在 Transformer架构记录(一)中,得到了一句话的数字表示 X,下面将 X 输入到Encoder的第一个Encoder-block中对其做进一步处理。
一个完整的Encoder-block如下图所示:

一个完整的Encoder-block由两个子模块构成,分别为Multi-Head Attention + Add&Norm 组成的第一子层,Feed Forward + Add&Norm 组成的第二子层。
Multi-Head Attention + Add&Norm 第一子层
1.1 Multi-Head Attention
Multi-Head Attention的输入为 X (当然,排在后面的Encoder-block的Multi-Head Attention的输入为前一个Encoder-block第二子层Add&Norm的输出);
Multi-Head Attention的输出记为 X_mha(X_mha与X的size相同);
具体从 X 到 X_mha 见 “Transformer架构记录(三)”。
1.2 Add&Norm
Add&Norm的输入为 X 与 X_mha,处理流程如下:
X_add_1 = X + X_mha(此处理解为普通的矩阵加法, X_add_1 、 X 、 X_mha的size相同)
这是一种残差连接处理方法;
X_norm_1 = LayerNorm( X_add_1 ) ,X_norm_1 、 X_add_1 、 X 、 X_mha的size相同;
Layer Normalization 会将每一层神经元的输入都转成均值方差都一样的,这样可以加快收敛。
Feed Forward + Add&Norm 第二子层
2.1 Feed Forward
Feed Forward的输入为第一子层Add&Norm的输出,本例中为 X_norm_1 ,
Feed Forward对X_norm_1的处理为:X_ff = max(0, X_norm_1W_1 + b_1)W_2 + b_2 (X_ff 、 X_norm_1 、 X_add_1 、 X 、 X_mha的size相同)
2.2 Add&Norm
Add&Norm的输入为 X_norm_1 与 X_ff,处理流程如下:
X_add_2 = X_norm_1 + X_ff(X_add_2 、X_ff 、 X_norm_1 、 X_add_1 、 X 、 X_mha的size相同)
X_norm_2 = LayerNorm( X_add_2 ) (X_norm_2 、 X_add_2 、X_ff 、 X_norm_1 、 X_add_1 、 X 、 X_mha的size相同)
最终一个Encoder-block的输出为X_norm_2,它与该Encoder-block的输入 X 的size相同;即每个Encoder-block的输入与输出的大小一致。
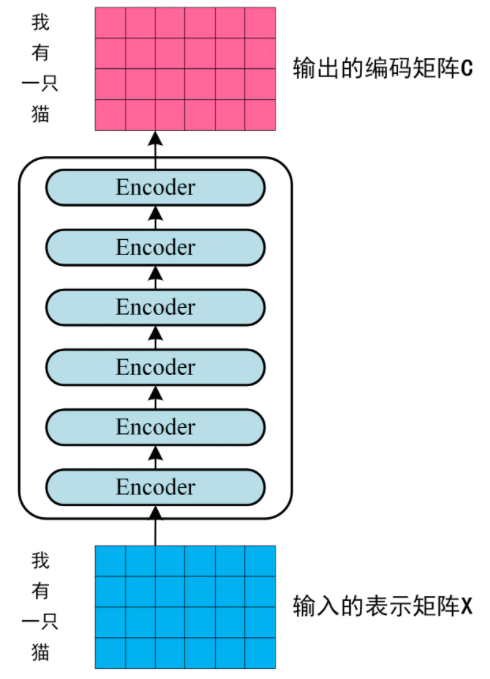
第一个 Encoder block 的输入为句子单词的表示向量矩阵,后续 Encoder block 的输入是前一个 Encoder block 的输出,最后一个 Encoder block 输出的矩阵就作为 整个Encoder部分的输出,如下图所示:
下期预告:Multi-Head Attention的详细
参考资源
链接:https://www.jianshu.com/p/9b87b945151e
《Attention Is All You Need》