一:
结对伙伴地址:https://www.cnblogs.com/543123abcxmr/p/10658409.html
二:PSP表格:
|
Personal Software Process Stages |
预估耗时(分钟) |
实际耗时(分钟) |
|
计划 |
10 |
10 |
|
· 需求分析 (包括学习新技术) |
100 |
100 |
|
· 代码规范 (为目前的开发制定合适的规范) |
20 |
20 |
|
· 具体设计 |
20 |
20 |
|
· 具体编码 |
150 |
200 |
|
· 代码复审 |
50 |
50 |
|
· 测试(自我测试,修改代码,提交修改) |
60 |
80 |
|
· 事后总结, 并提出过程改进计划 |
30 |
30 |
|
合计 |
440 |
510 |
三:解题思路:
本次项目中,我和慕荣一开始决定分工写代码,后来出现了一点小问题,最终决定采用我的代码在我的代码上增加了一些改动,大家一起完成了测试。
1.说实话,看到题目的那一刻我比较茫然,因为之前没有写过类似的,所以就先上网查阅了相关的资料,知道了大体要用到哪些函数,因为之前数据结构也没好好学,所以导致dictionary也不太会用,hash表也是,但是通过learning by doing也还可以,大致知道了怎么用,虽然用得不太好,但也比之前好多了不是。
2.在读取文本信息的时候,一是采用了steamreader,但是值得注意的是,就算你用完之后close以后还是不可以直接再来一次steamreader,得使用using才可以。二是使用了file.readalllines
3.切分文本:因为能力有限,所以一开始我并不知道每一步该用到什么函数/表达式,所以当我已经切分好了后,才意识到用正则表达式更好。
4.在排序的时候本来一开始用的是sortedlist,当时想的是可以自动排序,结果写到一半的时候只能key值排序,不能按value排序,而如果把两个反过来的话又不能保证key唯一,遂作罢。
5.按照字典序输出到文本txt,当我把大体做完了以后,和伙伴讨论的时候才发现这部分忘记写了...后采用了file.AppendAllText。
四:设计实现
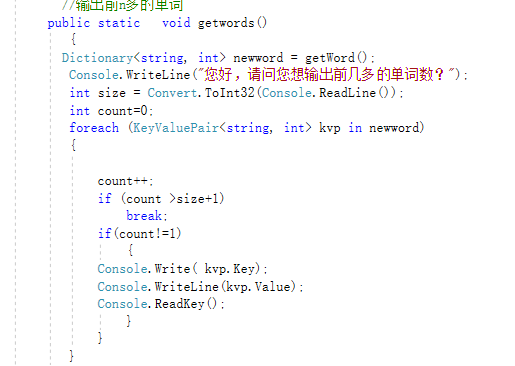
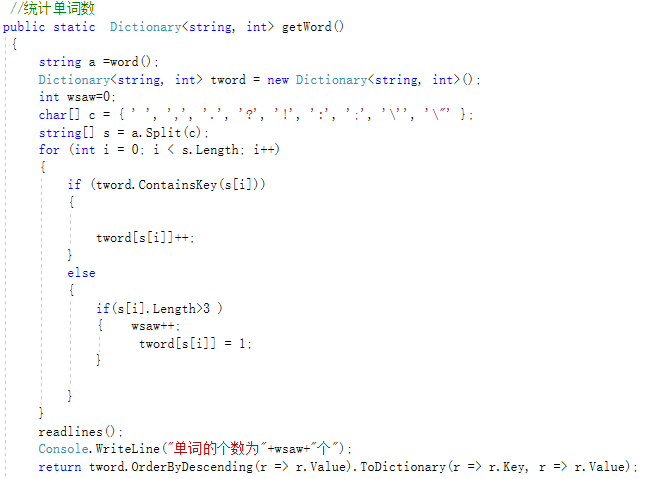
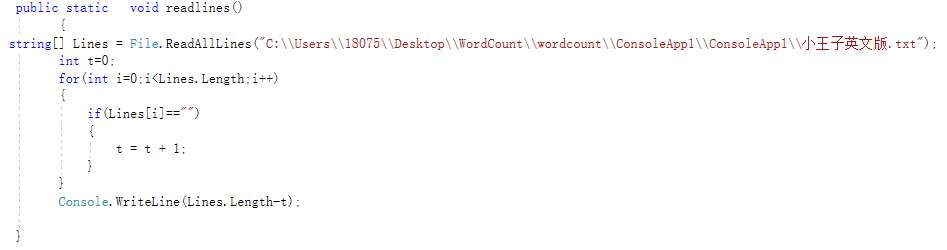
1.按照题目要求分别写了统计字符数函数,统计单词数函数,统计有效行数函数,统计前n多的单词函数,统计出现次数前十的单词以及切分指定长度词组我放在了main函数里,通过一开始main函数实现了把所有函数连接起来了。
2.一些代码部分:

3.运行结果:

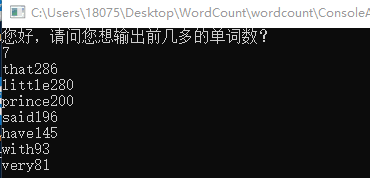

(词频统计这里还有问题,我有设置端点循环次数是对的,但是不知道为什么显示出来就成这样了。)
五:代码互审:
在代码互审阶段,伙伴发现了我没有输出到txt文本...和可以采用file.readAllLines读入文本。
六:单元测试+性能分析:

不出意料,在性能分析的时候发现果然是main函数的时间最多,其原因就是因为for循坏,如果读入的文本越大则占有的时间也就愈多了,但是无奈我还没有想到方法改进。
七:异常处理:

此次异常处理的太少了,下次值得注意。
八:结对过程:

九:总结:
1.在这次项目中学到了很多,其实老实说我在第三部分列出来得都是我现学得...(所以足以说明我太菜了)其实在这次项目中还有三个地方有大问题,一是:指定长度的词组的词频我只实现了输出词频却没能实现统计。二是:字符串分割时我明明分割了但是不知道为什么会出现"????",而且文本里其实也没有"????"(我猜想如果用到正则可以改掉这个bug但是考虑到最终改动较大,故没有完善。)三是:我的文本信息并没有在控制台输入,是写在了程序里,这也就意味着我写死了...虽然我没能实现全部功能但是我觉得也学到了不少。
2.在结对编程的过程中,感觉也还好,复审小伙伴能发现一些自己没能察觉的点,手动点赞。大家有所分工也不错。
最后:
人生没有回程线,活在当下,day day up是最好的状态。