最近爆发了一个问题 , 以前一直在正常运行的应用突然无法访问 .
不用问,这个肯定是服务器的问题,但是这个要怎么看呢?
1.登录服务器,如果服务器压力过大,已经无法登录服务器了,那么只能请求DBA强制重启了.
1.1. 假设能登陆服务器,马上查看服务器CPU以及内存或者回收等信息,可以那么使用以下方法收集日志和查看CPU,手速一定要快,比较用户都在催,电话,微信,qq都在响..收集完了就重启服务器,现正常了再查原因.
附图:为了大家能够熟练敲打,照着多打吧.

2.登录之后查看回收效率以及速度:
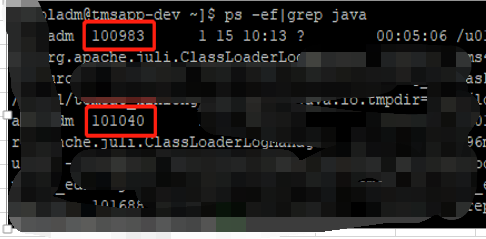
1.通过 ps -ef|grep java 得到pid:如图:
2.通过 ps -p 101040 -o etime;jstat -gcutil 101040 1000 30
上面的命令意思:
ps -p 101040 -o etime 查看的是应用运行时长
jstat -gcutil 为查看jvm gc回收情况的命令
101040 为上图的PID
1000为时间间隔,单位毫秒
30为打印的条数,不设定则一直打印
至于打印什么东西??请看下面:
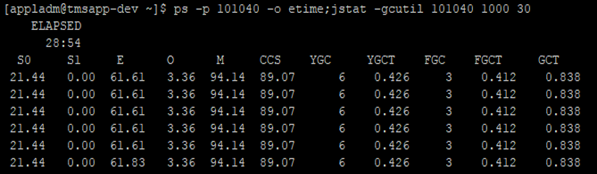
结果中每个项目的含义可以参考官方对jstat的文档,简单翻译如下:(参考别人的翻译)
- S0C: Young Generation第一个survivor space的内存大小 (kB).
- S1C: Young Generation第二个survivor space的内存大小 (kB).
- S0U: Young Generation第一个Survivor space当前已使用的内存大小 (kB).
- S1U: Young Generation第二个Survivor space当前已经使用的内存大小 (kB).
- EC: Young Generation中eden space的内存大小 (kB).
- EU: Young Generation中Eden space当前已使用的内存大小 (kB).
- OC: Old Generation的内存大小 (kB).
- OU: Old Generation当前已使用的内存大小 (kB).
- PC: Permanent Generation的内存大小 (kB)
- PU: Permanent Generation当前已使用的内存大小 (kB).
- YGC: 从启动到采样时Young Generation GC的次数
- YGCT: 从启动到采样时Young Generation GC所用的时间 (s).
- FGC: 从启动到采样时Old Generation GC的次数.
- FGCT: 从启动到采样时Old Generation GC所用的时间 (s).
- GCT: 从启动到采样时GC所用的总时间 (s).
3.上面都是查看JVM的内存情况,具体表现为jvm内存泄露,解决方案现在有2个:
1.具体问题具体分析,找到内存泄露的瓶颈,上面所搜集的日志可以帮助你找到问题的根源;
2.短期内需要保证项目运行,那么请将JVM的内存加大,1G的加到2G,2G的加到4G等...
调整方式(Tomcat为例,其他容器自行参考)
1.打开文件:自己的tomcat目录/bin/catalina.sh
2.找到如下参数,并将其修改为如下:
JAVA_OPTS="-server -Xms4096m -Xmx4096m"
JavaOpts里面的server参数足够用了,其余多余的参数其实没什么用(项目自行配置),将上面的内存大小调整即可,如上面为4096M=4G.
调整内存只是权宜之计,根本问题还是要找到瓶颈,对症下药!!!
祝大家永无bug.