Redis协议
Redis 的通信协议是基于文本的,且以行为划分,每行以 结束。每一行都有一个消息头,消息头共分为5种分别如下:
+表示一个正确的状态信息,具体信息是当前行 + 后面的字符;
- 表示一个错误信息,具体信息是当前行-后面的字符;
* 表示消息体总共有多少行,不包括当前行,* 后面是具体的行数;
$ 表示下一行数据长度,不包括换行符长度 , $ 后面则是对应的长度的数据;
: 表示返回一个数值,:后面是相应的数字节符;


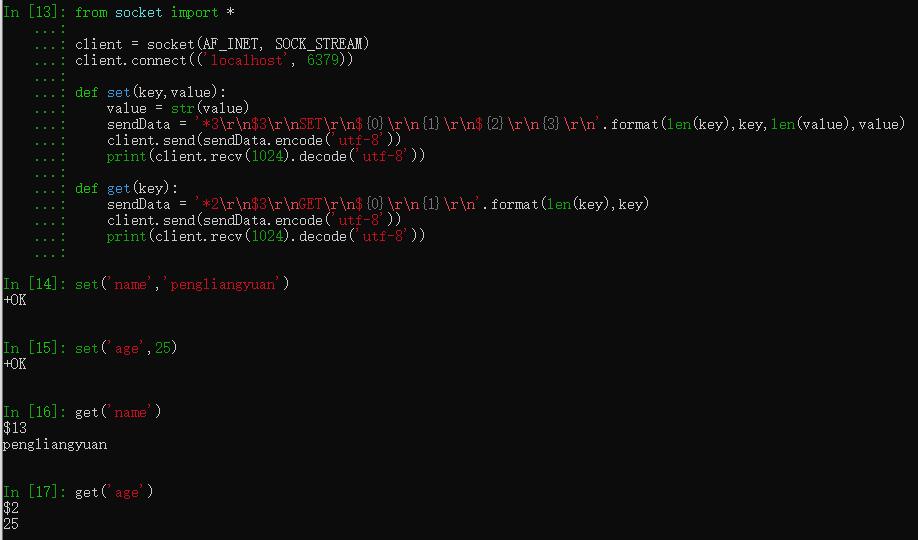
from socket import * client = socket(AF_INET, SOCK_STREAM) client.connect(('localhost', 6379)) def set(key,value): value = str(value) sendData = '*3 $3 SET ${0} {1} ${2} {3} '.format(len(key),key,len(value),value) client.send(sendData.encode('utf-8')) print(client.recv(1024).decode('utf-8')) def get(key): sendData = '*2 $3 GET ${0} {1} '.format(len(key),key) client.send(sendData.encode('utf-8')) print(client.recv(1024).decode('utf-8'))
Redis持久化
什么是持久化?为什么要持久化?
redis之所以高效是因为数据存储在内存中,内存中数据会断电丢失,所以需要持久化,持久化是将内存中的数据写到磁盘中
redis持久化的方式:
- RDB 持久化可以在指定的时间间隔内生成数据集的时间点快照
- AOF 持久化记录服务器执行的所有写操作命令,并在服务器启动时,通过重新执行这些命令来还原数据集
RDB(redis database)
redis将数据库快照保存在名为dump.rdb的二进制文件中,可以对redis进行设置,让他在“N秒内数据集至少有M个改动”时保存数据集。
例:60s内至少有1000个键被改动时,自动保存一次数据集
save 60 1000
例:60s内至少有1000个键被改动,或300s内至少有10个键被改动,或600s内至少有1个键被改动(如果离上次保存数据集的时间越来越长,触发条件就越来越容易,这很符合实际需求)
save 900 1 save 300 10 save 60 10000
RDB优点:
rdb文件紧凑,体积小,无IO阻塞(fork子进程来持久化数据),恢复速度比AOF快
RDP缺点:
实时性比较差(全量备份,备份频率比较低,数据丢失较多),当数据比较多时fork比较耗时
AOF(append-only file)
快照功能实时性不好,如果故障停机,服务器会丢失最近写入,且未保存到快照中的数据。
重1.1版本开始,redis增加了一种完全实时性的持久化方式:AOF持久化
通过配置文件打开AOF功能:
appendonly yes
AOF配置选项
- 每次有新命令追加到AOF文件就执行一次
fsync:非常慢,也非常安全 - 每秒
fsync一次:足够快(和使用RDB持久化差不多),并且故障只丢失1s中的数据 - 从不
fsync:将数据交给操作系统来处理:更快,也更不安全
AOF优点:
实时性比RDB好(增量备份,备份频率比较高,数据丢失较少)
AOF缺点:
AOF文件大,恢复速度慢,对性能影响大
Redis事务
redis事务有两个重要保证:
- 事务是一个单独的隔离操作:事务中所有命令都会序列化、按顺序执行。事务在执行过程中,不会被其他客户端发过来的命令所打断。
- 事务是一个原子操作:事务中的命令要么全部被执行,要么全部都不执行。
以上是来自于http://redisdoc.com/topic/transaction.html的解释,我之所以画杠是因为和下面的说话冲突
redis事务不支持回滚:
- Redis 命令只会因为错误的语法而失败(并且这些问题不能在入队时发现),或是命令用在了错误类型的键上面:这也就是说,从实用性的角度来说,失败的命令是由编程错误造成的,而这些错误应该在开发的过程中被发现,而不应该出现在生产环境中。
- 因为不需要对回滚进行支持,所以 Redis 的内部可以保持简单且快速。
redis事务的用法
一个事务
> MULTI OK > INCR foo QUEUED > INCR bar QUEUED > EXEC 1) (integer) 1 2) (integer) 1
事务取消
redis> SET foo 1 OK redis> MULTI OK redis> INCR foo QUEUED redis> DISCARD OK redis> GET foo "1"
check-and-set(乐观锁)
WATCH mykey val = GET mykey val = val + 1 MULTI SET mykey $val EXEC
竞争问题
当多个client对一个资源同时写的时候会发生竞争
例:
count被cli1,cli2共同写入,先初始化count的值
127.0.0.1:6379> set count 0 OK
cli1.py和cli2.py都是如下程序,两个程序同时执行,若没有竞争发生,count的值应该是2000
import redis
import time
rc = redis.StrictRedis()
for i in range(1000):
count = int(rc.get("count"))
count += 1
rc.set('count', count)
time.sleep(0.01)
cli1.py和cli2.py执行结束后,查看count的值
127.0.0.1:6379> get count "1285"
对于计数问题,解决竞争方式很简单,将程序改成这样就行了
import redis
import time
rc = redis.StrictRedis()
for i in range(1000):
rc.incr('count')
time.sleep(0.01)
除了计数,还有很多竞争资源并发写的例子。为了程序简单,下面就用计数这个例子来讨论怎么用redis事务来解决
乐观锁解决竞争问题
check-and-set.py
import redis
import time
rc = redis.StrictRedis()
def add():
with rc.pipeline() as pipe:
try:
pipe.watch('count')
count = int(pipe.get('count')) + 1
pipe.multi()
pipe.set('count', count)
pipe.execute()
except redis.WatchError:
add()
finally:
pipe.reset()
for i in range(1000):
add()
time.sleep(0.01)
先将count清0,将这个程序起两个终端同时执行,在查看count值
127.0.0.1:6379> get count "2000"
Redis命令
Redis性能测试
redis 性能测试的基本命令如下:
redis-benchmark [option] [option value]
| 序号 | 选项 | 描述 | 默认值 |
|---|---|---|---|
| 1 | -h | 指定服务器主机名 | 127.0.0.1 |
| 2 | -p | 指定服务器端口 | 6379 |
| 3 | -s | 指定服务器 socket | |
| 4 | -c | 指定并发连接数 | 50 |
| 5 | -n | 指定请求数 | 10000 |
| 6 | -d | 以字节的形式指定 SET/GET 值的数据大小 | 2 |
| 7 | -k | 1=keep alive 0=reconnect | 1 |
| 8 | -r | SET/GET/INCR 使用随机 key, SADD 使用随机值 | |
| 9 | -P | 通过管道传输 <numreq> 请求 |
1 |
| 10 | -q | 强制退出 redis。仅显示 query/sec 值 | |
| 11 | --csv | 以 CSV 格式输出 | |
| 12 | -l | 生成循环,永久执行测试 | |
| 13 | -t | 仅运行以逗号分隔的测试命令列表。 | |
| 14 | -I | Idle 模式。仅打开 N 个 idle 连接并等待。 |
keep-alive对性能的影响
1w个SET操作的请求,保持TCP连接情况下用了0.11s
redis-benchmark -n 10000 -t set -k 1 ====== SET ====== 10000 requests completed in 0.11 seconds 50 parallel clients 3 bytes payload keep alive: 1 99.99% <= 1 milliseconds 100.00% <= 1 milliseconds 87719.30 requests per second
1w个SET操作的请求,不保持TCP连接情况下用了1.7s,因为TCP通过三次握手来建立连接,频繁的建立连接比较耗时
redis-benchmark -n 10000 -t set -k 0 ====== SET ====== 10000 requests completed in 1.70 seconds 50 parallel clients 3 bytes payload keep alive: 0 5.15% <= 1 milliseconds ... 5878.90 requests per second
并发连接数对性能影响
5个client并发20W SET请求用了2.27s
redis-benchmark -n 200000 -t set -c 5 ====== SET ====== 200000 requests completed in 2.27 seconds 5 parallel clients 3 bytes payload keep alive: 1 99.99% <= 1 milliseconds ... 88300.22 requests per second
50个client并发20W SET请求2.28s,
redis-benchmark -n 200000 -t set -c 50 ====== SET ====== 200000 requests completed in 2.28 seconds 50 parallel clients 3 bytes payload keep alive: 1 99.71% <= 1 milliseconds ... 87565.68 requests per second
500个client并发20W SET请求2.62, 多client并发请求对性能影响不大
redis-benchmark -n 200000 -t set -c 500 ====== SET ====== 200000 requests completed in 2.62 seconds 500 parallel clients 3 bytes payload keep alive: 1 0.00% <= 3 milliseconds ... 76248.57 requests per second