grep应用
一、基本用法
[root@www ~]# grep [-acinv] [--color=auto] '搜寻字符串' filename 选项与参数: -a :将 binary 文件以 text 文件的方式搜寻数据 -c :计算找到 '搜寻字符串' 的次数 -i :忽略大小写的不同,所以大小写视为相同 -n :顺便输出行号 -v :反向选择,亦即显示出没有 '搜寻字符串' 内容的那一行!
-o :只显示匹配到的串 --color=auto :可以将找到的关键词部分加上颜色的显示
-E : 使用扩展正则表达式
-A number : 匹配到当前行并显示后number行
-B number :匹配到当前行并显示前number行
-C number : 匹配到当前行并显示前后number行
二、普通正则表达式之字符
1、元字符
. :匹配任意单个字符
[]:匹配指定范围内的任意单个字符
[^]:匹配指定范围外的任意单个字符
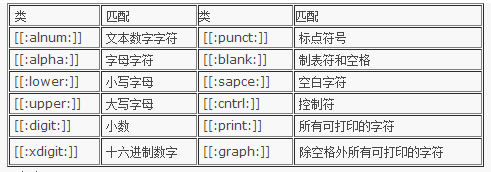
2、字符集合
三、普通正则表达式之匹配次数(贪婪模式:能匹配多少就匹配多少)
*:匹配其前面的字符任意次
.*:任意长度的任意字符
?:匹配其前面字符的1次或0次
{m,n}:匹配其前面的字符至少m次,至多n次
{1,} :最少一次,多了不限
{0,3}
四、普通正则表达式之位置锚定:
^:锚定行首,此字符后面的任意内容必须出现在行首
$: 锚定行尾,次字符前面的任意内容必须出现在行尾
^$:空白符
<:锚定行首,其后面的任意字符必须作为单词首部出现
>:锚定行尾,其后面的任意字符必须作为单词尾部出现
例子:<root 在行首的单词 如果是aroot是不行的
<root> 只有完全匹配root行才会显示
五、普通正则表达式之分组 ()
(ab)* :
把ab当成一个组实现0次1次或多次。
()的后项引用:
1:引用第一个左括号以及与之对应的右括号所包含的所有内容
2,3分别表示引用第二个左括号
例子:grep '(l..e).*1'
显示:He love his lover
六、扩展正则表达式(不需要写)
注:可以用grep -E 也可用egrep
字符匹配:
和普通相同:. 和[],[^]
次数匹配:
和普通相同:*,?,{m,n}(只是在扩展中不用)
和普通不同:+:匹配其前面字符至少1次,相当于{1,}
位置锚定
和普通相同:^,$,<,>
分组:
():真正的分组
引用:1,2,3
特殊字符:
| :表示或者的意思
C | cat:表示cat和C.是整体进行或。
匹配ip地址:
IPV4:
5类: A B C D E
A: 1-127
B: 128-191
C: 192-223
简单版:
<[1-9] | [1-9] [1-9] | 1[0-9] {2} | 2[01] [0-9] | 22[0-3]>(.<[1-9] | [1-9] [1-9] | 1[0-9] {2} | 2[01] [0-9] | 25[0-4]>){2}.<[1-9] | [1-9] [1-9] | 1[0-9] {2} | 2[01] [0-9] | 25[0-4]>
可匹配到223.254.254.254
复杂版:
((?:(?:25[0-5]|2[0-4]d|((1d{2})|([1-9]?d))).){3}(?:25[0-5]|2[0-4]d|((1d{2})|([1-9]?d))))
可匹配到255.255.255.254
注:正则表达式是贪婪模式,如果需要切换为非贪婪模式,可以使用?来切换。