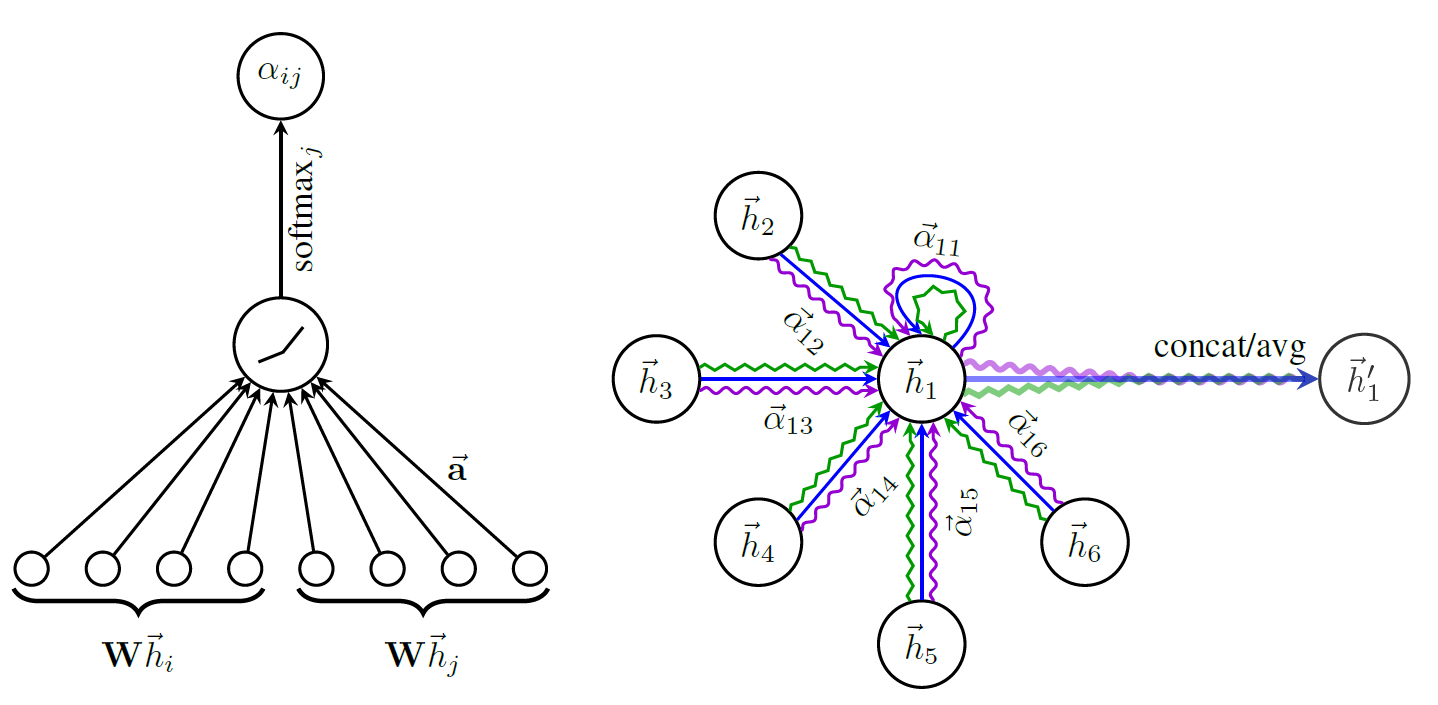
- 1. GRAPH ATTENTION NETWORKS | 2018.2.4
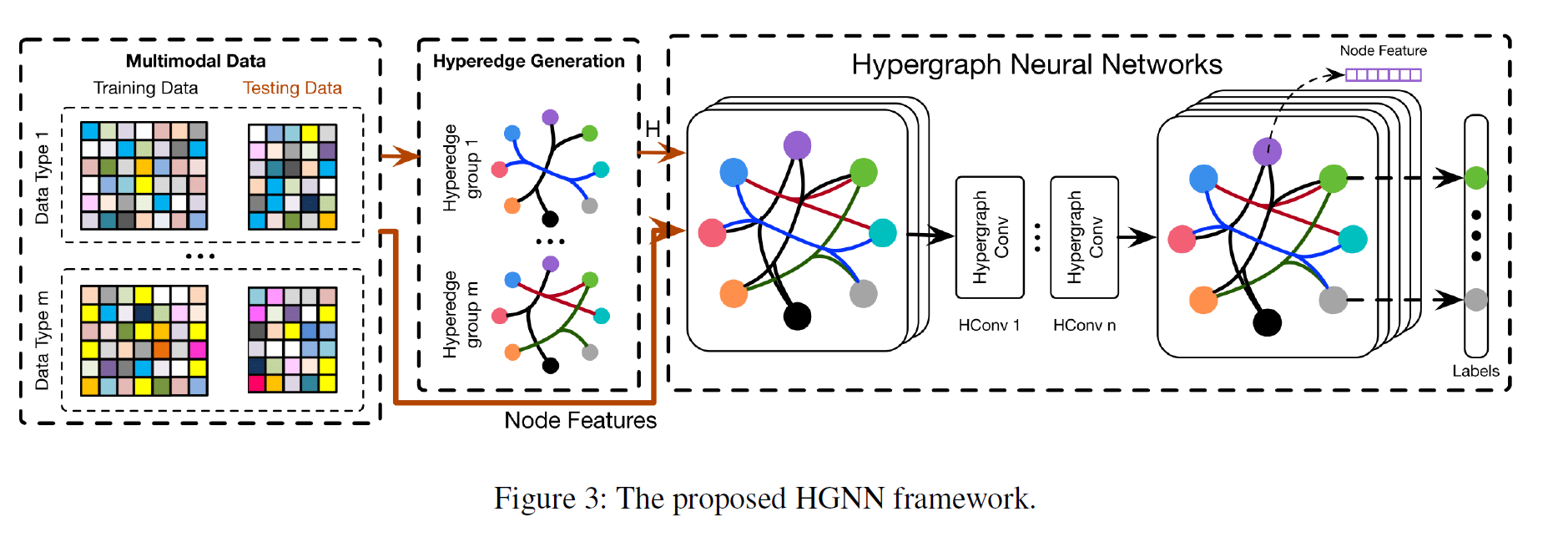
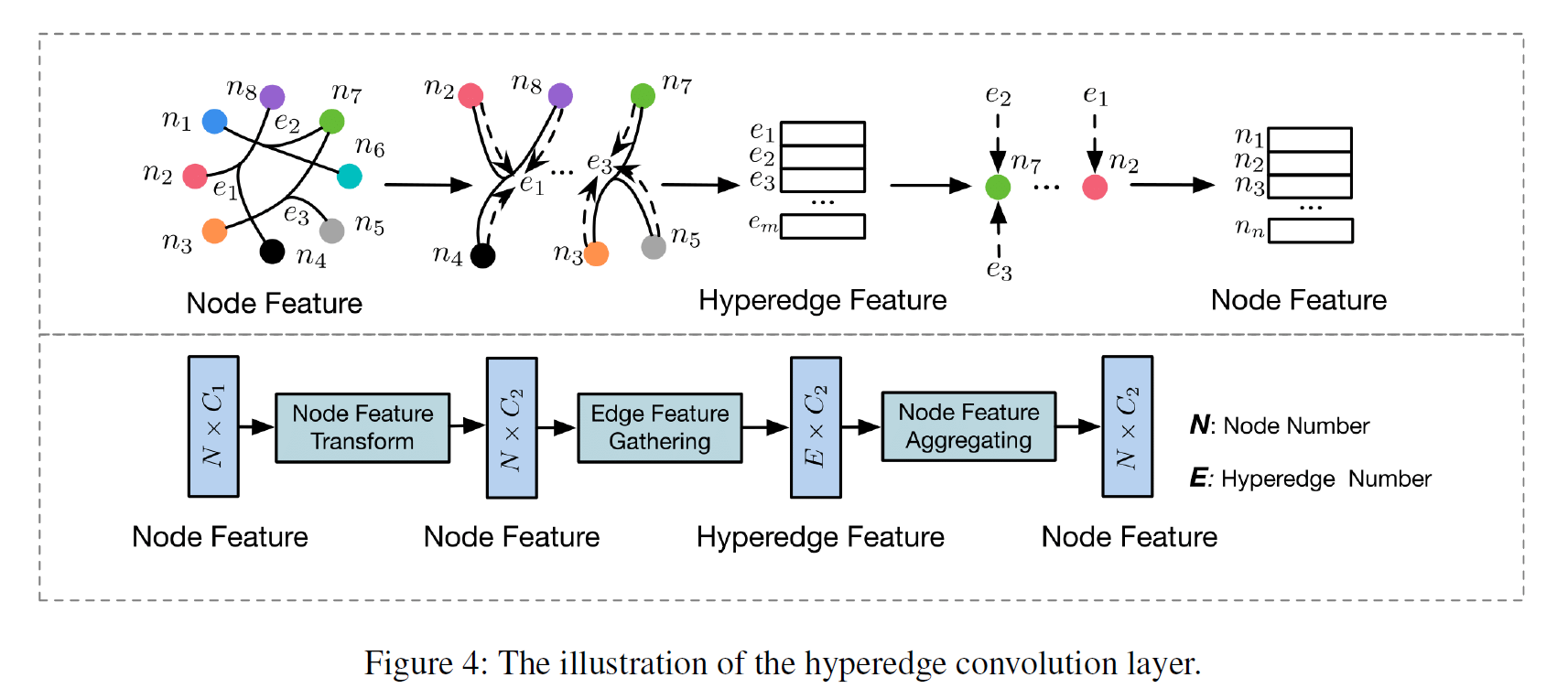
- 2. HGNN | 2019.2.23
- 3. Dynamic Hypergraph Neural Networks | 2019.10.16
- 4.Hyper-SAGNN: a self-attention based graph neural network for hypergraphs | 2019.11.6
- 5. Hypergraph Convolution and Hypergraph Attention | 2020.10.10
- 6. Be More with Less: Hypergraph Attention Networks for Inductive Text Classification | 2020.11.1
- 7. Heterogeneous Graph Attention Network | 2019.5.13
- 8. 补充
1. GRAPH ATTENTION NETWORKS | 2018.2.4
图上节点间注意力机制,计算量是 (O(n^2))的。博文:https://zhuanlan.zhihu.com/p/81350196
2. HGNN | 2019.2.23
HGNN 是一种基于谱域的超图学习方法。该方法首先针对一个多模式数据,采用 (KNN) 转化为(K-)均匀超图(一个超边总是包含(K)个节点),然后将得到的超图送入超图神经网络(HGNN)中学习。超图神经网络包括多个超边卷积层(hyperedge convolution layer)。每一个超边卷积层都对节点进行一层 (embedding)。
超边卷积层的工作原理:节点特征聚合,得到超边特征。一个节点再学习其所在的所有超边的特征。
3. Dynamic Hypergraph Neural Networks | 2019.10.16
超图/图的边是固有的,所以这个很大的限制了点之间的隐含关系。文章提出了动态超图神经网络DHGNN,用于解决这种问题。其分成两个阶段:动态超图重建(DHG)以及动态图卷积(HGC)。DHG用于每一层动态更新超图结构(这里的每一层很关键,因为Dynamic hypergraph structure learning (DHSL) [Zhanget al., 2018] 已经是初始的时候进行动态的),HGC使用顶点卷积和边卷积,用于汇集点和边的信息。
贡献:
-
提出动态图构建方法,先用k-NN方法产生基础的超边,再用K-means对节点进行聚类,生成扩充的边。这么做就可以提取到局部和整体的关系。
-
我们进行了基于网络的分类和社交媒体情绪预测实验。在基于网络的任务中,我们的方法优于现有的方法,对不同的数据分布具有较高的鲁棒性。在社交媒体情绪预测方面,我们方法优于最先进的方法(SOTA)
每一层的结构(实际框架包含多层):
动态超图构建 ( o) 超图卷积
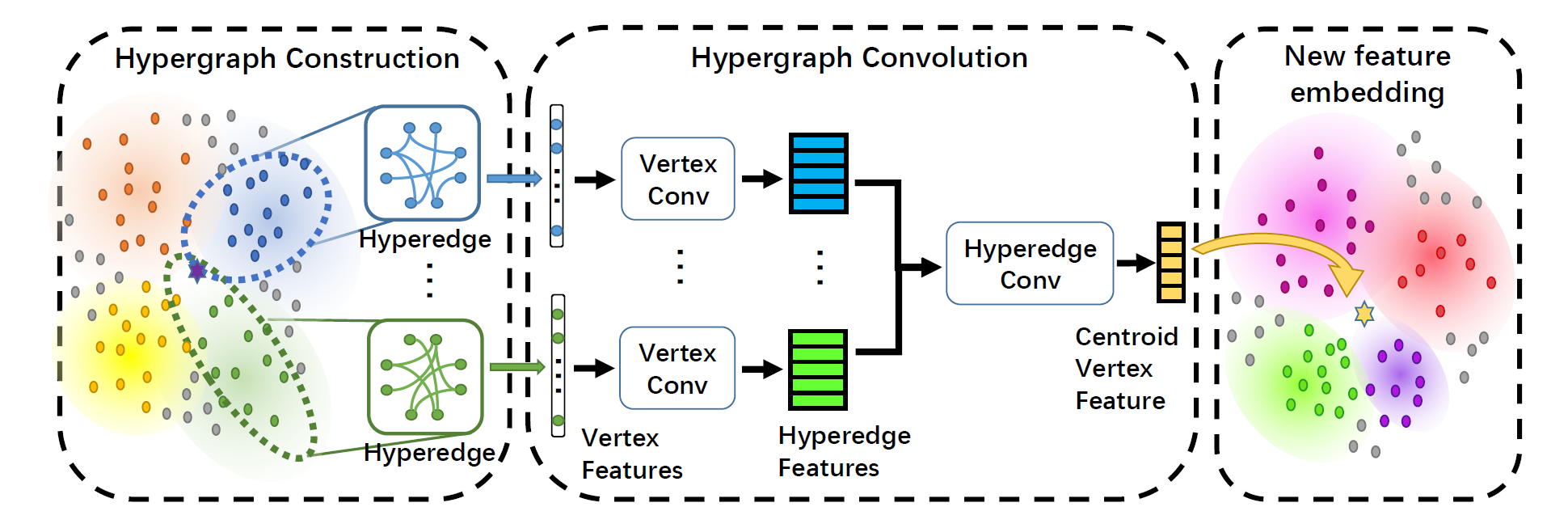
- 超图卷积(包含节点级别和超边级别)
节点卷积将边上所连接的节点的信息都汇集到边上,(简单做法:平均池化,最大池化),SOTA做法是直接用一个固定的,从图结构里提前计算好的转移矩阵进行处理,但是这种方法无法很好地对顶点特征间的描述信息进行建模,所以这里由节点特征来生成转移矩阵,即
(T = MLP(X_u))。转移之后我们再使用单通道的卷积层将特征变成一维,即(X_e = conv(T * MLP(X_u)))。整个流程为
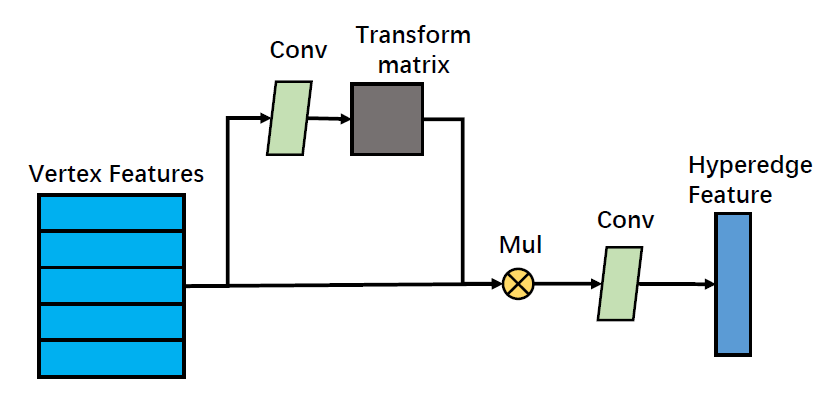
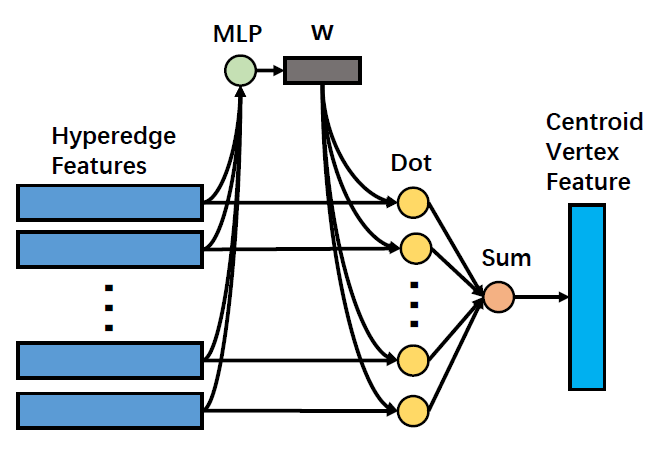
接下来进行超边卷积,利用多层感知机学习线性变换 (W),以引入超边注意力机制,将超边特征加权求和,最后得到中心节点的更新特征表示(X_u)
4.Hyper-SAGNN: a self-attention based graph neural network for hypergraphs | 2019.11.6
本文提出了一种超图判定算法
超图可以用来表示高阶的相互作用。为了分析高阶相互作用数据,通常假设超边是可分解的,可以直接将每个超边展开为对边。然而,早期的工作DHNE(Deep Hyper Network Embedding)指出了异质不可分解超边的存在性,即其中超边的不完全子集中的关系不存在性。最近基于深度学习的模型已经从图泛化到超图。基于超边的嵌入方法(HEBE)旨在通过将对象表示为一个超边来学习特定异构事件中每个对象的嵌入情况。然而,HEBE在稀疏超图上表现不佳。深度超图嵌入(DHNE)模型使用MLP直接对元组关系进行建模。与同为图或超图设计的其他方法如Deepwalk、node2vec和HEBE相比,该方法能够在多个任务上获得更好的性能。不幸的是,MLP的结构需要固定大小的输入,使得DHNE只能处理k均匀的超图,即超边只包含k个节点。
本文中提出的的Hyper-SAGNN通过一个基于自注意力机制的图神经网络来解决所有这些挑战,该网络可以学习节点的嵌入情况并预测非k均匀异构超图的超边。Hyper-SAGNN显著地优于现有的方法,并且可以应用于各种超图问题上。
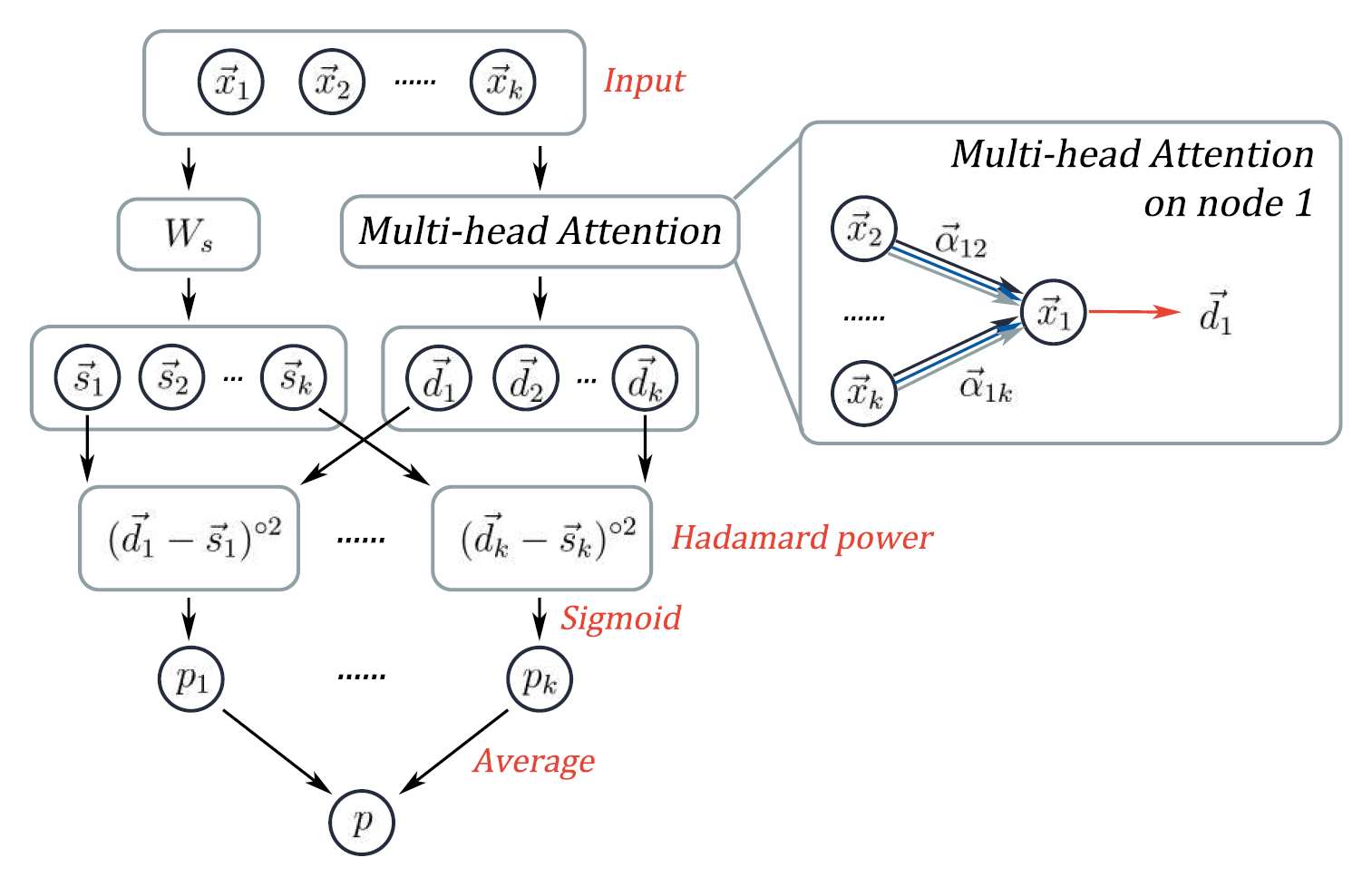
原始特征 (X_i) 两种 embedding 方式:静态 embedding(不依靠其他节点) 和动态 embedding (依靠其他节点)
两种 embedding 计算距离,将距离做Hadamard幂后,经过一层 sigmoid 作为激活函数的全连接层,得到 k 个节点的概率打分 (p_1 ... p_k),然后对它们求平均得到整个网络最终的打分 (p)。
网络的目标是建立静态/动态嵌入对的平均“距离”与节点组形成超边的概率的相关性。由于动态嵌入是元组内相邻节点的特征(具有潜在的非线性变换)的加权和,因此这个“距离”反映了每个节点的静态嵌入能够多大程度上可以用元组内相邻节点的特征来近似。这种设计策略与自然语言处理中的CBOW模型有一些相似之处。
https://zhuanlan.zhihu.com/p/159472758
https://cloud.tencent.com/developer/article/1785250
5. Hypergraph Convolution and Hypergraph Attention | 2020.10.10
本文提出了一种针对超图关联矩阵 (H) 使用注意力机制优化的方法,称为超图注意力(Hypergraph Attention),将 (01) 矩阵 (H) 优化为注意力值表示。
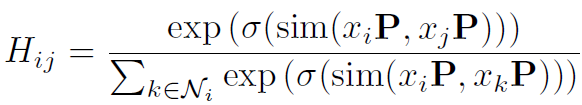
其中sim是一种相似性计算函数。它是一个可以学习的线性变换函数。
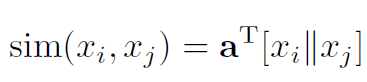
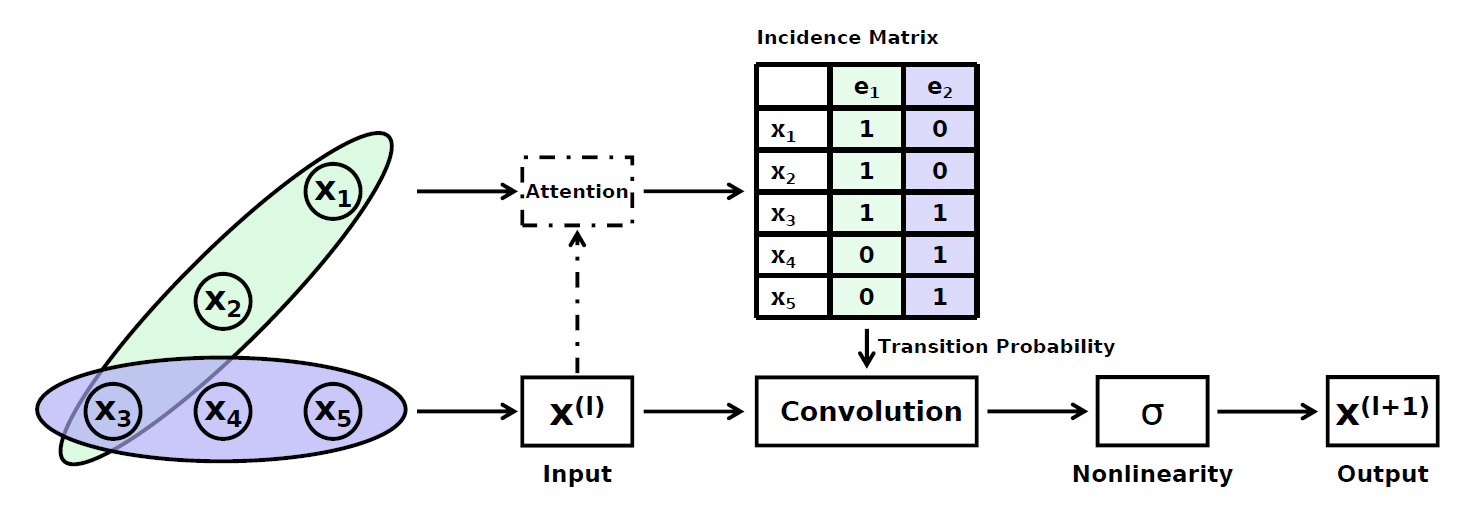
本文还提出了超图卷积(Hypergraph Convolution),这是一种纯空域方法,用于得到超图节点的深层次 embedding。
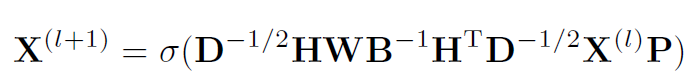
这是一个归一化后的矩阵形式表达式。其意义为:节点 (i) 的 ((l+1)) 层特征的计算方法为,对于每一个 (i) 所在的超边 (e), 对于每一个在超边 (e) 中的顶点 (j) , 超边权重 (W_{ee}) ( imes) ((l)) 层节点 (j) 的特征表示 ( imes) (P) (层间线性变换矩阵),最后再套一个激活函数。
完整模型:其中 Attention 机制优化 (H) 是可选择的
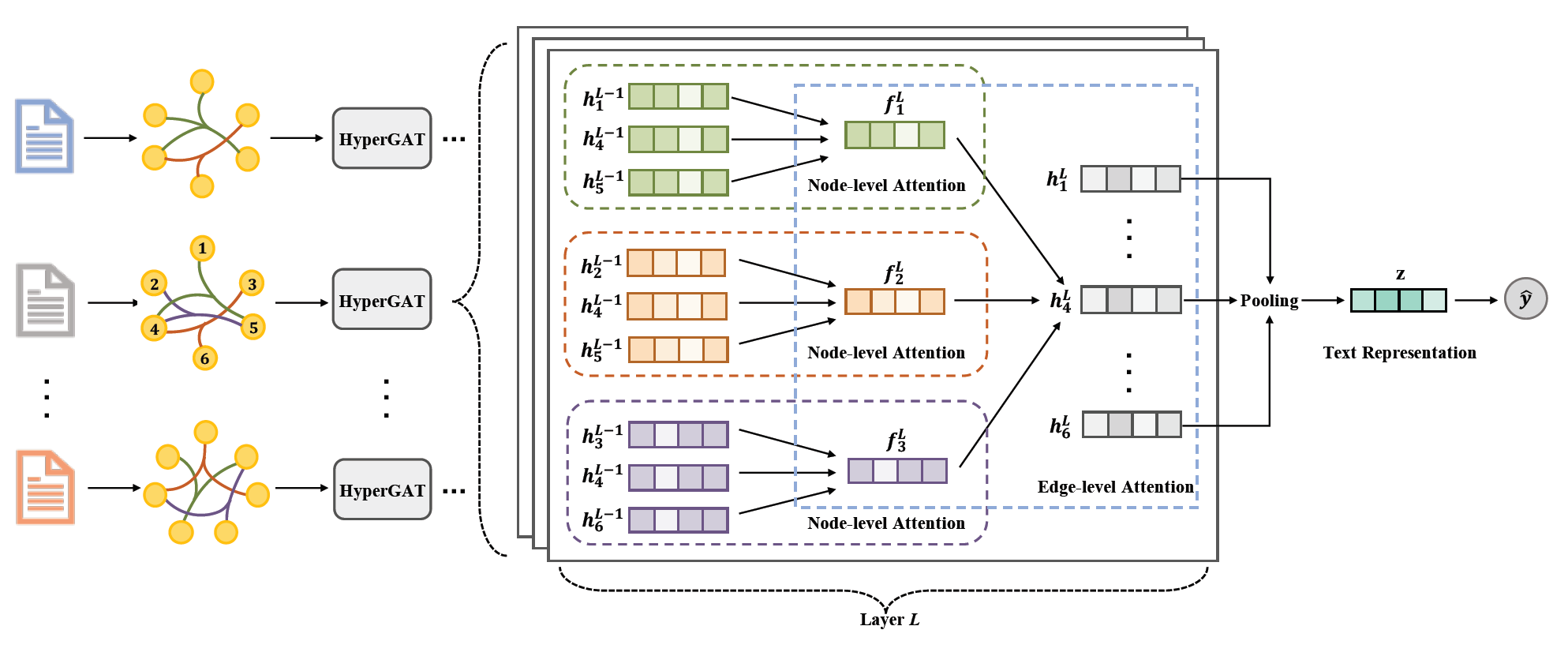
6. Be More with Less: Hypergraph Attention Networks for Inductive Text Classification | 2020.11.1
模型结构分为节点级注意力和超边级注意力,思路非常直接。


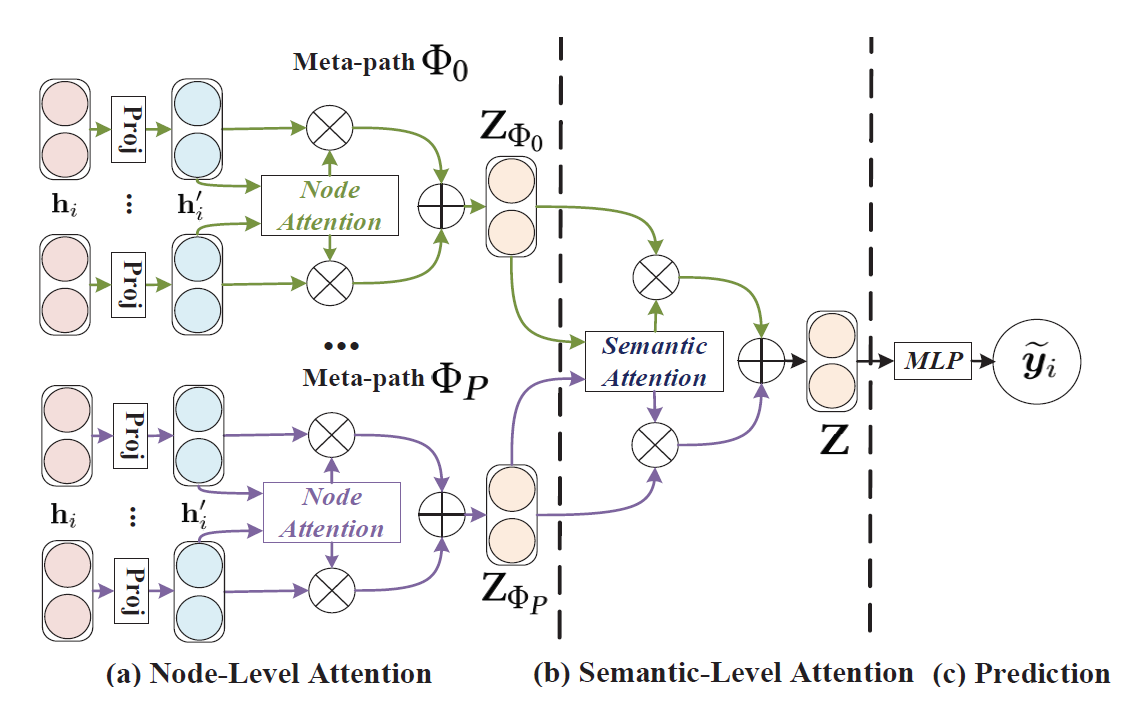
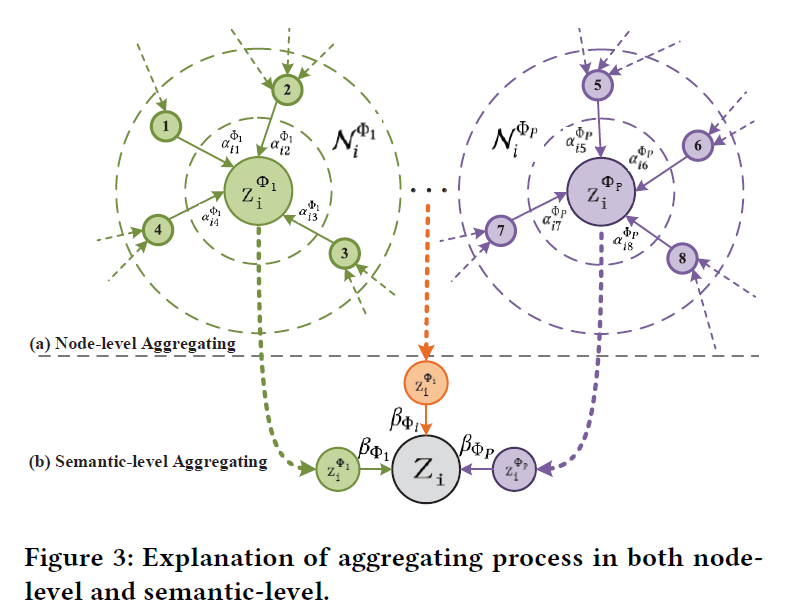
7. Heterogeneous Graph Attention Network | 2019.5.13
分为节点级注意力和语义级注意力
8. 补充
