诛仙是我很喜欢的一部小说,闲来无事,对他做了一下简单的人物出场次数的统计,来看看诛仙这部小说的男女主人公到底是谁
运行成功后,实现的效果如图
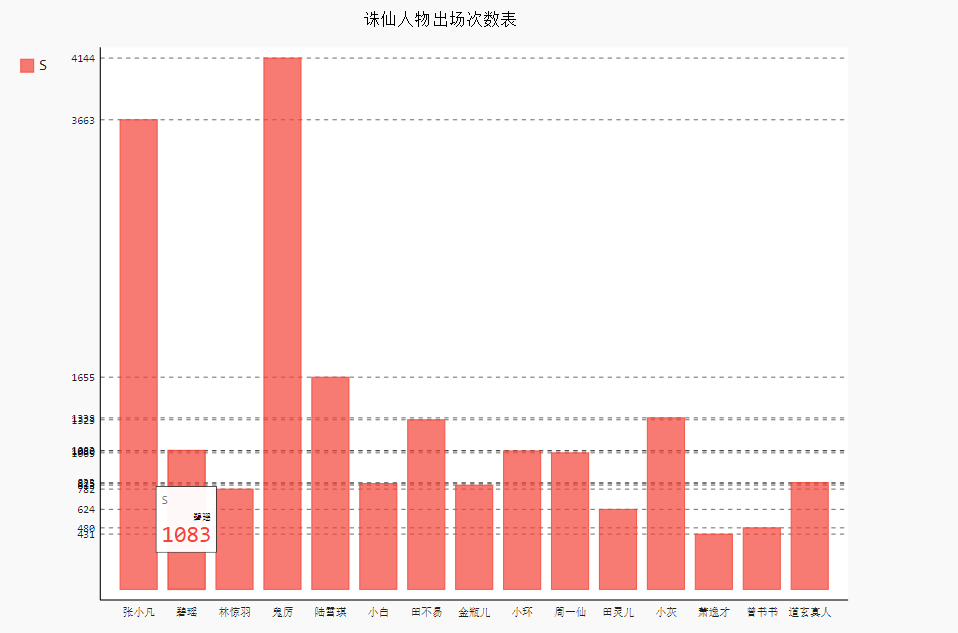

可以清楚的看出,张小凡,鬼厉,是男主角,陆雪琪是女主角
直接上代码:
1 # -*- coding: utf-8 -*- 2 # @Time : 2018/8/13 10:47 3 # @Author : wjh 4 # @File : jieba_pygal.py 5 6 7 import jieba 8 9 text = open('诛仙.txt', 'r', encoding='utf-8').read() 10 jieba.add_word('张小凡') # 添加字典词 11 jieba.add_word('碧瑶') 12 jieba.add_word('林惊羽') 13 jieba.add_word('鬼厉') 14 jieba.add_word('陆雪琪') 15 jieba.add_word('小白') 16 jieba.add_word('田不易') 17 jieba.add_word('金瓶儿') 18 jieba.add_word('小环') 19 jieba.add_word('周一仙') 20 jieba.add_word('田灵儿') 21 jieba.add_word('小灰') 22 jieba.add_word('萧逸才') 23 jieba.add_word('曾书书') 24 jieba.add_word('道玄真人') 25 words = jieba.lcut(text) # 开始分词 26 27 28 counts = {} 29 for word in words: # 开始统计 30 if len(word) == 1: 31 continue 32 counts[word] = counts.get(word, 0) + 1 # 出现就加一 33 items = list(counts.items()) 34 items.sort(key=lambda x: x[1], reverse=True) # key定义排序方式, 35 # 这里表示列表第二个值为排序标准,并且反向 36 items = dict(items) 37 x_value = ['张小凡', '碧瑶', '林惊羽', '鬼厉', '陆雪琪', '小白', 38 '田不易', '金瓶儿', '小环', '周一仙', '田灵儿', '小灰', '萧逸才', 39 '曾书书', '道玄真人'] 40 张小凡 = items['张小凡'] 41 碧瑶 = items['碧瑶'] 42 林惊羽 = items['林惊羽'] 43 鬼厉 = items['鬼厉'] 44 陆雪琪 = items['陆雪琪'] 45 小白 = items['小白'] 46 田不易 = items['田不易'] 47 金瓶儿 = items['金瓶儿'] 48 小环 = items['小环'] 49 周一仙 = items['周一仙'] 50 田灵儿 = items['田灵儿'] 51 小灰 = items['小灰'] 52 萧逸才 = items['萧逸才'] 53 曾书书 = items['曾书书'] 54 道玄真人 = items['道玄真人'] 55 y_value = [张小凡, 碧瑶, 林惊羽, 鬼厉, 陆雪琪, 小白, 56 田不易, 金瓶儿, 小环, 周一仙, 田灵儿, 小灰, 萧逸才, 57 曾书书, 道玄真人] 58 59 60 61 62 63 64 65 66 '''绘制条形统计图''' 67 68 # 对结果进行可视化 69 import pygal 70 hist = pygal.Bar() 71 72 hist.title = '诛仙人物出场次数表' 73 hist.x_labels = x_value 74 hist.title = '人物' 75 hist.y_labels = y_value 76 hist.title = '次数' 77 78 hist.add('S', y_value) # 值的标签, 值的列表 79 hist.render_to_file('诛仙人物出场次数表.svg') 80 81 82 83 84 85 86 87 88 89 90 91 92 93 '''绘制云图''' 94 95 import wordcloud 96 import matplotlib.pyplot as plt 97 text = [] 98 for word in words: 99 if len(word) == 1: 100 continue 101 text.append(word) 102 text = ' '.join(text) # 云词只能传入空格形式的字符串 103 104 font = 'D:Pythonpython_learnjiebaHiragino Sans GB.ttc' 105 wd = wordcloud.WordCloud( 106 font_path=font, 107 width=1000, 108 height=600, 109 background_color='white' 110 ).generate(text) 111 112 plt.figure() 113 plt.axis('off') # 去掉x,y轴 114 plt.imshow(wd) 115 plt.show() 116 wd.to_file('诛仙云词.png')
一种新的统计方法:
import jieba from collections import Counter def get_words(txt): # 开始分词 seg_list = jieba.cut(txt) # 生成一个Counter对象接收分词的频率 c = Counter() for x in seg_list: if len(x)>1 and x != ' ': c[x] += 1 # Counter没有默认返回0 print('词频统计') # most_common方法返回数量靠前的对象 for (k, v) in c.most_common(100): print(f'{k}: {v}')