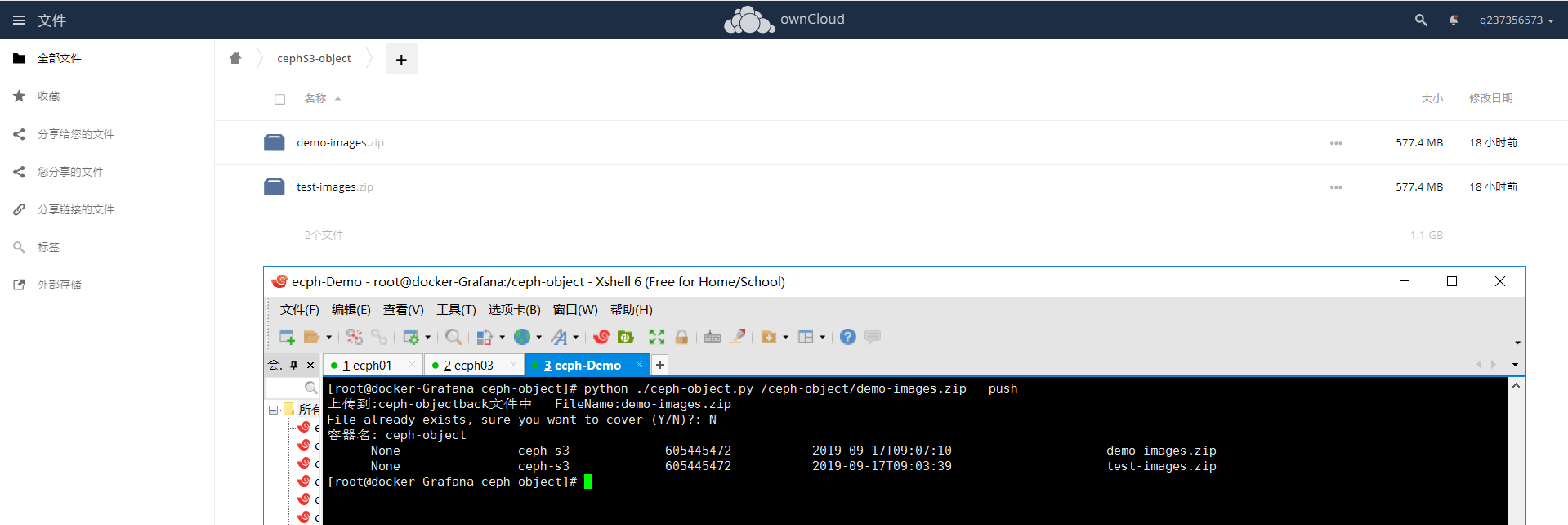
python version: python2.7
需要安装得轮子:
boto
filechunkio
command:
yum install python-pip&& pip install boto filechunkio
ceph集群user(ceph-s3) 和 用户access_key,secret_key
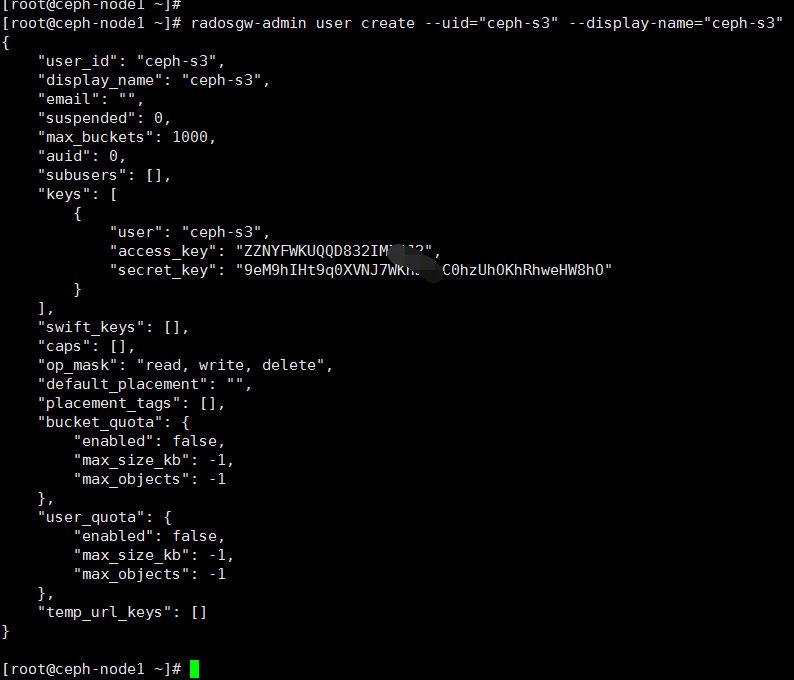
代码:
#_*_coding:utf-8_*_ #yum install python-boto import boto import boto.s3.connection #pip install filechunkio from filechunkio import FileChunkIO import math import threading import os import Queue import sys class Chunk(object): num = 0 offset = 0 len = 0 def __init__(self,n,o,l): self.num=n self.offset=o self.length=l
#条件判断工具类 class switch(object): def __init__(self, value): self.value = value self.fall = False def __iter__(self): """Return the match method once, then stop""" yield self.match raise StopIteration def match(self, *args): """Indicate whether or not to enter a case suite""" if self.fall or not args: return True elif self.value in args: # changed for v1.5, see below self.fall = True return True else: return False class CONNECTION(object): def __init__(self,access_key,secret_key,ip,port,is_secure=False,chrunksize=8<<20): #chunksize最小8M否则上传过程会报错 self.conn=boto.connect_s3( aws_access_key_id=access_key, aws_secret_access_key=secret_key, host=ip,port=port, is_secure=is_secure, calling_format=boto.s3.connection.OrdinaryCallingFormat() ) self.chrunksize=chrunksize self.port=port #查询buckets内files def list_all(self): all_buckets=self.conn.get_all_buckets() for bucket in all_buckets: print u'PG容器名: %s' %(bucket.name) for key in bucket.list(): print ' '*5,"%-20s%-20s%-20s%-40s%-20s" %(key.mode,key.owner.id,key.size,key.last_modified.split('.')[0],key.name) #查询所有buckets def get_show_buckets(self): for bucket in self.conn.get_all_buckets(): print "Ceph-back-Name: {name} CreateTime: {created}".format( name=bucket.name, created=bucket.creation_date, ) def list_single(self,bucket_name): try: single_bucket = self.conn.get_bucket(bucket_name) except Exception as e: print 'bucket %s is not exist' %bucket_name return print u'容器名: %s' % (single_bucket.name) for key in single_bucket.list(): print ' ' * 5, "%-20s%-20s%-20s%-40s%-20s" % (key.mode, key.owner.id, key.size, key.last_modified.split('.')[0], key.name) #普通小文件下载:文件大小<=8M def dowload_file(self,filepath,key_name,bucket_name): all_bucket_name_list = [i.name for i in self.conn.get_all_buckets()] if bucket_name not in all_bucket_name_list: print 'Bucket %s is not exist,please try again' % (bucket_name) return else: bucket = self.conn.get_bucket(bucket_name) all_key_name_list = [i.name for i in bucket.get_all_keys()] if key_name not in all_key_name_list: print 'File %s is not exist,please try again' % (key_name) return else: key = bucket.get_key(key_name) if not os.path.exists(os.path.dirname(filepath)): print 'Filepath %s is not exists, sure to create and try again' % (filepath) return if os.path.exists(filepath): while True: d_tag = raw_input('File %s already exists, sure you want to cover (Y/N)?' % (key_name)).strip() if d_tag not in ['Y', 'N'] or len(d_tag) == 0: continue elif d_tag == 'Y': os.remove(filepath) break elif d_tag == 'N': return os.mknod(filepath) try: key.get_contents_to_filename(filepath) except Exception: pass # 普通小文件上传:文件大小<=8M def upload_file(self,filepath,key_name,bucket_name): try: bucket = self.conn.get_bucket(bucket_name) except Exception as e: print 'bucket %s is not exist' % bucket_name tag = raw_input('Do you want to create the bucket %s: (Y/N)?' % bucket_name).strip() while tag not in ['Y', 'N']: tag = raw_input('Please input (Y/N)').strip() if tag == 'N': return elif tag == 'Y': self.conn.create_bucket(bucket_name) bucket = self.conn.get_bucket(bucket_name) all_key_name_list = [i.name for i in bucket.get_all_keys()] if key_name in all_key_name_list: while True: f_tag = raw_input(u'File already exists, sure you want to cover (Y/N)?: ').strip() if f_tag not in ['Y', 'N'] or len(f_tag) == 0: continue elif f_tag == 'Y': break elif f_tag == 'N': return key=bucket.new_key(key_name) if not os.path.exists(filepath): print 'File %s does not exist, please make sure you want to upload file path and try again' %(key_name) return try: f=file(filepath,'rb') data=f.read() key.set_contents_from_string(data) except Exception: pass #删除bucket内file def delete_file(self,key_name,bucket_name): all_bucket_name_list = [i.name for i in self.conn.get_all_buckets()] if bucket_name not in all_bucket_name_list: print 'Bucket %s is not exist,please try again' % (bucket_name) return else: bucket = self.conn.get_bucket(bucket_name) all_key_name_list = [i.name for i in bucket.get_all_keys()] if key_name not in all_key_name_list: print 'File %s is not exist,please try again' % (key_name) return else: key = bucket.get_key(key_name) try: bucket.delete_key(key.name) except Exception: pass #删除bucket def delete_bucket(self,bucket_name): all_bucket_name_list = [i.name for i in self.conn.get_all_buckets()] if bucket_name not in all_bucket_name_list: print 'Bucket %s is not exist,please try again' % (bucket_name) return else: bucket = self.conn.get_bucket(bucket_name) try: self.conn.delete_bucket(bucket.name) except Exception: pass #队列生成 def init_queue(self,filesize,chunksize): #8<<20 :8*2**20 chunkcnt=int(math.ceil(filesize*1.0/chunksize)) q=Queue.Queue(maxsize=chunkcnt) for i in range(0,chunkcnt): offset=chunksize*i length=min(chunksize,filesize-offset) c=Chunk(i+1,offset,length) q.put(c) return q #分片上传object def upload_trunk(self,filepath,mp,q,id): while not q.empty(): chunk=q.get() fp=FileChunkIO(filepath,'r',offset=chunk.offset,bytes=chunk.length) mp.upload_part_from_file(fp,part_num=chunk.num) fp.close() q.task_done() #文件大小获取---->S3分片上传对象生成----->初始队列生成(--------------->文件切,生成切分对象) def upload_file_multipart(self,filepath,key_name,bucket_name,threadcnt=8): filesize=os.stat(filepath).st_size try: bucket=self.conn.get_bucket(bucket_name) except Exception as e: print 'bucket %s is not exist' % bucket_name tag=raw_input('Do you want to create the bucket %s: (Y/N)?' %bucket_name).strip() while tag not in ['Y','N']: tag=raw_input('Please input (Y/N)').strip() if tag == 'N': return elif tag == 'Y': self.conn.create_bucket(bucket_name) bucket = self.conn.get_bucket(bucket_name) all_key_name_list=[i.name for i in bucket.get_all_keys()] if key_name in all_key_name_list: while True: f_tag=raw_input(u'File already exists, sure you want to cover (Y/N)?: ').strip() if f_tag not in ['Y','N'] or len(f_tag) == 0: continue elif f_tag == 'Y': break elif f_tag == 'N': return mp=bucket.initiate_multipart_upload(key_name) q=self.init_queue(filesize,self.chrunksize) for i in range(0,threadcnt): t=threading.Thread(target=self.upload_trunk,args=(filepath,mp,q,i)) t.setDaemon(True) t.start() q.join() mp.complete_upload() #文件分片下载 def download_chrunk(self,filepath,key_name,bucket_name,q,id): while not q.empty(): chrunk=q.get() offset=chrunk.offset length=chrunk.length bucket=self.conn.get_bucket(bucket_name) resp=bucket.connection.make_request('GET',bucket_name,key_name,headers={'Range':"bytes=%d-%d" %(offset,offset+length)}) data=resp.read(length) fp=FileChunkIO(filepath,'r+',offset=chrunk.offset,bytes=chrunk.length) fp.write(data) fp.close() q.task_done() #下载 > 8MB file def download_file_multipart(self,filepath,key_name,bucket_name,threadcnt=8): all_bucket_name_list=[i.name for i in self.conn.get_all_buckets()] if bucket_name not in all_bucket_name_list: print 'Bucket %s is not exist,please try again' %(bucket_name) return else: bucket=self.conn.get_bucket(bucket_name) all_key_name_list = [i.name for i in bucket.get_all_keys()] if key_name not in all_key_name_list: print 'File %s is not exist,please try again' %(key_name) return else: key=bucket.get_key(key_name) if not os.path.exists(os.path.dirname(filepath)): print 'Filepath %s is not exists, sure to create and try again' % (filepath) return if os.path.exists(filepath): while True: d_tag = raw_input('File %s already exists, sure you want to cover (Y/N)?' % (key_name)).strip() if d_tag not in ['Y', 'N'] or len(d_tag) == 0: continue elif d_tag == 'Y': os.remove(filepath) break elif d_tag == 'N': return os.mknod(filepath) filesize=key.size q=self.init_queue(filesize,self.chrunksize) for i in range(0,threadcnt): t=threading.Thread(target=self.download_chrunk,args=(filepath,key_name,bucket_name,q,i)) t.setDaemon(True) t.start() q.join() #生成下载URL def generate_object_download_urls(self,key_name,bucket_name,valid_time=0): all_bucket_name_list = [i.name for i in self.conn.get_all_buckets()] if bucket_name not in all_bucket_name_list: print 'Bucket %s is not exist,please try again' % (bucket_name) return else: bucket = self.conn.get_bucket(bucket_name) all_key_name_list = [i.name for i in bucket.get_all_keys()] if key_name not in all_key_name_list: print 'File %s is not exist,please try again' % (key_name) return else: key = bucket.get_key(key_name) try: key.set_canned_acl('public-read') download_url = key.generate_url(valid_time, query_auth=False, force_http=True) if self.port != 80: x1=download_url.split('/')[0:3] x2=download_url.split('/')[3:] s1=u'/'.join(x1) s2=u'/'.join(x2) s3=':%s/' %(str(self.port)) download_url=s1+s3+s2 print download_url except Exception: pass #操作对象 class ceph_object(object): def __init__(self,conn): self.conn=conn def operation_cephCluster(self,filepath,command): back = os.path.dirname(filepath).strip('/') path = os.path.basename(filepath) for case in switch(command): if case('delfile'): print "正在删除:"+back+"__BACK文件夹中___FileName:"+path self.conn.delete_file(path,back) self.conn.list_single(back) break if case('push'): #未实现超过8MB文件上传判断 print "上传到:"+back+"__BACK文件夹中___FileName:"+path self.conn.create_bucket(back) self.conn.upload_file_multipart(filepath,path,back) self.conn.list_single(back) break if case('pull'):#未实现超过8MB文件上传判断 print "下载:"+back+"back文件中___FileName:"++path conn.download_file_multipart(filepath,path,back) os.system('ls -al') break if case('delback'): print "删除:"+back+"-back文件夹" self.conn.delete_bucket(back) self.conn.list_all() break if case('check'): print "ceph-cluster所有back:" self.conn.get_show_buckets() break if case('checkfile'): self.conn.list_all() break if case('creaetback'): self.conn.create_bucket(back) self.conn.get_show_buckets() break if case(): # default, could also just omit condition or 'if True' print "something else! input null" # No need to break here, it'll stop anyway if __name__ == '__main__': access_key = 'ZZNYFWKUQQD832IMIGJ2' secret_key = '9eM9hIHt9q0XVNJ7WKhBPlC0hzUhOKhRhweHW8hO' conn=CONNECTION(access_key,secret_key,'192.168.100.23',7480) ceph_object(conn).operation_cephCluster(sys.argv[1], sys.argv[2]) #Linux 操作 # ceph_object(conn).operation_cephCluster('/my-first-s31-bucket/Linux.pdf','check')
在来张图吧:
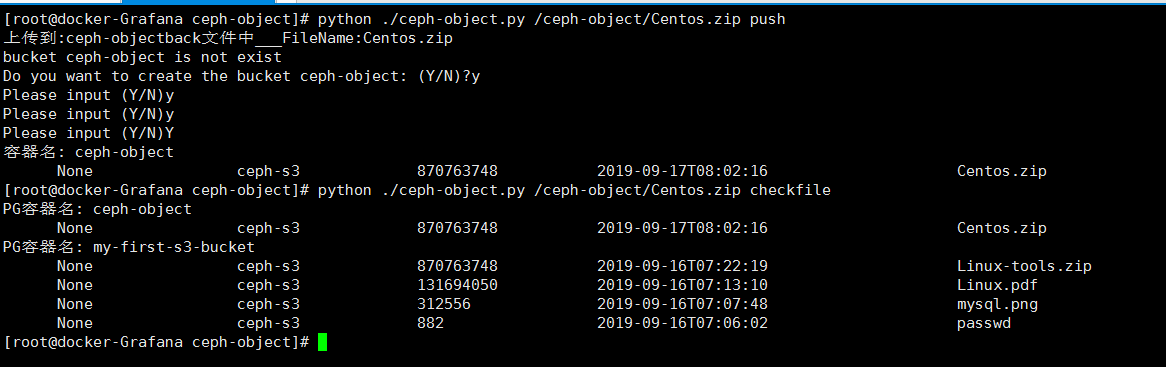
当然你还可以用docker , docker-compose 搭一个owncloud 实现对ceph-cluster WEB Ui界面管理
docker-compose 编排代码如下:
version: '2' services: owncloud: image: owncloud restart: always links: - mysql:mysql volumes: - "./owncloud-data/owncloud:/var/www/html/data" ports: - 80:80 mysql: image: migs/mysql-5.7 restart: always volumes: - "./mysql-data:/var/lib/mysql" ports: - 3306:3306 environment: MYSQL_ROOT_PASSWORD: "237356573" MYSQL_DATABASE: ownCloud
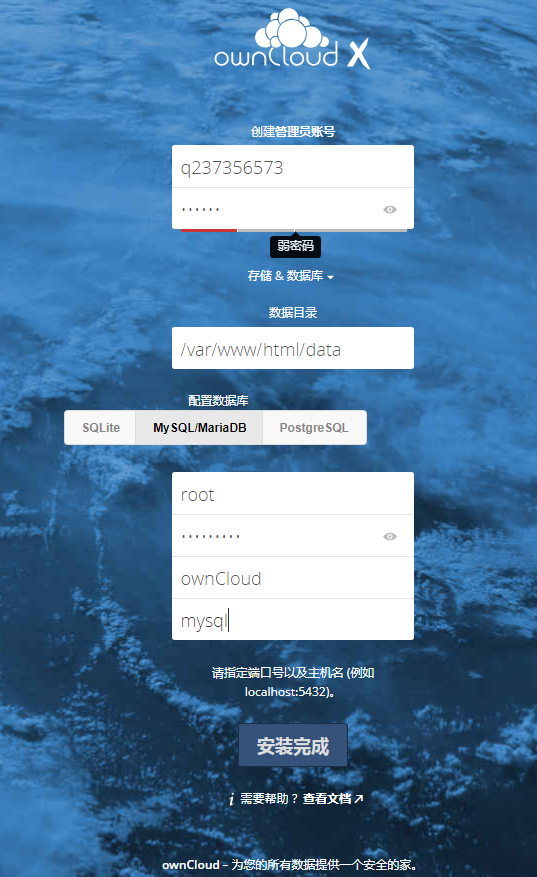
配置如下:
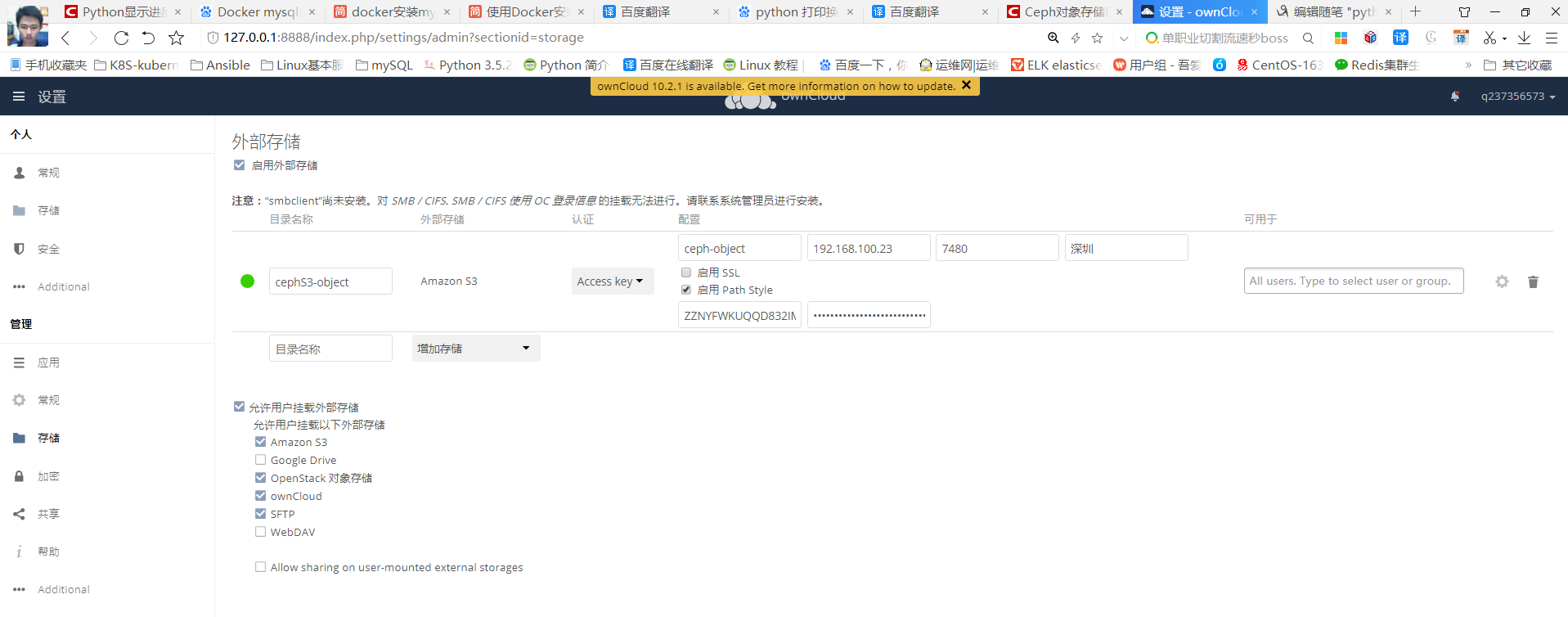
最终效果