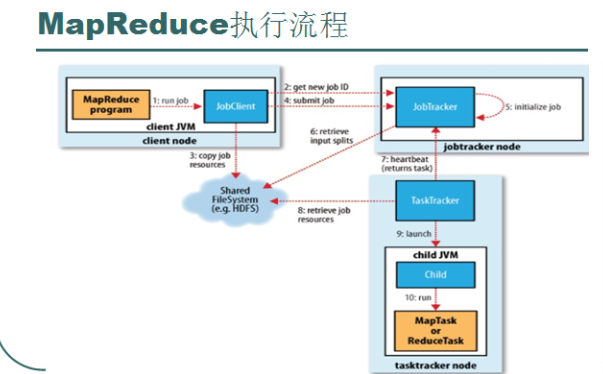
1、运行mapreduce程序 ---run
2、本次运行将会生成呢个一个Job , 于是JobClient向JobTracker申请一个JobID 标识该Job.
3、JobClient将Job需要的资源提交到HDFS中以一个JobID命名的目录中,这些资源包括JAR
包,配置文件,inputSplit等
4、JobClient向JobTracker提交这个Job
5、JobTracker初始化这个Job
6、JobTracker从HDFS中获取需要的信息。
7、通过heartbeat获取可用的DataNode,分配TaskTracker
8、各个TaskTracker向HDFS获取需要的资源信息
9、TaskTracker运行该任务
10、向HDFS返回执行的结果。