看vagan的tutorial居然看不懂=。=所以乖乖回来补锅
×××××××××××××××我是分割线×××××××××××××××××××××××××
参考这篇:http://www.r-tutor.com/r-introduction
R可以使用来自外部的数据,Excel, Minitab and SPSS files
赋值:=或<-
注释:#开头
模糊查询:apropos("what you want to search for")
帮助: help()
# 查看二元运算符的帮助
?'=='
# 记不清函数名字,所以用这个查看
apropos("mea")
缺失数据:
1)
v = c("Hockey", NA, "Lacros")
# 检查向量中是否有缺失值
is.na(v)
NA:可以代表各种类型。处理缺失数据可以采用multiple imputation,是通过mi,mice和Amelia包实现的。
2)
# z实际是1 3。仅有两个数字。 v = c(1, NULL, 3) # 判断是否为null is.null(v)
NULL:空白,不能存在于向量中。
(1)基本数据类型
Numeric:
class(x) #打印变量x的类型,如numeric啊什么什么的
is.numeric(x)
is.integer(k) #虽然给k赋值为1,但这个函数返回false
如果确实希望用整数,赋值时应该在数值后面加一个L。
i = 5L
Integer:
x = as.integer(3.14) # 将numeric转为integer,只取整数部分
y = as.integer("5.27") # 将数字字符串转为integer
boolValue = as.integer(TRUE) # boolValue = 1
boolValue = as.integer(FALSE) # boolValue = 0
Complex:
z = 1 + 2i sqrt(-1+0i) # 直接写-1会报错 sqrt(as.complex(-1)) # 或者转为负数再开方
Logical:
TRUE and FALSE
通过数字比较,&,|,!等产生,可以使用help("&")查看帮助
Character:
x = as.character(3.14) # 相当于string
# get length
nchar("hello")
# 5
nchar(123)
# 3
fname = "Joe"; lname = "Smith"
paste(fname, lname) # 输出"Joe Smith",字符串连接
sprintf("%s has %d dollars", "Sam", 100)
# 输出"Sam has 100 dollars",类似C语言
substr("Mary has a little lamb.", start=3, stop=12)
# 输出"ry has a l"。index从1开始,[start,stop]
sub("little", "big", "Mary has a little lamb.")
# 输出"Mary has a big lamb."。将句中首次出现的替换
help("sub")
# get help Info
日期:
Date用来存储日期(自1970年1月1日以来的天数),POSIXct存储日期与时间(秒数)。

可以使用lubridate和chron包来处理日期和时间。
(2)Vector
vector中的元素称为component,构造时有强制转换,优先级character > complex > numeric > integer > logical
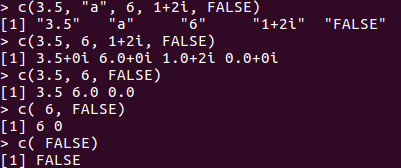
length(c(1,2)) # 给出长度
n = c(1,2,3); s = c("a", "b")
c(n,c) # 连接vector,注意类型的转化
5 * n #对每个元素乘除
# vector之间的+-*/都是对应元素的计算
# 如果两个vector的长度不同,短的会循环到与长的等长,再进行计算。warning
# 向量之间还可以比较大小,如x > y这种,比较对应元素,每个位置为TRUE FLASE
n[3]
# 输出3,因为index是1-based,而且类型是vector,只含有一个component
any(x < y)
# 检查所有元素中是否存在TRUE。
all(x < y)
# 检查所有元素中是否都是TRUE

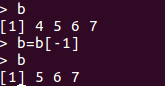
# negative index会去掉对应正值处的component
Numeric index vector

# 使用s[c(index)]对vector s进行切片,结果是vector
Logical index vector

# 使用与原vector等长的logical来表示每个位要不要,结果是vector
names()函数:给component起名字。起完就可以用名字引用了。

(2-2)factor因子向量
水平数是一个因子变量中不重复的元素的个数。R给一个因子的每个元素一个整数值,可以用as.numeric看。
f = as.factor(f)
as.numeric(f)
# 设置水平的顺序
factor(f, levels=c("A+","A-","A","B+","B-","C","F","D"),ordered=TRUE)
排序的部分不太懂,用到再说
(3)Matrix

# 构建,打印行,打印列,打印指定位置的
# 在构建时,如果不设byrow=TRUE,默认是按列存放的。

# 可以给行和列起名字,使用函数dimnames()

# transpose: t()

# 合并matrix: cbind和rbind函数

c(A) #将所有component写成一个vector,按列顺序写出
(4) List:vector contains objects
> n = c(1,2,3)
> s = c("a", "o", "e")
> b = c(TRUE, FALSE)
> x = list(n, s, b, -1) # x包含n,s,b和-1
x[3] # 引用
x[c(2, 4)] # 引用第二个和第四个元素
# 如果要直接引用x的元素,应当用[[index]],注意下面的区分。

给list成员起名字

# 使用[]时,里面的名字要带引号; v$one等价于v[[one]]
# 使用attach将某list加到R的search path中,则可以不指明list的名字,而直接用元素的名字
引用。detach则可以释放。

(5) Data Frame
data frame是存放了等长的vector的数据v结构,更像是表格,有header, data row, 每个小格为cell。构造时会按列存储。
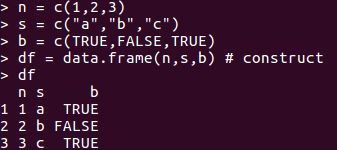
下面使用内置的mtcars为例子:
mtcars[1,2] mtcars["rowName", "colName"] # 引用cell
nrow(mtcars) ncol(mtcars) # 长度
head(mtcars) # 只打印前几行
mtcars[[9]] 或者mtcars[["colName"]] 或者mtcars$colName # 引用列
mtcars[,"am"] # 类似matrix中的情况,输出所有列名为am的cell的值
mtcars[1]或者mtcars["colName"]或者mtcars[c(1,2)] # 会包含各行的行名
mtcars[1, ] # 引用第一行。此处为[],所以会带各列的列名
# 其他方式类似列引用。
logical indexing

(6)导入数据
getwd() #获取工作路径
setwd("<new path>")
Excel File:
> library(gdata) # load gdata package
> help(read.xls) # documentation
> mydata = read.xls("mydata.xls") # read from first sheet返回data frame
或者使用XLConnect包。但是需要安装java
> library(XLConnect) # load XLConnect package
> wk = loadWorkbook("mydata.xls")
> df = readWorksheet(wk, sheet="Sheet1")
××××××××××××××××××××××××××下面的还木有试,需要再实验下×××××××××××××××××××××××××××××××××××××××××
Minitab File
If the data file is in Minitab Portable Worksheet format, it can be opened with the function read.mtp from the foreign package. It returns a list of components in the Minitab worksheet.
> help(read.mtp) # documentation
> mydata = read.mtp("mydata.mtp") # read from .mtp file
SPSS File
For the data files in SPSS format, it can be opened with the function read.spss also from the foreignpackage. There is a "to.data.frame" option for choosing whether a data frame is to be returned. By default, it returns a list of components instead.
> help(read.spss) # documentation
> mydata = read.spss("myfile", to.data.frame=TRUE)
Table File
A data table can resides in a text file. The cells inside the table are separated by blank characters. Here is an example of a table with 4 rows and 3 columns.
Now copy and paste the table above in a file named "mydata.txt" with a text editor. Then load the data into the workspace with the function read.table.
> mydata # print data frame
V1 V2 V3
1 100 a1 b1
2 200 a2 b2
3 300 a3 b3
4 400 a4 b4
For further detail of the function read.table, please consult the R documentation.
CSV File
The sample data can also be in comma separated values (CSV) format. Each cell inside such data file is separated by a special character, which usually is a comma, although other characters can be used as well.
The first row of the data file should contain the column names instead of the actual data. Here is a sample of the expected format.
After we copy and paste the data above in a file named "mydata.csv" with a text editor, we can read the data with the function read.csv.
> mydata
Col1 Col2 Col3
1 100 a1 b1
2 200 a2 b2
3 300 a3 b3
In various European locales, as the comma character serves as the decimal point, the function read.csv2should be used instead. For further detail of the read.csv and read.csv2 functions, please consult the R documentation.