * 2/3 + n * 1/3 *1/2 = n * 5/6
因此,有 1/6 的数据从老磁盘迁移到新的磁盘。
升降副本是一个迫不得已的办法。如果在做升降副本过程中,datanode有节点挂掉,就会增加丢失数据块的几率。
因此,在做“一升一降”之前、执行的过程中,都需要检查HDFS是否健康。同时,当对大批量数据做均衡时,容易出现错误,需要对HDFS的子目录逐个做均衡。
1.3 具体操作办法
step1:检查HDFS健康程度:
su hdfs; hadoop fsck /
step2:检查各个目录的大小:
[hdfs@10]$ hadoop fs -du -h / 5.7 G /app-logs 677.9 G /apps 2.7 G /backup 0 /data 0 /group 365.3 M /hdp 0 /mapred 1.1 G /mr-history 1.1 T /project 0 /system 33.1 G /tmp 197.0 G /user
step3:对各个子目录(或者是子目录的子目录)进行副本数变更操作:
假如对HDFS的 /app-logs 子目录做变更,执行:
su hdfs; hadoop fsck /app-logs; ## 每次做变更之前很有必要检查集群HDFS健康程度 hadoop fs -setrep -R 2 /app-logs; ## 将副本数量降为2 hadoop fsck /app-logs; ## 很有必要每次做完变更副本之后检查集群HDFS健康程度 cd /data/tbds-base/usr/hdp/2.2.0.0-2041/hadoop/sbin/; ./start-balancer.sh -threshold 5; ## 变更副本之后,做一次HDFS集群间的数据均衡 hadoop fs -setrep -R 3 /app-logs; ## 将副本数量增为3,还原原来的副本数量 hadoop fsck /app-logs; ## 很有必要每次做完变更副本之后检查集群HDFS健康程度 cd /data/tbds-base/usr/hdp/2.2.0.0-2041/hadoop/sbin/; ./start-balancer.sh -threshold 5; ## 变更副本之后,做一次HDFS集群间的数据均衡
接下来再对HDFS的其它子目录实施同样的操作,直到把HDFS的所有目录都操作一遍。
1.4 进一步
对HDFS做完一次 “一降一增” 操作之后,理论上老数据盘会减少1/6的数据,新盘增加这部分数据。 如果觉得效果还不够理想,可以再进行一次上面的降升操作,老数据盘会再次将一些数据迁移到新的数据盘,只是迁移量没有前一次那么大了(读者可以自行计算理论上会迁移多少数据量)。
2、hadoop3.x
如果想要解决节点内多块磁盘数据不均衡的现象,就要借助DiskBalancer。在CDH 5.8.2+版本中,可以通过在CM中配置进行开启。如果使用的Hadoop版本是3.0+,就直接在hdfs-site.xml中加入相关项。
在HDFS配置项中找到“DataNode Advanced Configuration Snippet (Safety Valve) for hdfs-site.xml”,中文为“hdfs-site.xml的HDFS服务⾼级配置代码段(安全阀)”,加入:
<property> <name>dfs.disk.balancer.enabled</name> <value>true</value> </property> <property> <name>dfs.disk.balancer.max.disk.throughputInMBperSec</name> <value>50</value> </property> <property> <name>dfs.disk.balancer.plan.threshold.percent</name> <value>2</value> </property> <property> <name>dfs.disk.balancer.block.tolerance.percent</name> <value>5</value> </property>
dfs.disk.balancer.max.disk.throughputInMBperSec:指定磁盘间平衡时占用的最大磁盘带宽,默认值10MB/s。在不影响读写性能的情况下可以适当调大。
dfs.disk.balancer.plan.threshold.percent:各盘之间数据平衡的阈值。DiskBalancer中采用一种叫volume data density(卷数据密度)的度量来确定占用率的偏差值,该值越大,表明磁盘间的数据越不均衡。平衡过程结束后,每个盘的卷数据密度与平均密度之差必须小于threshold(按百分比计)。默认值是10,我们设成了5。
dfs.disk.balancer.block.tolerance.percent:在每次移动块的过程中,移动块的数量与理想平衡状态之间的偏差容忍值(按百分比计)。一般也设成5。
DiskBalancer的运行流程与Balancer类似,不过对象由节点变成了磁盘。它分为Discover、Plan与Execute三个阶段,分别是计算磁盘不平衡度、生成平衡计划与执行平衡计划。关于它的设计细节,可以参考JIRA中的HDFS-1312:https://issues.apache.org/jira/browse/HDFS-1312。
配置完成后,重启DataNode,然后SSH到该节点上,手动执行即可:
生成平衡计划(hadoop1为主机名) hdfs diskbalancer -plan hadoop1 执行平衡计划 hdfs diskbalancer -execute /system/diskbalancer/hadoop1.plan.json 查看执行状态 hdfs diskbalancer -query hadoop1
1.3 hadoop 2.x单副本
1.问题梳理:
CDH集群中,数据文件位置默认在 /dfs/dn 中,这个目录所属的盘符是 /,但是 ‘/’只有100G大小,还有其他各种文件的日志什么的,空间很紧张。
今天执行hive问题,发现集群一直报警。查阅了资料,需要将CDH集群 HDFS数据存储 更换目录。
通过命令查看各个盘符 占用情况
df -h

2. 处理
1. 定位思路
先将集群停止,然后准备好新的存储目录,再将数据复制到新的目录中,重启集群。
2.处理步骤
假设HDFS的默认安装目录为“/dfs/dn”,需要移动目录到“/home/dfs_new/dn”中。
1 .登录cdh manager,停止hdfs集群
2 .在home目录下创建 dfs_new/dn 目录
cd /home mkdir -p /home/dfs_new/dn
3.更改目录所属的用户和组
chown -R hdfs /home/dfs_new/dn chgrp -R hadoop /home/dfs_new/dn
使用cdh 搭建hdfs集群的时候,默认用户为hdfs ,默认用户组为hadoop
将数据复制到目标目录:当前DataNode的目录为根目录下,和系统目录在同一目录下,随着DataNode的增长导致系统运行空间不足
cp -af /dfs/dn/* /home/dfs_new/dn
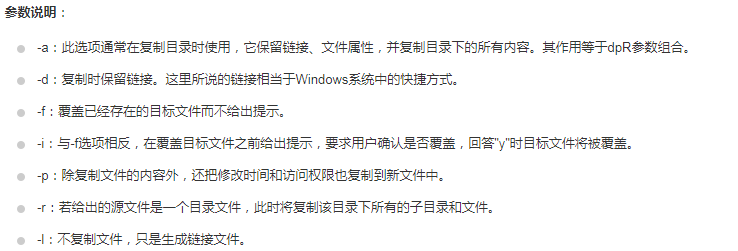
4 . 在cdh Manager管理界面,更改DataNode的配置目录
打开HDFS服务datanode配置页面,将所有datanode的数据目录配置项“dfs.datanode.data.dir”
由“/dfs/dn”修改为“/home/dfs_new/dn”。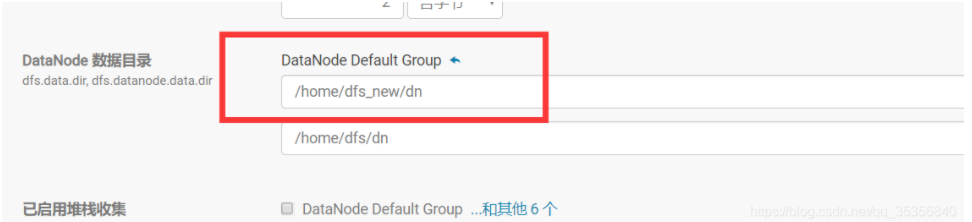
5 . 启动成功后,执行fsck检查是否复制正确。 命令样例:
hdfs fsck /
6 . fsck显示有文件丢失,则检查2是否正确,并执行相关的修复。
7 . fsck显示文件无文件丢失,HDFS没有处于安全模式,则表示数据复制成功。
8 . 删除原有数据目录“/dfs/dn”中的文件。
9 . 启动集群中剩余的服务。
10 . 再平衡
参考文章:
https://blog.csdn.net/tianlianchao1982/article/details/107124286
https://cloud.tencent.com/developer/article/1025424
https://blog.csdn.net/qq_35356840/article/details/98947580