批处理
- 新到达的数据元素被收集到一个组中。整个组在未来的时间进行处理,批量处理一定时间段,一定数量或者一定大小的数据组。
- 历史上,绝大多数数据处理技术都是为批处理而设计的。传统的数据仓库和Hadoop是专注于批处理的系统的两个常见示例。
- 数据先保存起来,然后分析(全量数据),批处理有延迟性,响应时间分钟分钟/小时计
流式处理
- 在流处理中,每一条新数据都会在到达时进行处理。与批处理不同,在下一批处理间隔之前不会等待,每一条数据将作为单独的碎片进行处理,数据到达时就要立即对其进行响应
- 有越来越多的系统设计用于流处理,包括Apache Storm和Apache Heron。 这些系统经常部署以支持近乎实时的事件处理。
- 数据及时处理,处理过后一般不保存,具有实时性,响应时间毫秒计
交互式处理
- 在商业智能领域少量更新和大量扫描分析场景,目前是Impala+Kudu/Hive/Spark SQL/Greenplum Mpp数据库在混战。
- 数据先保存起来,再进行处理,处理时一般查询部分数据,进行简单的统计分析,所以它所存取的是整个数据集的一部分
- 它的响应时间比批处理快得多,一般是秒级
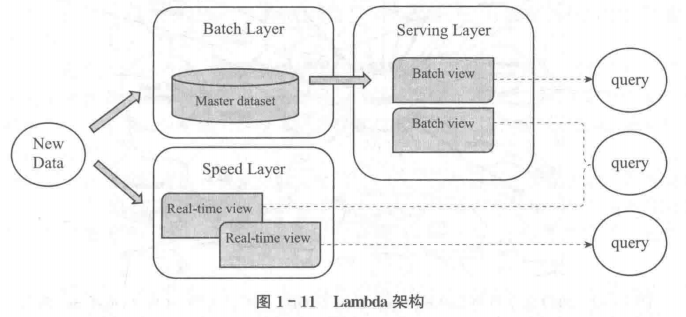
Lambda架构
批处理、流式数据处理、交互式处理等处理模式各有侧重,满足不同应用场合的需求,我们可以把这三种模式整合起来,这就是著名的Lambda架构。
关于更详细的架构及其他架构介绍内容可以参考这篇:
常用的大数据架构都有哪几种? - PurStar - 博客园
https://www.cnblogs.com/purstar/p/14136512.html
数据科学交流群,群号:189158789 ,欢迎各位对数据科学感兴趣的小伙伴的加入!