Map接口(包含HashMap和TreeMap)
Collection集合接口(包含List接口和Set接口)
List线性表接口(包含ArrayList和LinkedList)
Set集合接口(包含HashSet和TreeSet)
Map:
Java中使用Map接口描述映射结构,映射Map是一个独立的接口,描述的是键键值对关系,Map不允许键重复,并且每个键只能对应一个值。
常用方法:
size();获取Map尺寸(即包含的键值对数)
put(Object key,Object value);向Map中添加键值对
remove(Object key);根据key删除对应的键值对,返回被删除的值
get(Object key);根据key获取对应的value值
containKey(Object key);判断Map中是否包含该键key
keySet();返回所有的键组成的集合
entrySet();将Map中的键值对存入到集合中,该集合中的元素类型是entry
entry的元素类型和map一样
entry常用方法:
getKey();获取当前的键
getValue();获取当前的值
values();返回Map中的所有值组成的collection对象
(1).HashMap:
HashMap通过hash算法排布存储Map中的键(key),HashMap也是最常用的图状数据结构,其存储的数据元素是成对出现的,也就是说每一个键(key)对应一个值(value)。 HashMap中的数据元素不是按照我们添加的顺序排布的,并且其内存模式也不是连续的,但是其key值的排布是根据Hash算法获得的,所以在数据元素的检索方面速度还是较快的。 HashMap不能直接装入迭代器,必须将HashMap的所有键key装入迭代器,再进行遍历,或者是使用Entry类,将所有数据元素转化为Entry的集合进行处理。
HashMap不允许出现重复的键(key),并且每个键(key)只能对应一个值(value)
(2).TreeMap:
TreeMap是一种有序的映射关系,即每对键key-值value在TreeMap中是有序排列的,并且这个序列遵循自然序列,当我们向TreeMap插入新的数据元素时,TreeMap可能会重新排序,所以TreeMap中的任何元素在整个映射组中是不固定的。
当我们的TreeMap键(key)是自定义类时,需要在自定义类中重写compareTo方法,以提供比对形式,否在TreeMap不能对用户自定义的类型的键(key)进行正确的树状排序,也就不能对整个键值对起到有效的排序效果。
TreeMap的一些特殊方法:
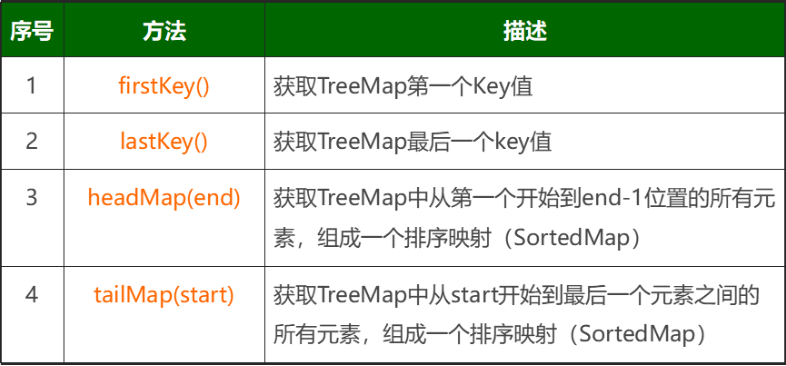
线性表之顺序表ArrayList:
ArrayList是大小可变的动态数组,其遍历效率高,更新效率较低;
常用的方法如下:
获取ArrayList的长度(包含的元素个数)方法:size(); return int
向ArrayList尾部添加元素方法:add(Object o); void
向ArrayList指定位置添加元素方法:add(int i,Object o); void
用新元素替换ArrayList指定位置的元素的方法:set(int i,Object newo); return 原有的元素值
删除ArrayList指定位置的元素的方法:remove(int i); return 被删除的元素
获取ArrayList指定位置的元素的方法:get(int i);
线性表之链表LinkedList:
LinkedList是使用指针关联的双向链表,其获取下一个元素的方式是通过指向下一个元素的地址对象(通常叫做指针)获取的,由于它的链式存储结构,LinkedList在任意位置的元素插入(或删除)效率都比较快,因为元素插入(或删除)不需要移动LinkedList中的其它元素,当需要一个频繁插入(或删除)的线性结构时,首选的List实现类应该是LinkedList。 1.LinkedList对于ArrayList来说,其遍历速度较慢,因为他获取下一个元素的时间为寻址时间。
2.LinkedList适合存储数据元素变动较大的线性集合,可以更快速的对指定位置的元素进行增加、删除、修改和查询功能。
常用的方法如下:
获取LinkedList的长度(包含的元素个数)方法:size(); return int
向LinkedList尾部添加元素方法:add(Object o); void
向LinkedList指定位置添加元素方法:add(int i,Object o); void
用新元素替换LinkedList指定位置的元素的方法:set(int i,Object newo); return 原有的元素值
删除LinkedList指定位置的元素的方法:remove(int i); return 被删除的元素
获取LinkedList指定位置的元素的方法:get(int i);
动态数组Vector:
Vector是一个Object类型的可变长的数组,其元素类型可以是任意的数据类型(Object的子类),我们使用Vector通常是存储元素类型不同,但描述对象又统一的集合。
Vector与ArrayList的区别是Vector是线程安全的,故Vector相对于ArrayList的速度稍慢一些。
其用法与ArrayList基本相同;
常用的方法如下:
获取LinkedList的长度(包含的元素个数)方法:size(); return int
向LinkedList尾部添加元素方法:add(Object o); void
向LinkedList指定位置添加元素方法:add(int i,Object o); void
用新元素替换LinkedList指定位置的元素的方法:set(int i,Object newo); return 原有的元素值
删除LinkedList指定位置的元素的方法:remove(int i); return 被删除的元素
获取LinkedList指定位置的元素的方法:get(int i);
Set:
Java中使用Set接口描述一个集合,集合Set是Collection的子接口,Set不允许其数据元素重复出现,也就是说在Set中每一个数据元素都是唯一的。
另外Set中的元素是散列分布的,所以其没有位置索引;
Set接口定义的常用方法如下:
获取set的长度(包含的元素个数)方法:size(); return int
向set添加元素方法:add(Object o); return boolean
删除set元素o的方法:remove(Object o); return boolean
判断元素o是否存在于Set中的方法:contains(Object o); return boolean
将Set装入迭代器中而进行操作的方法(因为Set没有索引,所以不方便直接对其进行操作,从而需要借助其迭代器方法):iterator(); return iterator
(1).迭代器iterator:
- 迭代器允许调用者利用定义良好的语义在迭代期间从迭代器所指向的 collection 移除元素。
- 常用方法:
- hasNext();判断迭代器中是否有下一个元素return boolean
- next(); 返回迭代的下一个元素
- remove();直接在其迭代的集合中删除迭代的最后一个元素 ,void;每次调用 next 只能调用一次此方法。如果进行迭代时用调用此方法之外的其他方式修改了该迭代器所指向的 collection,则迭代器的行为是不确定的。
- 注意:无法直接通过迭代器修改集合元素!!!
(2).集合的运算:
addAll(Collection c);求集合之间的并集
retainAll(Collection c);求集合之间的交集
removeAll(Collection c);求集合之间的差集
containsAll(Collection c);判断c是否是this的子集
(3).HashSet:
HashSet通过Hash算法排布集合内的元素,所谓的Hash算法就是把任意长度的输入(又叫做预映射),通过散列算法,变换成固定长度的输出,该输出就是散列值。这种转换是一种压缩映射。对于不同类型的信息,其散列值公式亦不完全相同。
当我们使用HashSet存储自定义类时,需要在自定义类中重写equals和hashCode方法,主要原因是集合内不允许有重复的数据元素,在集合校验元素的有效性时(数据元素不可重复),需要调用equals和hashCode验证。
HashSet在判断数据元素是否重复时:
1. 检查hashCode值是否与集合中已有相同。
2. 如果hashCode相同再调用equals方法进一步检查。(equals返回真表示重复)
(4.)TreeSet:
TreeSet是一个有序集合,其元素按照升序排列,默认是按照自然顺序排列,也就是说TreeSet中的对象元素需要实现Comparable接口。
TreeSet类中跟HashSet类一样也没有get()方法来获取指定位置的元素,所以也只能通过迭代器方法来获取。
TreeSet虽然是有序的,但是并没有具体的索引,当插入一个新的数据元素的时候,TreeSet中原有的数据元素可能需要重新排序,所以TreeSet插入和删除数据元素的效率较低。
当我们使用TreeSet存储自定义类时,需要在自定义类中重写compareTo方法,以提供比对形式,否在TreeSet不能对用户自定义的类型进行正确的树状排序。