算法步骤:
1.计算物品相似度
2.根据用户购买记录,推荐相似物品
物品相似度定义:
A.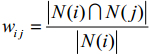
购买i的人里面,有多少比例购买了j
缺点(推荐系统需要能挖掘长尾信息,此处若j很热门,则w趋向于很大,则买了i的人都会被推荐j,热门商品更加热门)
B.
在A的基础上,加入了对热门物品j的惩罚
C.
活跃用户的贡献度应该要低(例子:一个在当当上买书的人,是一个自己开书店的人)
相似度归一化:可提高准确率、召回率、覆盖率、新颖度
--分析:
假设用户喜欢看两类电影(科幻片,爱情片),而科幻片的相似度普遍比爱情片要低,
此时用户看了3部爱情片和3部科幻片,经过计算给用户推荐的大部分会是爱情片(应该是爱情和科幻差不多),
此时通过归一化,可以提高推荐的覆盖率和多样性
推荐:
用户u对物品j的兴趣程度,N(u)为用户u购买历史,S(j,K)为和物品j最相似的K个物品
--计算:
1.获取用户u购买历史,nu
2.遍历nu,获取和购买过物品i 最相似的K个物品,计算其加上物品i贡献的相似度
实现:
import pandas as pd from sklearn import cross_validation import math class ItemCF(): def __init__(self,data,k): self.train=data self.k=k self.ui=self.user_item(self.train) self.iu = self.item_user(self.train) self.itemSimilarityMatrix() ''' 获取每个商品对应的用户(购买过该商品的用户)列表,如 {商品A:[用户1,用户2,用户3], 商品B:[用户3,用户4,用户5]...} ''' def item_user(self,data): iu = dict() groups = data.groupby([1]) for item,group in groups: iu[item]=set(group.ix[:,0]) return iu ''' 获取每个用户对应的商品(用户购买过的商品)列表,如 {用户1:[商品A:评分,商品B:评分,商品C:评分], 用户2:[商品D:评分,商品E:评分,商品F:评分]...} ''' def user_item(self,data): ui = dict() groups = data.groupby([0]) for item,group in groups: ui[item]=dict() for i in range(group.shape[0]): ui[item][group.iget_value(i,1)]=group.iget_value(i,2) return ui def itemSimilarityMatrix(self): matrix = dict() for u,ps in self.ui.items(): denominator = 1.0/math.log(1+len(ps)); for p1 in ps.keys(): for p2 in ps.keys(): if p1==p2: continue if p1 not in matrix: matrix[p1]=dict() if p2 not in matrix[p1]: matrix[p1][p2]=0 matrix[p1][p2] += denominator/math.sqrt(len(self.iu[p1])*len(self.iu[p2])) for p in matrix.keys(): #对每个商品i,将其他商品j按其与i的相似度从大大小排序 matrix[p] = sorted(matrix[p].items(),lambda x,y:cmp(x[1],y[1]),reverse=True); #归一化 matrix[p] = [(x[0],x[1]/matrix[p][0][1]) for x in matrix[p]] self.M=matrix ''' 对用户user进行推荐 ''' def getRecommend(self,user): rank = dict() uItem=self.ui[user]#获取用户购买历史 for uproduct,urank in uItem.items(): uproduct_simi = self.M[uproduct][0:self.k] for p_simi in uproduct_simi: p = p_simi[0] simi = p_simi[1] if p in uItem: continue if p not in rank: rank[p]=0 rank[p]+=urank*simi return rank def estimate(self,test): ui_test=self.user_item(test) unions = 0 sumRec = 0 sumTes = 0 itemrec = set() sumPopularity = 0 for user in self.ui.keys(): rank=self.getRecommend(user); itemtest = set() if user in ui_test: itemtest = set(ui_test[user].keys()) sumRec += len(rank) sumTes += len(itemtest) for recItem in rank: sumPopularity += math.log(1+len(self.iu[recItem])) itemrec.add(recItem) if recItem in itemtest: unions += 1; return unions*1.0/sumRec,unions*1.0/sumTes,len(itemrec)*1.0/len(self.iu.keys()),sumPopularity*1.0/sumRec