神经网络的理论知识不是本文讨论的重点,假设读者们都是已经了解RNN的基本概念,并希望能用一些框架做一些简单的实现。这里推荐神经网络必读书目:邱锡鹏《神经网络与深度学习》。本文基于Pytorch简单实现CIFAR-10、MNIST手写体识别,读者可以基于此两个简单案例进行拓展,实现自己的深度学习入门。
环境说明
python 3.6.7
Pytorch的CUP版本
Pycharm编辑器
部分可能报错:参见pytorch安装错误及解决
基于Pytorch的CIFAR-10图片分类
代码实现
# coding = utf-8 import torch import torch.nn import numpy as np from torchvision.datasets import CIFAR10 from torchvision import transforms from torch.utils.data import DataLoader from torch.utils.data.sampler import SubsetRandomSampler import torch.nn.functional as F import torch.optim as optimizer ''' The compose function allows for multiple transforms. transform.ToTensor() converts our PILImage to a tensor of shape (C x H x W) in the range [0, 1] transform.Normalize(mean, std) normalizes a tensor to a (mean, std) for (R, G, B) ''' _task = transforms.Compose([ transforms.ToTensor(), transforms.Normalize([0.5, 0.5, 0.5], [0.5, 0.5, 0.5]) ]) # 注意:此处数据集在本地,因此download=False;若需要下载的改为True # 同样的,第一个参数为数据存放路径 data_path = '../CIFAR_10_zhuanzhi/cifar10' cifar = CIFAR10(data_path, train=True, download=False, transform=_task) # 这里只是为了构造取样的角标,可根据自己的思路进行拓展 # 此处使用了前百分之八十作为训练集,百分之八十到九十的作为验证集,后百分之十为测试集 samples_count = len(cifar) split_train = int(0.8 * samples_count) split_valid = int(0.9 * samples_count) index_list = list(range(samples_count)) train_idx, valid_idx, test_idx = index_list[:split_train], index_list[split_train:split_valid], index_list[split_valid:] # 定义采样器 # create training and validation, test sampler train_sampler = SubsetRandomSampler(train_idx) valid_sampler = SubsetRandomSampler(valid_idx) test_samlper = SubsetRandomSampler(test_idx ) # create iterator for train and valid, test dataset trainloader = DataLoader(cifar, batch_size=256, sampler=train_sampler) validloader = DataLoader(cifar, batch_size=256, sampler=valid_sampler) testloader = DataLoader(cifar, batch_size=256, sampler=test_samlper ) # 网络设计 class Net(torch.nn.Module): """ 网络设计了三个卷积层,一个池化层,一个全连接层 """ def __init__(self): super(Net, self).__init__() self.conv1 = torch.nn.Conv2d(3, 16, 3, padding=1) self.conv2 = torch.nn.Conv2d(16, 32, 3, padding=1) self.conv3 = torch.nn.Conv2d(32, 64, 3, padding=1) self.pool = torch.nn.MaxPool2d(2, 2) self.linear1 = torch.nn.Linear(1024, 512) self.linear2 = torch.nn.Linear(512, 10) # 前向传播 def forward(self, x): x = self.pool(F.relu(self.conv1(x))) x = self.pool(F.relu(self.conv2(x))) x = self.pool(F.relu(self.conv3(x))) x = x.view(-1, 1024) x = F.relu(self.linear1(x)) x = F.relu(self.linear2(x)) return x if __name__ == "__main__": net = Net() # 实例化网络 loss_function = torch.nn.CrossEntropyLoss() # 定义交叉熵损失 # 定义优化算法 optimizer = optimizer.SGD(net.parameters(), lr=0.01, weight_decay=1e-6, momentum=0.9, nesterov=True) # 迭代次数 for epoch in range(1, 31): train_loss, valid_loss = [], [] net.train() # 训练开始 for data, target in trainloader: optimizer.zero_grad() # 梯度置0 output = net(data) loss = loss_function(output, target) # 计算损失 loss.backward() # 反向传播 optimizer.step() # 更新参数 train_loss.append(loss.item()) net.eval() # 验证开始 for data, target in validloader: output = net(data) loss = loss_function(output, target) valid_loss.append(loss.item()) print("Epoch:{}, Training Loss:{}, Valid Loss:{}".format(epoch, np.mean(train_loss), np.mean(valid_loss))) print("======= Training Finished ! =========") print("Testing Begining ... ") # 模型测试 total = 0 correct = 0 for i, data_tuple in enumerate(testloader, 0): data, labels = data_tuple output = net(data) _, preds_tensor = torch.max(output, 1) total += labels.size(0) correct += np.squeeze((preds_tensor == labels).sum().numpy()) print("Accuracy : {} %".format(correct/total))
实验结果
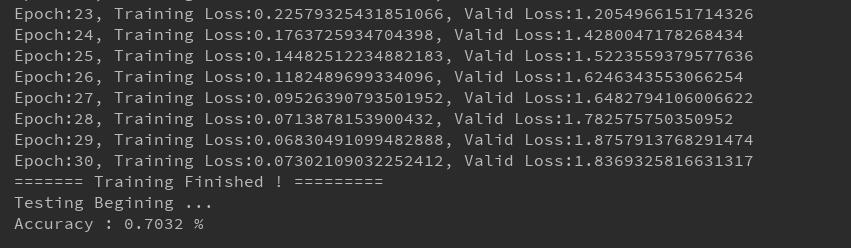
经验总结
1.激活函数的选择。
- 激活函数可选择sigmoid函数或者Relu函数,亲测使用Relu函数后,分类的正确率会高使用sigmoid函数很多;
- Relu函数的导入有两种:import torch.nn.functional as F, 然后F.relu(),还有一种是torch.nn.Relu() 两种方式实验结果没区别,但是推荐使用后者;因为前者是以函数的形式导入的,在模型保存时,F中相关参数会被释放,无法保存下去,而后者会保留参数。
2.预测结果的处理。
Pytorch预测的结果,返回的是一个Tensor,需要处理成数值才能进行准确率计算,.numpy()方法能将Tensor转化为数组,然后使用squeeze能够将数组转化为数值。
3. 数据加载。Pytorch是采用批量加载数据的,因此使用for循环迭代从采样器中加载数据,batch_size参数指定每次加载数据量的大小
4.注意维度。
- 网络设计中的维度。网络层次设计中,要谨记前一层的输出是后一层的输入,维度要对应的上。
- 全连接中的维度。全连接中要从特征图中选取特征,这些特征不是一维的,而全连接输出的结果是一维的,因此从特征图中选取特征作为全连接层输入前,需要将特征展开,例如:x = x.view(-1, 28*28)
基于Pytorch的MNIST手写体识别
代码实现
# coding = utf-8 import numpy as np import torch from torchvision import transforms _task = transforms.Compose([ transforms.ToTensor(), transforms.Normalize( [0.5], [0.5] ) ]) from torchvision.datasets import MNIST # 数据集加载 mnist = MNIST('./data', download=False, train=True, transform=_task) # 训练集和验证集划分 from torch.utils.data import DataLoader from torch.utils.data.sampler import SubsetRandomSampler # create training and validation split index_list = list(range(len(mnist))) split_train = int(0.8*len(mnist)) split_valid = int(0.9*len(mnist)) train_idx, valid_idx, test_idx = index_list[:split_train], index_list[split_train:split_valid], index_list[split_valid:] # create sampler objects using SubsetRandomSampler train_sampler = SubsetRandomSampler(train_idx) valid_sampler = SubsetRandomSampler(valid_idx) test_sampler = SubsetRandomSampler(test_idx) # create iterator objects for train and valid dataset trainloader = DataLoader(mnist, batch_size=256, sampler=train_sampler) validloader = DataLoader(mnist, batch_size=256, sampler=valid_sampler) test_loader = DataLoader(mnist, batch_size=256, sampler=test_sampler ) # design for net import torch.nn.functional as F class NetModel(torch.nn.Module): def __init__(self): super(NetModel, self).__init__() self.hidden = torch.nn.Linear(28*28, 300) self.output = torch.nn.Linear(300, 10) def forward(self, x): x = x.view(-1, 28*28) x = self.hidden(x) x = F.relu(x) x = self.output(x) return x if __name__ == "__main__": net = NetModel() from torch import optim loss_function = torch.nn.CrossEntropyLoss() optimizer = optim.SGD(net.parameters(), lr=0.01, weight_decay=1e-6, momentum=0.9, nesterov=True) for epoch in range(1, 12): train_loss, valid_loss = [], [] # net.train() for data, target in trainloader: optimizer.zero_grad() # forward propagation output = net(data) loss = loss_function(output, target) loss.backward() optimizer.step() train_loss.append(loss.item()) # net.eval() for data, target in validloader: output = net(data) loss = loss_function(output, target) valid_loss.append(loss.item()) print("Epoch:", epoch, "Training Loss:", np.mean(train_loss), "Valid Loss:", np.mean(valid_loss)) print("testing ... ") total = 0 correct = 0 for i, test_data in enumerate(test_loader, 0): data, label = test_data output = net(data) _, predict = torch.max(output.data, 1) total += label.size(0) correct += np.squeeze((predict == label).sum().numpy()) print("Accuracy:", (correct/total)*100, "%")
实验结果
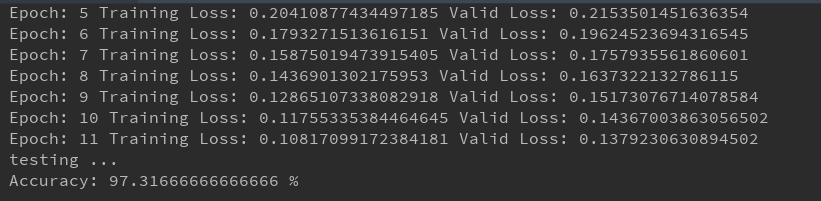
经验总结
1.网络设计的使用只用了一个隐层,单隐层神经网络经过10词迭代,对手写体识别准确率高达97%!!简直变态啊!
2.loss.item()和loss.data[0]。好像新版本的pytorch放弃了loss.data[0]的表达方式。
3.手写体识别的图片是单通道图片,因此在transforms.Compose()中做标准化的时候,只需要指定一个值即可;而cifar中的图片是三通道的,因此需要指定三个参数。