版权声明:本文由韩伟原创文章,转载请注明出处:
文章原文链接:https://www.qcloud.com/community/article/253
来源:腾云阁 https://www.qcloud.com/community
作者介绍:韩伟,1999年大学实习期加入初创期的网易,成为第30号员工,8年间从程序员开始,历任项目经理、产品总监。2007年后创业4年,开发过视频直播社区,及多款页游产品。2011年后就职于腾讯游戏研发部公共技术中心架构规划组,专注于通用游戏技术底层的研发。
架构的分析模型
一. 讨论的背景
现代电子游戏,基本上都会使用一定的网络功能。从验证正版,到多人交互等等,都需要架设一些专用的服务器,以及编写在服务器上的程序。因此,游戏服务器端软件的架构,本质上也是游戏服务器这个特定领域的软件架构。
软件架构的分析,可以通过不同的层面入手。比较经典的软件架构描述,包含了以下几种架构:
-
运行时架构——这种架构关心如何解决运行效率问题,通常以程序进程图、数据流图为表达方式。在大多数开发团队的架构设计文档中,都会包含运行时架构,说明这是一种非常重要的设计方面。这种架构也会显著的影响软件代码的开发效率和部署效率。本文主要讨论的是这种架构。
-
逻辑架构——这种架构关心软件代码之间的关系,主要目的是为了提高软件应对需求变更的便利性。人们往往会以类图、模块图来表达这种架构。这种架构设计在需要长期运营和重用性高的项目中,有至关重要的作用。因为软件的可扩展性和可重用度基本是由这个方面的设计决定的。特别是在游戏领域,需求变更的频繁程度,在多个互联网产业领域里可以说是最高的。本文会涉及一部分这种架构的内容,但不是本文的讨论重点。
-
物理架构——关心软件如何部署,以机房、服务器、网络设备为主要描述对象。
-
数据架构——关心软件涉及的数据结构的设计,对于数据分析挖掘,多系统协作有较大的意义。
-
开发架构——关心软件开发库之间的关系,以及版本管理、开发工具、编译构建的设计,主要为了提高多人协作开发,以及复杂软件库引用的开发效率。现在流行的集成构建系统就是一种开发架构的理论。
二. 游戏服务器架构的要素
服务器端软件的本质,是一个会长期运行的程序,并且它还要服务于多个不定时,不定地点的网络请求。所以这类软件的特点是要非常关注稳定性和性能。这类程序如果需要多个协作来提高承载能力,则还要关注部署和扩容的便利性;同时,还需要考虑如何实现某种程度容灾需求。由于多进程协同工作,也带来了开发的复杂度,这也是需要关注的问题。
功能约束,是架构设计决定性因素。一个万能的架构,必定是无能的架构。一个优秀的架构,则是正好把握了对应业务领域的核心功能产生的。游戏领域的功能特征,于服务器端系统来说,非常明显的表现为几个功能的需求:
-
对于游戏数据和玩家数据的存储
-
对玩家客户端进行数据广播
-
把一部分游戏逻辑在服务器上运算,便于游戏更新内容,以及防止外挂。
针对以上的需求特征,在服务器端软件开发上,我们往往会关注软件对电脑内存和CPU的使用,以求在特定业务代码下,能尽量满足承载量和响应延迟的需求。最基本的做法就是“时空转换”,用各种缓存的方式来开发程序,以求在CPU时间和内存空间上取得合适的平衡。在CPU和内存之上,是另外一个约束因素:网卡。网络带宽直接限制了服务器的处理能力,所以游戏服务器架构也必定要考虑这个因素。
对于游戏服务器架构设计来说,最重要的是利用游戏产品的需求约束,从而优化出对此特定功能最合适的“时-空”架构。并且最小化对网络带宽的占用。
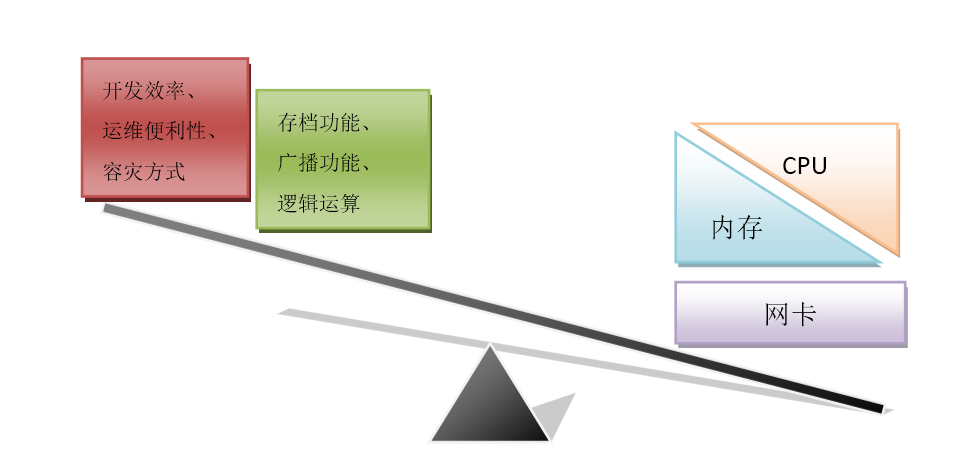
[图-游戏服务器的分析模型]
三. 核心的三个架构
基于上述的分析模型,对于游戏服务端架构,最重要的三个部分就是,如何使用CPU、内存、网卡的设计:
-
内存架构:主要决定服务器如何使用内存,以保证尽量少的内存泄漏的可能,以及最大化利用服务器端内存来提高承载量,降低服务延迟。
-
调度架构:设计如何使用进程、线程、协程这些对于CPU调度的方案。选择同步、异步等不同的编程模型,以提高服务器的稳定性和承载量。同时也要考虑对于开发带来的复杂度问题。现在出现的虚拟化技术,如虚拟机、docker、云服务器等,都为调度架构提供了更多的选择。
-
通信模式:决定使用何种方式通讯。网络通讯包含有传输层的选择,如TCP/UDP;据表达层的选择,如定义协议;以及应用层的接口设计,如消息队列、事件分发、远程调用等。
本文的讨论,也主要是集中于对以上三个架构的分析。
四. 游戏服务器模型的进化历程
最早的游戏服务器是比较简单的,如UO《网络创世纪》的服务端一张3.5寸软盘就能存下。基本上只是一个广播和存储文件的服务器程序。后来由于国内的外挂、盗版流行,各游戏厂商开始以MUD为模型,建立主要运行逻辑在服务器端的架构。这种架构在MMORPG类产品的不断更新中发扬光大,从而出现了以地图、视野等分布要素设计的分布式游戏服务器。而在另外一个领域,休闲游戏,天然的需要集中超高的在线用户,所以全区型架构开始出现。现代的游戏服务器架构,基本上都希望能结合承载量和扩展性的有点来设计,从而形成了更加丰富多样的形态。
本文的讨论主要是选取这些比较典型的游戏服务器模型,分析其底层各种选择的优点和缺点,希望能探讨出更具广泛性,更高开发效率的服务器模型。
分服模型
一. 模型描述
分服模型是游戏服务器中最典型,也是历久最悠久的模型。其特征是游戏服务器是一个个单独的世界。每个服务器的帐号是独立的,而且只用同一服务器的帐号才能产生线上交互。在早期服务器的承载量达到上限的时候,游戏开发者就通过架设更多的服务器来解决。这样提供了很多个游戏的“平行世界”,让游戏中的人人之间的比较,产生了更多的空间。所以后来以服务器的开放、合并形成了一套成熟的运营手段。一个技术上的选择最后导致了游戏运营方式的模式,是一个非常有趣的现象。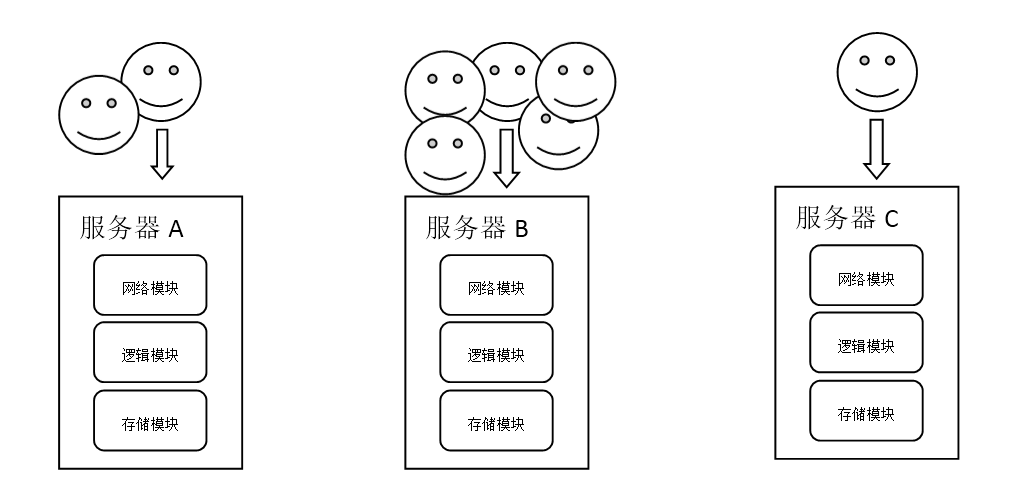
[图-分服模型]
二. 调度架构
-
单进程游戏服务器
最简单的游戏服务器只有一个进程,是一个单点。这个进程如果退出,则整个游戏世界消失。在此进程中,由于需要处理并发的客户端的数据包,因此产生了多种选择方法: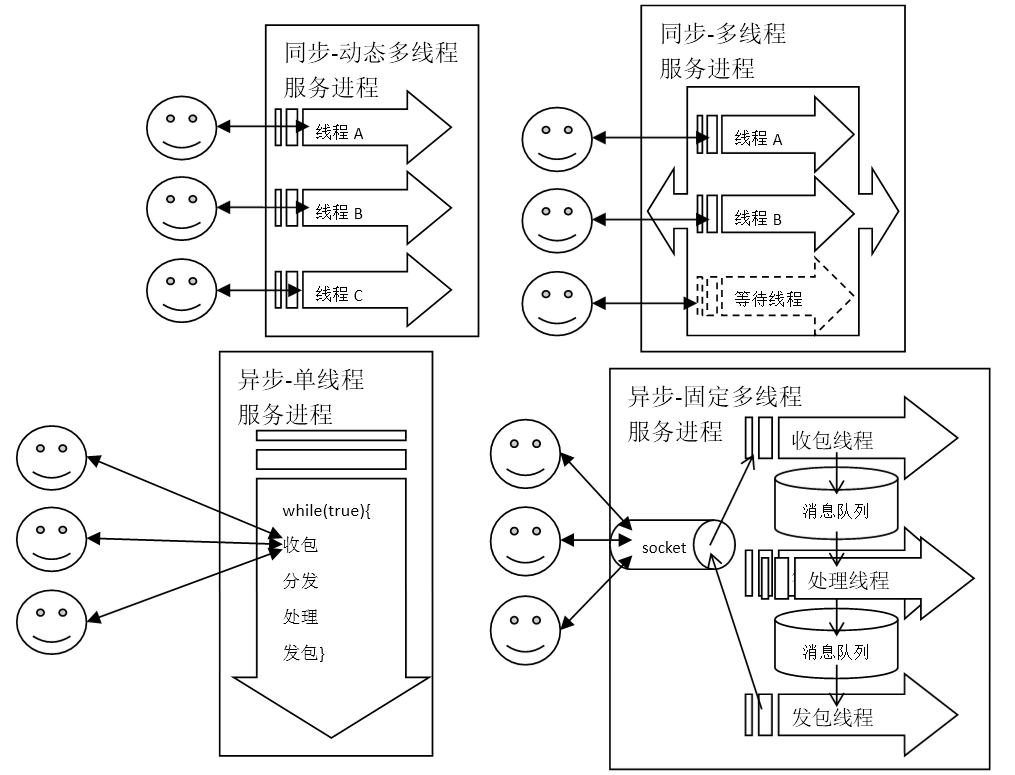
[图-单进程调度模型]-
同步-动态多线程:每接收一个用户会话,就建立一个线程。这个用户会话往往就是由客户端的TCP连接来代表,这样每次从socket中调用读取或写出数据包的时候,都可以使用阻塞模式,编码直观而简单。有多少个游戏客户端的连接,就有多少个线程。但是这个方案也有很明显的缺点,就是服务器容易产生大量的线程,这对于内存占用不好控制,同时线程切换也会造成CPU的性能损失。更重要的多线程下对同一块数据的读写,需要处理锁的问题,这可能让代码变的非常复杂,造成各种死锁的BUG,影响服务器的稳定性。
-
同步-多线程池:为了节约线程的建立和释放,建立了一个线程池。每个用户会话建立的时候,向线程池申请处理线程的使用。在用户会话结束的时候,线程不退出,而是向线程池“释放”对此线程的使用。线程池能很好的控制线程数量,可以防止用户暴涨下对服务器造成的连接冲击,形成一种排队进入的机制。但是线程池本身的实现比较复杂,而“申请”、“施放”线程的调用规则需要严格遵守,否则会出现线程泄露,耗尽线程池。
-
异步-单线程/协程:在游戏行业中,采用Linux的epoll作为网络API,以期得到高性能,是一个常见的选择。游戏服务器进程中最常见的阻塞调用就是网路IO,因此在采用epoll之后,整个服务器进程就可能变得完全没有阻塞调用,这样只需要一个线程即可。这彻底解决了多线程的锁问题,而且也简化了对于并发编程的难度。但是,“所有调用都不得阻塞”的约束,并不是那么容易遵守的,比如有些数据库的API就是阻塞的;另外单进程单线程只能使用一个CPU,在现在多核多CPU的服务器情况下,不能充分利用CPU资源。异步编程由于是基于“回调”的方式,会导致要定义很多回调函数,并且把一个流程里面的逻辑,分别写在多个不同的回调函数里面,对于代码阅读非常不理。——针对这种编码问题,协程(Coroutine)能较好的帮忙,所以现在比较流行使用异步+协程的组合。不管怎样,异步-单线程模型由于性能好,无需并发思维,依然是现在很多团队的首选。
-
异步-固定多线程:这是基于异步-单线程模型进化出来的一种模型。这种模型一般有三类线程:主线程、IO线程、逻辑线程。这些线程都在内部以全异步的方式运行,而他们之间通过无锁消息队列通信。
-
-
多进程游戏服务器
多进程的游戏服务器系统,最早起源于对于性能问题需求。由于单进程架构下,总会存在承载量的极限,越是复杂的游戏,其单进程承载量就越低,因此开发者们一定要突破进程的限制,才能支撑更复杂的游戏。
一旦走上多进程之路,开发者们还发现了多进程系统的其他一些好处:能够利用上多核CPU能力;利用操作系统的工具能更仔细的监控到运行状态、更容易进行容灾处理。多进程系统比较经典的模型是“三层架构”:
在多进程架构下,开发者一般倾向于把每个模块的功能,都单独开发成一个进程,然后以使用进程间通信来协调处理完整的逻辑。这种思想是典型的“管道与过滤器”架构模式思想——把每个进程看成是一个过滤器,用户发来的数据包,流经多个过滤器衔接而成的管道,最后被完整的处理完。由于使用了多进程,所以首选使用单进程单线程来构造其中的每个进程。这样对于程序开发来说,结构清晰简单很多,也能获得更高的性能。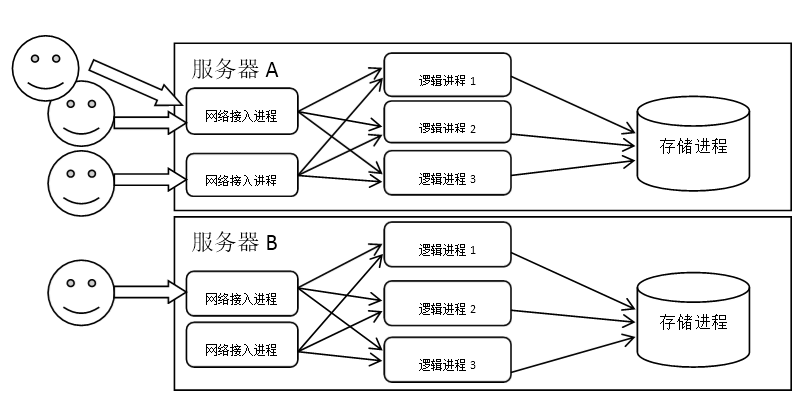
[图-经典的三层模型]尽管有很多好处,但是多进程系统还有一个需要特别注意的问题——数据存储。由于要保证数据的一致性,所以存储进程一般都难以切分成多个进程。就算对关系型数据做分库分表处理,也是非常复杂的,对业务类型有依赖的。而且如果单个逻辑处理进程承载不了,由于其内存中的数据难以分割和同步,开发者很难去平行的扩展某个特定业务逻辑。他们可能会选择把业务逻辑进程做成无状态的,但是这更加加重了存储进程的性能压力,因为每次业务处理都要去存储进程处拉取或写入数据。
除了数据的问题,多进程也架构也带来了一系列运维和开发上的问题:首先就是整个系统的部署更为复杂了,因为需要对多个不同类型进程进行连接配置,造成大量的配置文件需要管理;其次是由于进程间通讯很多,所以需要定义的协议也数量庞大,在单进程下一个函数调用解决的问题,在多进程下就要定义一套请求、应答的协议,这造成整个源代码规模的数量级的增大;最后是整个系统被肢解为很多个功能短小的代码片段,如果不了解整体结构,是很难理解一个完整的业务流程是如何被处理的,这让代码的阅读和交接成本巨高无比,特别是在游戏领域,由于业务流程变化非常快,几经修改后的系统,几乎没有人能完全掌握其内容。
三. 内存架构
由于服务器进程需要长期自动化运行,所以内存使用的稳定是首要大事。在服务器进程中,就算一个触发几率很小的内存泄露,都会积累起来变成严重的运营事故。需要注意的是,不管你的线程和进程结构如何,内存架构都是需要的,除非是Erlang这种不使用堆的函数式语言。
-
动态内存
在需要的时候申请内存来处理问题,是每个程序员入门的时候必然要学会的技能。但是,如何控制内存释放却是一个大问题。在C/C++语言中,对于堆的控制至关重要。有一些开发者会以树状来规划内存使用,就是一般只new/delete一个主要的类型的对象,其他对象都是此对象的成员(或者指针成员),只要这棵树上所有的对象都管理好自己的成员,就不会出现内存漏洞,整个结构也比较清晰简单。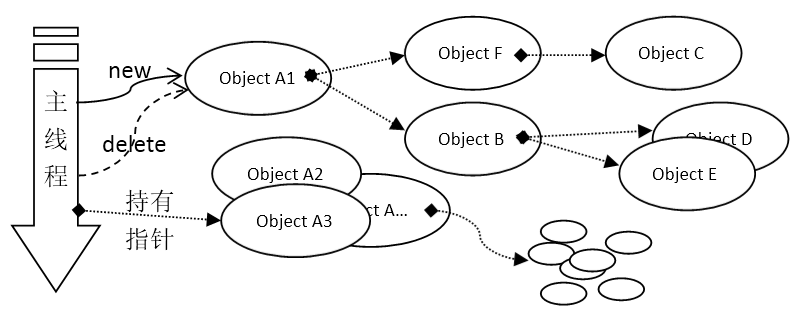
[图-对象树架构]在Objective C语言中,有所谓autorealse的特性,这种特性实际上是一种引用计数的技术。由于能配合在某个调度模型下,所以使用起来会比较简单。同样的思想,有些开发者会使用一些智能指针,配合自己写的框架,在完整的业务逻辑调用后一次性清理相关内存。
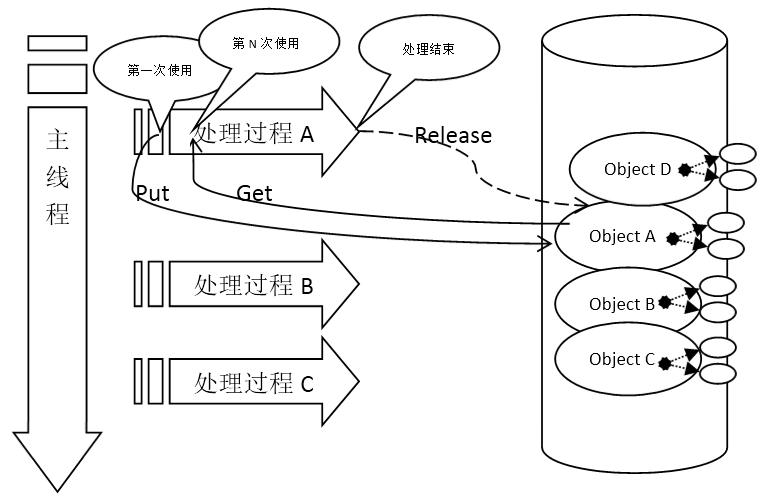
[图-根据业务处理调度管理内存池]在带虚拟机的语言中,最常见的是JAVA,这个问题一般会简单一些,因为有自动垃圾回收机制。但是,JAVA中的容器类型、以及static变量依然是可能造成内存泄露的原因。加上无规划的使用线程,也有可能造成内存的泄露——有些线程不会退出,而且在不断增加,最后耗尽内存。所以这些问题都要求开发者专门针对static变量以及线程结构做统一设计、严格规范。
-
预分配内存
动态分配内存在小心谨慎的程序员手上,是能发挥很好的效果的。但是游戏业务往往需要用到的数据结构非常多,变化非常大,这导致了内存管理的风险很高。为了比较彻底的解决内存漏洞的问题,很多团队采用了预先分配内存的结构。在服务器启动的时候分配所有的变量,在运行过程中不调用任何new关键字的代码。这样做的好处除了可以有效减少内存漏洞的出现概率,也能降低动态分配内存所消耗的性能。同时由于启动时分配内存,如果硬件资源不够的话,进程就会在启动时失败,而不是像动态分配内存的程序一样,可能在任何一个分配内存的时候崩溃。然而,要获得这些好处,在编码上首先还是要遵循“动态分配架构”中对象树的原则,把一类对象构造为“根”对象,然后用一个内存池来管理这些根对象。而这个内存池能存放的根对象的数目,就是此服务进程的最大承载能力。一切都是在启动的时候决定,非常的稳妥可靠。
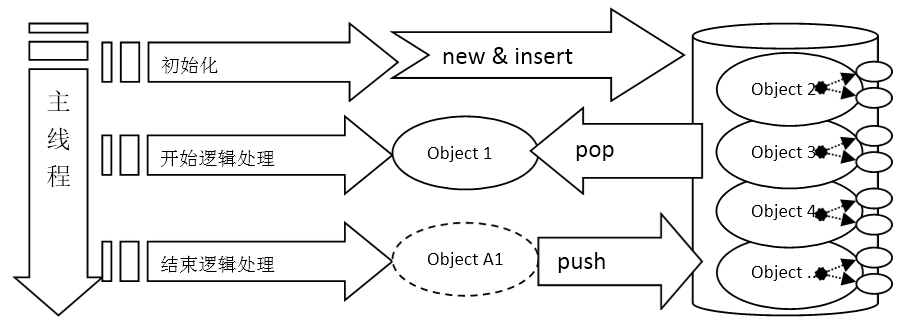
[图-预分配内存池]不过这样做,同样有一些缺点:首先是不太好部署,比如你想在某个资源较小的虚拟机上部署一套用来测试,可能一位内没改内存池的大小,导致启动不成功。每次更换环境都需要修改这个配置。其次,是所有的用到的类对象,都要在根节点对象那里有个指针或者引用,否则就可能泄漏内存。由于对于非基本类型的对象,我们一般不喜欢用拷贝的方式来作为函数的参数和返回值,而指针和应用所指向的内存,如果不能new的话,只能是现成的某个对象的成员属性。这回导致程序越复杂,这类的成员属性就越多,这些属性在代码维护是一个不小的负担。
要解决以上的缺点,可以修改内存池的实现,为动态增长,但是具备上限的模型,每次从内存池中“获取”对象的时候才new。这样就能避免在小内存机器上启动不了的问题。对于对象属性复杂的问题,一般上需要好好的按面向对象的原则规划代码,做到尽量少用仅仅表示函数参数和返回值的属性,而是主要是记录对象的“业务状态”属性为主,多花点功夫在构建游戏的数据模型上。
四. 进程间通讯手段
在多进程的系统中,进程间如何通讯是一个至关重要的问题,其性能和使用便利性,直接决定了多进程系统的技术效能。
-
Socket通讯
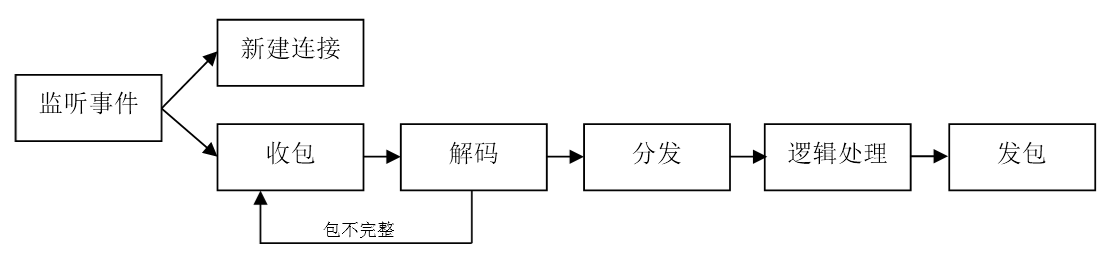
TCP/IP协议是一种通用的、跨语言、跨操作系统、跨机器的通讯方案。这也是开发者首先想到的一种手段。在使用上,有使用TCP和UDP两个选择。一般我们倾向在游戏系统中使用TCP,因为游戏数据的逻辑相关性比较强,UDP由于可能存在的丢包和重发处理,在游戏逻辑上的处理一般比较复杂。由于多进程系统的进程间网络一般情况较好,UDP的性能优势不会特别明显。要使用TCP做跨进程通讯,首先就是要写一个TCP Server,做端口监听和连接管理;其次需要对可能用到的通信内容做协议定制;最后是要编写编解码和业务逻辑转发的逻辑。这些都完成了之后,才能真正的开始用来作为进程间通信手段。
使用Socket编程的好处是通用性广,你可以用来实现任何的功能,和任何的进程进行协作。但是其缺点也异常明显,就是开发量很大。虽然现在有一些开源组件,可以帮你简化Socket Server的编写工作,简化连接管理和消息分发的处理,但是选择目标建立连接、定制协议编解码这两个工作往往还是要自己去做。游戏的特点是业务逻辑变化很多,导致协议修改的工作量非常大。因此我们除了直接使用TCP/IP socket以外,还有很多其他的方案可以尝试。
[图-TCP通讯] -
消息队列
在多进程系统中,如果进程的种类比较多,而且变化比较快,大量编写和配置进程之间的连接是一件非常繁琐的工作,所以开发者就发明了一种简易的通讯方法——消息队列。这种方法的底层还是Socket通讯实现,但是使用者只需要好像投递信件一样,把消息包投递到某个“信箱”,也就是队列里,目标进程则自动不断去“收取”属于自己的“信件”,然后触发业务处理。这种模型的好处是非常简单易懂,使用者只需要处理“投递”和“收取”两个操作即可,对于消息也只需要处理“编码”和“解码”两个部分。在J2EE规范中,就有定义一套消息队列的规范,叫JMS,Apache ActiveMQ就是一个应用广泛的实现者。在Linux环境下,我们还可以利用共享内存,来承担消息队列的存储器,这样不但性能很高,而且还不怕进程崩溃导致未处理消息丢失。
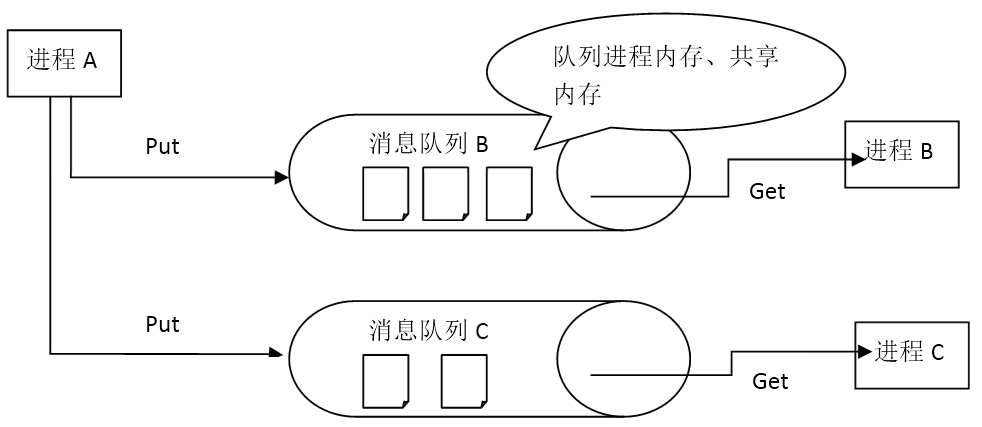
[图-消息队列]需要注意的是,有些开发者缺乏经验,使用了数据库,如MySQL,或者是NFS这类运行效率比较低的媒介作为队列的存储者。这在功能上虽然可以行得通,但是操作一频繁,就难以发挥作用了。如以前有一些手机短信应用系统,就用MySQL来存储“待发送”的短信。
消息队列虽然非常好用,但是我们还是要自己对消息进行编解码,并且分发给所需要的处理程序。在消息到处理程序之间,存在着一个转换和对应的工作。由于游戏逻辑的繁多,这种对应工作完全靠手工编码,是比较容易出错的。所以这里还有进一步的改进空间。
-
远程调用
有一些开发者会希望,在编码的时候完全屏蔽是否跨进程在进行调用,完全可以好像调用本地函数或者本地对象的方法一样。于是诞生了很多远程调用的方案,最经典的有Corba方案,它试图实现能在不同语言的代码直接,实现远程调用。JAVA虚拟机自带了RMI方案的支持,在JAVA进程之间远程调用是比较方便的。在互联网的环境下,还有各种Web Service方案,以HTTP协议作为承载,WSDL作为接口描述。使用远程调用的方案,最大好处是开发的便捷,你只需要写一个函数,就能在任何一个其他进程上对此函数进行调用。这对游戏开发来说,就解决了多进程方案最大的一个开发效率问题。但是这种便捷是有成本的:一般来说,远程调用的性能会稍微差一点,因为需要用一套统一的编解码方案。如果你使用的是C/C++这类静态语言,还需要使用一种IDL语言来先描述这种远程函数的接口。但是这些困难带来的好处,在游戏开发领域还是非常值得的。
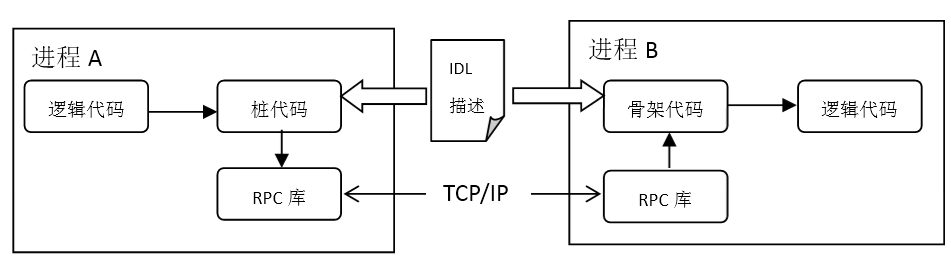
[图-远程调用]
五. 容灾和扩容手段
在多进程模型中,由于可以采用多台物理服务器来部署服务进程,所以为容灾和扩容提供了基础条件。
在单进程模型下,容灾常常使用的热备服务器,依然可以在多进程模型中使用,但是开着一台什么都不做的服务器完全是为了做容灾,多少有点浪费。所以在多进程环境下,我们会启动多个相同功能的服务器进程,在请求的时候,根据某种规则来确定对哪个服务进程发起请求。如果这种规则能规避访问那些“失效”了的服务进程,就自动实现了容灾,如果这个规则还包括了“更新新增服务进程”的逻辑,就可以做到很方便的扩容了。而这两个规则,统一起来就是一条:对服务进程状态的集中保存和更新。
为了实现上面的方案,常常会架设一个“目录”服务器进程。这个进程专门负责搜集服务器进程的状态,并且提供查询。ZooKeeper就是实现这种目录服务器的一个优秀工具。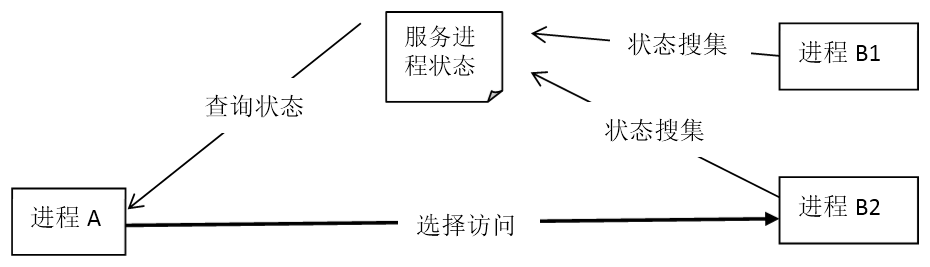
[图-服务器状态管理]
尽管用简单的目录服务器可以实现大部分容灾和扩容的需求,但是如果被访问进程的内存中有数据存在,那么问题就比较复杂了。对于容灾来说,新的进程必须要有办法重建那个“失效”了的进程内存中的数据,才可能完成容灾功能;对于扩容功能来说,新加入的进程,也必须能把需要的数据载入到自己的内存中才行,而这些数据,可能已经存在于其他平行的进程中,如何把这部分数据转移过来,是一个比较耗费性能和需要编写相当多代码的工作。——所以一般我们喜欢对“无状态”的进程来做扩容和容灾。