对于公司组织的人工智能学习,每周日一天课程共计五周,已经上了三次,一天课程下来讲了两本书的知识。发现老师讲的速度太快,深度不够,而且其他公司学员有的没有接触过python知识,所以有必要自己花时间多看视频整理知识点。还是得靠自己,厚积才能薄发。
无知者无畏,但是对于网上众多评价人工智能,很多人知识听起来感觉好高大上,但是深入学习后能劝退一大波人,所谓叶公好龙。

路漫漫,忍住寂寞苦学多练,才能在某天大放异彩。
以下为《Deep Learning Python--python深度学习》前三章中部分重要名称注解,共计九章。
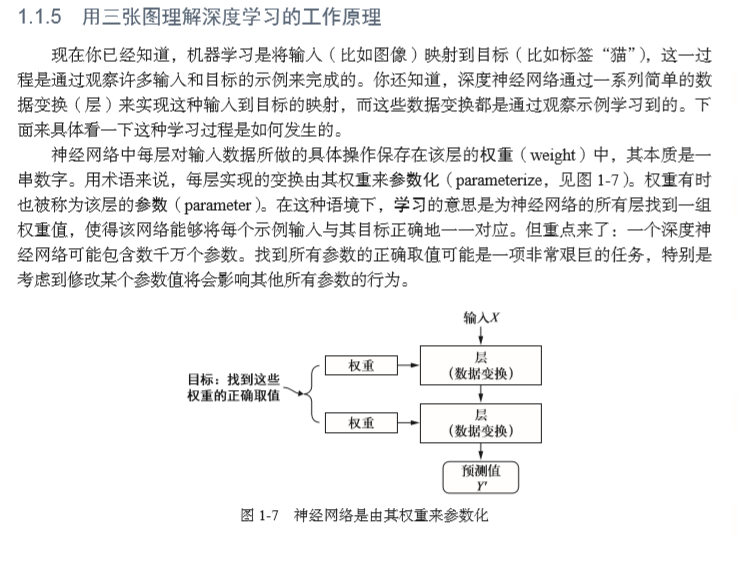
深度学习是机器学习的一个分支领域:它是从数据中学习表示的一种新方法,强调从连续 的层(layer)中进行学习,这些层对应于越来越有意义的表示。“深度学习”中的“深度”指 的并不是利用这种方法所获取的更深层次的理解,而是指一系列连续的表示层。数据模型中 包含多少层,这被称为模型的深度(depth)。这一领域的其他名称包括分层表示学习(layered representations learning)和层级表示学习(hierarchical representations learning)。
一、目前有三种技术力量在推动着机器学习的进步:
1、 硬件 2、 数据集和基准 3、 算法上的改进
二、深度学习的三个重要特质:
1、简单 2、可拓展 3、 多功能和可复用
三、基本概念知识点汇总(部分):
1、在机器学习中,分类问题中的某个类别叫作类(class)。数据点叫作样本(sample)。某 个样本对应的类叫作标签(label)。
2、数据集分为:
训练集 :模型将从这些数据中进行学习;
测试集:对模型进行测试 。
在训练和测试过程中需要监控的指标(metric):本例只关心精度,即正确分类的图像所 占的比例。
3、神经网络的核心组件是层(layer),它是一种数据处理模块,你可以将它看成数据过滤器。 (如:密集连接或叫全连接的神经层,softmax 层)
4、训练网络--编译(compile)步骤三个参数:
1. 损失函数(loss function):又叫(目标函数),网络如何衡量在训练数据上的性能,即网络如何朝着正确的 方向前进。 在训练过程中需要将其最小化。它能够衡量当前任务是否已 成功完成。
2. 优化器(optimezer)基于训练数据和损失函数来更新网络的机制。 决定如何基于损失函数对网络进行更新。它执行的是随机梯度下降(SGD) 的某个变体。
四、张量(tensor):
1、张量这一概念的核心在于,它是一个数据容器。它包含的数据几乎总是数值数据,因此它 是数字的容器。一般来说,当前所 有机器学习系统都使用张量作为基本数据结构。张量对这个领域非常重要,重要到Google 的 TensorFlow 都以它来命名。
2、张量详解:
- 张量(tensor):输入网络的数据存储对象。
- 张量的维度(dimension) 通常叫做轴(axis).
- 张量运算:层的组成要素。
- 梯度下降:可以让网络从训练样本中进行学习。
3、标量(0D张量):
- 标量:仅包含一个数字的张量叫做标量(scalar),也叫做标准张量,零维张量,0D张量。
- 标量张量有 0 个轴(ndim == 0)
- 张量轴的个数也叫做阶(rank)
4、向量(1D张量)
数字组成的数组叫做向量(vector) 或 一维张量(1D张量)
>>> x = np.array([12, 3, 6, 14, 7])
>>> x array([12, 3, 6, 14, 7])
5、矩阵(2D张量)
matrix /ˈmeɪtrɪks/ 矩阵 模型 metrics /ˈmetrɪks/ 指标。
向量组成的数组叫做叫矩阵(matrix)或二维张量(2D张量)
矩阵有 2 个轴(通常叫作行(row)和 列(column))
6、3D张量和更高维张量
将多个矩阵组合成一个新的数组,可以得到一个3D 张量,你可以将其直观地理解为数字 组成的立方体。
将多个3D 张量组合成一个数组,可以创建一个4D 张量,以此类推。深度学习处理的一般 是 0D 到 4D 的张量,但处理视频数据时可能会遇到 5D 张量。
五、关键属性
1、轴的个数(阶)。例如,3D 张量有3 个轴,矩阵有2 个轴。这在Numpy 等 Python 库中 也叫张量的 ndim。
2、形状。这是一个整数元组,表示张量沿每个轴的维度大小(元素个数)。例如,前面矩 阵示例的形状为 (3, 5),3D 张量示例的形状为 (3, 3, 5)。向量的形状只包含一个 元素,比如 (5,),而标量的形状为空,即 ()。
3、 数据类型(在Python 库中通常叫作 dtype)。这是张量中所包含数据的类型,例如,张 量的类型可以是 float32、uint8、float64 等。在极少数情况下,你可能会遇到字符 (char)张量。
注意,Numpy(以及大多数其他库)中不存在字符串张量,因为张量存 储在预先分配的连续内存段中,而字符串的长度是可变的,无法用这种方式存储。 为了具体说明,我们回头看一下 MNIST 例子中处理的数据。首先加载 MNIST 数据集
样本轴(sampile axis) 也叫 样本维度
批量轴(batch axis) 批量维度(batch dimension)
我们用几个你未来会遇到的示例来具体介绍数据张量。你需要处理的数据几乎总是以下类 别之一。
1、 向量数据:2D 张量,形状为 (samples, features)。
2、 时间序列数据或序列数据:3D 张量,形状为 (samples, timesteps, features)。
3、 图像:4D 张量,形状为 (samples, height, width, channels) 或(samples, channels, height, width)。
4、 视频:5D 张量,形状为 (samples, frames, height, width, channels) 或(samples, frames, channels, height, width)。
图像通常具有三个维度:高度、宽度和颜色深度。
点积运算也叫张量积(tensor product, 不要与逐元素的乘积弄混),是最常见也最有用的 张量运算。与逐元素的运算不同,它将输入张量的元素合并在一起。
在 Numpy、Keras、Theano 和 TensorFlow 中,都是用 * 实现逐元素乘积。TensorFlow 中的 点积使用了不同的语法,但在 Numpy 和 Keras 中,都是用标准的 dot 运算符来实现点积。
注意,两个向量之间的点积是一个标量,而且只有元素个数相同的向量之间才能做点积。
随机 stochastic /stə'kæstɪk/ 随机的,随机指标。
可微(differentiable) 梯度(gradient) 导数(derivative) /dɪˈrɪvətɪv/ 派生物;金融衍生产品;派生词;
梯度(gradient)是张量运算的导数。

多努力学习,出来混都是要还的,今年好多公司裁员,根本的问题都是自身能力和竞争力的问题,不要被生活扼住了喉咙!