参考:https://blog.csdn.net/qian2213762498/article/details/80558018
如果要测量中国人的平均身高,假设为μ,通常会随机取假设10000人,求得均值![]()
但是,![]() 不是最准的。那么,继续抽10000人,得到
不是最准的。那么,继续抽10000人,得到![]() 。
。
如此类推,一直抽![]() 。
。
当足够幸运,出现![]() ,平均的平均,更接近真值。
,平均的平均,更接近真值。
那么称![]() 为μ的无偏估计。
为μ的无偏估计。![]() 的含义是指一个集合,理解为矩阵也行。
的含义是指一个集合,理解为矩阵也行。
假设样本方差:
![]() ,假设第k次取样,那么有
,假设第k次取样,那么有![]() 和
和![]()
根据无偏估计的定义,那么样本方差的无偏估计为:
![]() ,同样S2 也是代指一个集合了。以下都要以集合的思想理解,而不是单一次样本,
,同样S2 也是代指一个集合了。以下都要以集合的思想理解,而不是单一次样本,

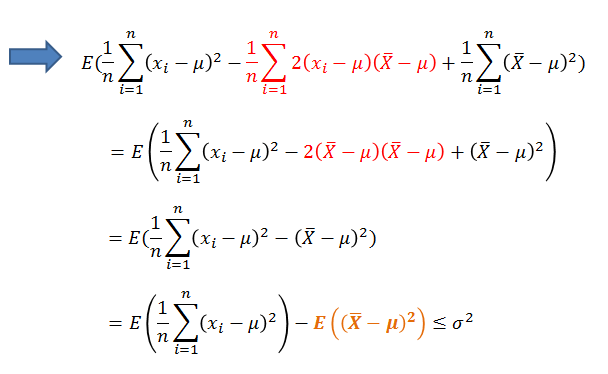
μ是已知的情况下:方差的定义:σ2 = ![]() ,
,
结果就是:E(S2) < σ2
证明2:
*测绘中,常使用[ ]符号代表∑
假设观测值为l1,l2,l3....ln
算术平均值为 L = ( l1 + l2 + l3 +...) / n = [l] / n
假设未知量的真值为x,那么,真误差 Δi = li - x
Δ1 + Δ2 + Δ3 + ....Δn = ( l1 + l2 + l3 +...) - nx
也就是
[ΔΔ] = [l] - nx
等价于
[ΔΔ] / n = [l] /n - x
真误差 Δi = li - x
由均值算得,改正数vi = L - li (这里是证明的关键)
两式子相加:
vi+ Δi = L - x
令 δ = L - x (1)
Δi = -vi + δ
那么将上式平方,然后求和
[ΔΔ] = [vv] - 2 δ [v] + nδ2
又按照正态分布,n接近无限,[v]=0; 注意,不是[vv]等于0,vv是恒为正,而v有正有负;
[ΔΔ] = [vv] + nδ2 (2)
根据(1)式子
δ = L - x = [l] / n - x = [l-x] / n = [Δ] / n
δ2 = [Δ]2 / n2 = [ (Δ12 + Δ22 + Δ32 +..Δn2) + 2Δ1Δ2 + 2Δ2Δ3 + .... + ] / n2
δ2 = [ΔΔ] / n2 + (2Δ1Δ2 + 2Δ2Δ3 + .... + ) / n2
又因为 (2Δ1Δ2 + 2Δ1Δ3 + 2Δ2Δ3 .... + ) / n2 = 0 因为ΔiΔj都是有正有负的。
δ2 = [ΔΔ] / n2
将(2)代入得
[ΔΔ] = [vv] - n([ΔΔ] / n2 )
[ΔΔ] = [vv] + [ΔΔ] / n
所以:
[ΔΔ] - [ΔΔ] / n = [vv]
[ΔΔ] (n-1) / n = [vv]
[ΔΔ] / n = [vv] / (n-1)
(证毕)
又有
L = ( l1 + l2 + l3 +...) / n = [l] / n
那么根据误差传播,L的方差
mL2 = 1 / n2 * m1 2 + 1 / n2 * m22 + 1 / n2 * m32 +... 1 / n2 * mn2
而因为l1 、 l2、 l3 为等精度独立观测,因此:m1 = m2 = m3 = m,m为单次观测值中误差
均值的精度: mL2 = m2 / n
而 m2 = [ΔΔ] / n
因此:[ΔΔ] / n = [vv] / (n-1) = m2 说明了在n很大的情况下, [vv] / (n-1) 能算得理论上的单次观测精度,从而也能算出均值L的精度。
注:上面是理论情况,是n很大的情况下,通常来说n都是比较少的,既然理论已经有了,就按照理论上的算,所以 [vv] / (n-1) 也只能说是“后验精度”了。