webmagic 是一个很好并且很简单的爬虫框架,其教程网址:http://my.oschina.net/flashsword/blog/180623
webmagic参考了scrapy的模块划分,分为Spider(整个爬虫的调度框架)、Downloader(页面下载)、PageProcessor(链接提取和页面分析)、Scheduler(URL管理)、Pipeline(离线分析和持久化)几部分。只不过scrapy通过middleware实现扩展,而webmagic则通过定义这几个接口,并将其不同的实现注入主框架类Spider来实现扩展。
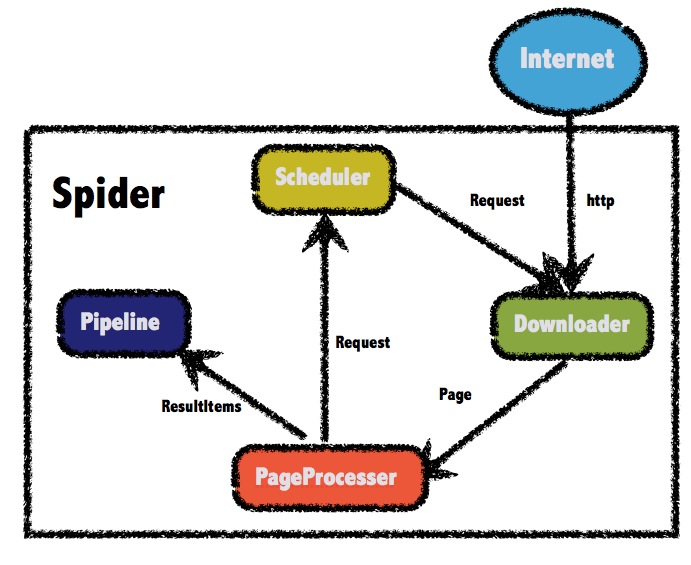
关于Scheduler(URL管理) 最基本的功能是实现对已经爬取的URL进行标示。
目前scheduler有三种实现方式:
1)内存队列
2)文件队列
3)redis队列
文件队列保存URL,能实现中断后,继续爬取时,实现增量爬取。
如果我只有一个主页的URL,比如:http://www.cndzys.com/yundong/。如果直接引用webmagic的FileCacheQueueScheduler的话,你会发现第二次启动的时候,什么也爬不到。可以说第二次启动基本不爬取数据了。因为FileCacheQueueScheduler 把http://www.cndzys.com/yundong/ 记录了,然后不再进行新的爬取。虽然是第二次增量爬取,但还是需要保留某些URL重新爬取,以保证爬取结果是我们想要的。我们可以重写FileCacheQueueScheduler里的比较方法。
1 package com.fortunedr.crawler.expertadvice; 2 3 4 import java.io.BufferedReader; 5 import java.io.Closeable; 6 import java.io.File; 7 import java.io.FileNotFoundException; 8 import java.io.FileReader; 9 import java.io.FileWriter; 10 import java.io.IOException; 11 import java.io.PrintWriter; 12 import java.util.LinkedHashSet; 13 import java.util.Set; 14 import java.util.concurrent.BlockingQueue; 15 import java.util.concurrent.Executors; 16 import java.util.concurrent.LinkedBlockingQueue; 17 import java.util.concurrent.ScheduledExecutorService; 18 import java.util.concurrent.TimeUnit; 19 import java.util.concurrent.atomic.AtomicBoolean; 20 import java.util.concurrent.atomic.AtomicInteger; 21 22 import org.apache.commons.io.IOUtils; 23 import org.apache.commons.lang3.math.NumberUtils; 24 25 import us.codecraft.webmagic.Request; 26 import us.codecraft.webmagic.Task; 27 import us.codecraft.webmagic.scheduler.DuplicateRemovedScheduler; 28 import us.codecraft.webmagic.scheduler.MonitorableScheduler; 29 import us.codecraft.webmagic.scheduler.component.DuplicateRemover; 30 31 32 /** 33 * Store urls and cursor in files so that a Spider can resume the status when shutdown.<br> 34 *增加去重的校验,对需要重复爬取的网址进行正则过滤 35 * @author code4crafter@gmail.com <br> 36 * @since 0.2.0 37 */ 38 public class SpikeFileCacheQueueScheduler extends DuplicateRemovedScheduler implements MonitorableScheduler,Closeable { 39 40 private String filePath = System.getProperty("java.io.tmpdir"); 41 42 private String fileUrlAllName = ".urls.txt"; 43 44 private Task task; 45 46 private String fileCursor = ".cursor.txt"; 47 48 private PrintWriter fileUrlWriter; 49 50 private PrintWriter fileCursorWriter; 51 52 private AtomicInteger cursor = new AtomicInteger(); 53 54 private AtomicBoolean inited = new AtomicBoolean(false); 55 56 private BlockingQueue<Request> queue; 57 58 private Set<String> urls; 59 60 private ScheduledExecutorService flushThreadPool; 61 62 private String regx; 63 64 65 public SpikeFileCacheQueueScheduler(String filePath) { 66 if (!filePath.endsWith("/") && !filePath.endsWith("\")) { 67 filePath += "/"; 68 } 69 this.filePath = filePath; 70 initDuplicateRemover(); 71 } 72 73 private void flush() { 74 fileUrlWriter.flush(); 75 fileCursorWriter.flush(); 76 } 77 78 private void init(Task task) { 79 this.task = task; 80 File file = new File(filePath); 81 if (!file.exists()) { 82 file.mkdirs(); 83 } 84 readFile(); 85 initWriter(); 86 initFlushThread(); 87 inited.set(true); 88 logger.info("init cache scheduler success"); 89 } 90 91 private void initDuplicateRemover() { 92 setDuplicateRemover( 93 new DuplicateRemover() { 94 @Override 95 public boolean isDuplicate(Request request, Task task) { 96 if (!inited.get()) { 97 init(task); 98 } 99 boolean temp=false; 100 String url=request.getUrl(); 101 temp=!urls.add(url);//原来验证URL是否存在 102 //正则匹配 103 if(url.matches(regx)){//二次校验,如果符合我们需要重新爬取的,返回false。可以重新爬取 104 temp=false; 105 } 106 return temp; 107 } 108 109 @Override 110 public void resetDuplicateCheck(Task task) { 111 urls.clear(); 112 } 113 114 @Override 115 public int getTotalRequestsCount(Task task) { 116 return urls.size(); 117 } 118 }); 119 } 120 121 private void initFlushThread() { 122 flushThreadPool = Executors.newScheduledThreadPool(1); 123 flushThreadPool.scheduleAtFixedRate(new Runnable() { 124 @Override 125 public void run() { 126 flush(); 127 } 128 }, 10, 10, TimeUnit.SECONDS); 129 } 130 131 private void initWriter() { 132 try { 133 fileUrlWriter = new PrintWriter(new FileWriter(getFileName(fileUrlAllName), true)); 134 fileCursorWriter = new PrintWriter(new FileWriter(getFileName(fileCursor), false)); 135 } catch (IOException e) { 136 throw new RuntimeException("init cache scheduler error", e); 137 } 138 } 139 140 private void readFile() { 141 try { 142 queue = new LinkedBlockingQueue<Request>(); 143 urls = new LinkedHashSet<String>(); 144 readCursorFile(); 145 readUrlFile(); 146 // initDuplicateRemover(); 147 } catch (FileNotFoundException e) { 148 //init 149 logger.info("init cache file " + getFileName(fileUrlAllName)); 150 } catch (IOException e) { 151 logger.error("init file error", e); 152 } 153 } 154 155 private void readUrlFile() throws IOException { 156 String line; 157 BufferedReader fileUrlReader = null; 158 try { 159 fileUrlReader = new BufferedReader(new FileReader(getFileName(fileUrlAllName))); 160 int lineReaded = 0; 161 while ((line = fileUrlReader.readLine()) != null) { 162 urls.add(line.trim()); 163 lineReaded++; 164 if (lineReaded > cursor.get()) { 165 queue.add(new Request(line)); 166 } 167 } 168 } finally { 169 if (fileUrlReader != null) { 170 IOUtils.closeQuietly(fileUrlReader); 171 } 172 } 173 } 174 175 private void readCursorFile() throws IOException { 176 BufferedReader fileCursorReader = null; 177 try { 178 fileCursorReader = new BufferedReader(new FileReader(getFileName(fileCursor))); 179 String line; 180 //read the last number 181 while ((line = fileCursorReader.readLine()) != null) { 182 cursor = new AtomicInteger(NumberUtils.toInt(line)); 183 } 184 } finally { 185 if (fileCursorReader != null) { 186 IOUtils.closeQuietly(fileCursorReader); 187 } 188 } 189 } 190 191 public void close() throws IOException { 192 flushThreadPool.shutdown(); 193 fileUrlWriter.close(); 194 fileCursorWriter.close(); 195 } 196 197 private String getFileName(String filename) { 198 return filePath + task.getUUID() + filename; 199 } 200 201 @Override 202 protected void pushWhenNoDuplicate(Request request, Task task) { 203 queue.add(request); 204 fileUrlWriter.println(request.getUrl()); 205 } 206 207 @Override 208 public synchronized Request poll(Task task) { 209 if (!inited.get()) { 210 init(task); 211 } 212 fileCursorWriter.println(cursor.incrementAndGet()); 213 return queue.poll(); 214 } 215 216 @Override 217 public int getLeftRequestsCount(Task task) { 218 return queue.size(); 219 } 220 221 @Override 222 public int getTotalRequestsCount(Task task) { 223 return getDuplicateRemover().getTotalRequestsCount(task); 224 } 225 226 public String getRegx() { 227 return regx; 228 } 229 /** 230 * 设置保留需要重复爬取url的正则表达式 231 * @param regx 232 */ 233 public void setRegx(String regx) { 234 this.regx = regx; 235 } 236 237 238 }
那么在爬虫时就引用自己特定的FileCacheQueueScheduler就可以
1 spider.addRequest(requests); 2 SpikeFileCacheQueueScheduler file=new SpikeFileCacheQueueScheduler(filePath); 3 file.setRegx(regx);//http://www.cndzys.com/yundong/(index)?[0-9]*(.html)? 4 spider.setScheduler(file );
这样就实现了增量爬取。
优化的想法:一般某个网站的内容列表都是首页是最新内容。上面的方式是可以实现增量爬取,但是还是需要爬取很多“无用的”列表页面。
能不能实现,当爬取到上次"最新"URL之后就不再爬取。就是不用爬取其他多余的leib