第一篇博客。分析一下一个简单的正则表达式引擎的实现。这个引擎是Ozan S. Yigit(Dept. of Computer Science, York University)根据4.nBSD UN*X中的regex routine编写的,在他的个人主页上可以找到源码。引擎支持的特性不多,但源码不到1000行,而且是典型的compile-execute模式,逻辑清晰,对理解正则表达式的工作原理很有帮助。
1 受支持的特性
引擎支持的正则表达式特性如下。
| 字符 | 解释 | |
|---|---|---|
| 常规字符 |
除了元字符(. [ ] * + ^ $)以外的字符。 匹配字符本身 |
|
| . | 匹配任意字符 | |
| [set] |
character class。 匹配所有set中的字符。 如果set的第一个字符是^,表示匹配所有不在set内的字符。 快捷写法S-E表示匹配从字符S到字符E的所有字符。 例: [a-z] 匹配 任意一个小写字母 [^]-] 匹配 除了 "]" 和 "-" 以外的任意字符 [^A-Z] 匹配 除了大写字母以外的任意字符 [a-zA-Z] 匹配 任意字母 |
|
| * |
closure。匹配零个或多个指定符号。 它只能紧跟在常规字符、"." 、character class或closure的后面。 它会尽可能多地匹配满足条件的字符。 |
|
| + |
匹配一个或多个指定符号。其他规则与*相同。 |
|
| (group) |
captured group。匹配group中的符号。 在其后的表达式中可以使用1 ~ 9引用这个group |
|
| 1 ~ 9 | 引用之前匹配的group | |
| < |
匹配单词开头的边界。 单词是一个或多个由字母、数字和下划线组成的序列。 |
|
| > | 匹配单词末尾的边界。 | |
| 其他字符 | 匹配字符本身。主要用于对元字符进行转义 | |
| ^ |
如果^是表达式的第一个字符,表示匹配字符串的开头; 否则将匹配^字符本身。 |
|
| $ |
如果$是表达式的最后一个字符,表示匹配字符串的末尾; 否则将匹配$字符本身。 |
|
2 工作原理
引擎首先将表达式编译为NFA,然后使用这个NFA匹配字符串。
2.1 编译
引擎扫描整个表达式,并生成一个NFA。NFA的结构是一个由opcode组成的序列。所有opcode如下。
| opcode | operand | 解释 |
|---|---|---|
| CHR | 字符 | 匹配一个字符 |
| ANY | 匹配任意一个字符 | |
| CCL | bitset |
character class。 操作数为16 byte的bitset,其中每个bit都 与一个ASCII字符匹配。 |
| BOL | 匹配字符串开头 | |
| EOL | 匹配字符串末尾 | |
| BOT | 1~9 | 标识一个captured group的开头 |
| EOT | 1~9 | 标识一个captured group的结尾 |
| BOW | 匹配单词开头的边界 | |
| EOW | 匹配单词末尾的边界 | |
| REF | 1~9 | 引用group |
| CLO |
closure。 一个CLO ... END pair所包含的内容为closure的内容。 |
|
| END | 标识NFA结束或closure结束 |
例:
表达式: foo*.*
NFA: CHR f CHR o CLO CHR o END CLO ANY END END
匹配: fo foo fooo foobar fobar foxx ...
表达式: fo[ob]a[rz]
NFA: CHR f CHR o CCL bitset CHR a CCL bitset END
匹配: fobar fooar fobaz fooaz
表达式: foo\+
NFA: CHR f CHR o CHR o CHR CLO CHR END END -- x+ 被转换成 xx*
匹配: foo foo\ foo\ ...
表达式: (foo)[1-3]1
NFA: BOT 1 CHR f CHR o CHR o EOT 1 CCL bitset REF 1 END
匹配: foo1foo foo2foo foo3foo
表达式: (fo.*)-1
NFA: BOT 1 CHR f CHR o CLO ANY END EOT 1 CHR - REF 1 END
匹配: foo-foo fo-fo fob-fob foobar-foobar ...
编译生成的NFA保存在一个全局char数组中:
#define MAXNFA 1024 static CHAR nfa[MAXNFA];
re_comp()函数接受一个表达式字符串并编译生成NFA。如果编译失败,则返回错误信息的字符串,否则返回0。
1 char *re_comp(char *pat) { 2 char *p; /* pattern pointer */ 3 CHAR *mp = nfa; /* nfa pointer */ 4 CHAR *lp; /* saved pointer.. */ 5 CHAR *sp = nfa; /* another one.. */ 6 7 int tagi = 0; /* tag stack index */ 8 int tagc = 1; /* actual tag count */ 9 10 int n; 11 CHAR mask; /* xor mask CCL */ 12 int c1, c2;
p作为遍历字符串pat的指针使用。mp作为写入nfa数组的指针使用,它始终指向最近写入的数据的下一个位置。lp和sp用于保存mp的位置。
tagi是一个stack的top指针,这个stack保存了当前所处的group编号:
#define MAXTAG 10 static int tagstk[MAXTAG];
tagc是group编号的counter。
剩下的局部变量都作为临时变量。
13 for (p = pat; *p; p++) { 14 lp = mp; 15 switch (*p) { 16 case '.': /* match any char.. */ 17 store(ANY); 18 break;
生成NFA的主循环。
首先使用lp保存当前mp,在for循环末尾再将lp赋值给sp。sp保存了上一个opcode位置的指针。
15行的switch根据不同的字符模式生成opcode和operand。
17行从"."字符生成ANY opcode,store()是一个写入mp的宏:
#define store(x) *mp++ = x
19 case '^': /* match beginning.. */ 20 if (p == pat) 21 store(BOL); 22 else { 23 store(CHR); 24 store(*p); 25 } 26 break; 27 case '$': /* match endofline.. */ 28 if (!p[1]) 29 store(EOL); 30 else { 31 store(CHR); 32 store(*p); 33 } 34 break;
如果^字符是字符串的第一个字符,那么生成 BOL ,否则当作常规字符处理,生成 CHR ^ 。对$字符的处理也类似。
35 case '[': /* match char class..*/ 36 store(CCL); 37 if (*++p == '^') { 38 mask = 0377; 39 p++; 40 } 41 else 42 mask = 0; 43 44 if (*p == '-') /* real dash */ 45 chset(*p++); 46 if (*p == ']') /* real brac */ 47 chset(*p++); 48 while (*p && *p != ']') { 49 if (*p == '-' && p[1] && p[1] != ']') { 50 p++; 51 c1 = p[-2] + 1; 52 c2 = *p++; 53 while (c1 <= c2) 54 chset((CHAR)c1++); 55 } else 56 chset(*p++); 57 } 58 if (!*p) 59 return badpat("Missing ]"); 60 61 for (n = 0; n < BITBLK; bittab[n++] = (char) 0) 62 store(mask ^ bittab[n]); 63 64 break;
35~64行处理character class。
37行判断"["字符后的第一个字符是否是"^",如果是,那么需要在最后bitwise not整个bitset,这里用了一个mask,在最后会将bitset的每个byte和mask做xor操作(62行)。
44行和46行的两个if对出现在character class开头的"-"和"]"字符当作常规字符处理。chset()函数传入一个ASCII字符,将一个临时bitset的对应bit置为1:
static void chset(CHAR c) { bittab[(CHAR) ((c) & BLKIND) >> 3] |= bitarr[(c) & BITIND]; }
chset()函数中涉及的全局变量和宏定义如下:
#define MAXCHR 128 #define CHRBIT 8 #define BITBLK MAXCHR/CHRBIT #define BLKIND 0170 #define BITIND 07 static CHAR bittab[BITBLK]; static CHAR bitarr[] = {1,2,4,8,16,32,64,128};
bittab是一个临时bitset,程序在处理character class时首先将bit信息写入bittab,最后再将bittab写入nfa作为 CCL 的operand。
MAXCHAR是一个ASCII字符所需的bitset空间,BITBLK是一个bitset的字节大小,即MAXCHR/CHRBIT = 128 / 8 = 16字节。
回到case ']'的代码。48行的while循环处理方括号内的字符。49行判断S-E形式,51行获取S的ASCII,之所以要加1(c1 = p[-2] + 1)是因为在上一次循环中已经将S字符的bit置为1了,不再需要置1。52行获取E字符的ASCII,53行的while循环将S~E字符区间的bit全部置为1。
56行处理除了S-E形式以外的常规字符。
61行将bittab的每个字节和mask做xor操作后写入nfa。
65 case '*': /* match 0 or more.. */ 66 case '+': /* match 1 or more.. */ 67 if (p == pat) 68 return badpat("Empty closure"); 69 lp = sp; /* previous opcode */ 70 if (*lp == CLO) /* equivalence.. */ 71 break; 72 switch(*lp) { 73 case BOL: 74 case BOT: 75 case EOT: 76 case BOW: 77 case EOW: 78 case REF: 79 return badpat("Illegal closure"); 80 default: 81 break; 82 } 83 84 if (*p == '+') 85 for (sp = mp; lp < sp; lp++) 86 store(*lp); 87 88 store(END); 89 store(END); 90 sp = mp; 91 while (--mp > lp) 92 *mp = mp[-1]; 93 store(CLO); 94 mp = sp; 95 break;
65行和66行的两个case处理closure。69行将上一个opcode的指针赋值给lp。
70行判断如果出现了两个连续的closure(x**的形式),那么会忽略当前closure。
72行的switch限制closure所包含的内容,必须为常规字符、"."、character class或closure。
84行将x+形式转换为xx*形式,即将上一个opcode和operand复制一遍(lp ~ mp - 1)。
88行和89行添加两个 END ,其中一个是为了后面插入 CLO 预留空间用的。90行~94行将上一个opcode后移一字节,并在空出的位置插入 CLO 。
96 case '\': /* tags, backrefs .. */ 97 switch(*++p) { 98 case '(': 99 if (tagc < MAXTAG) { 100 tagstk[++tagi] = tagc; 101 store(BOT); 102 store(tagc++); 103 } 104 else 105 return badpat("Too many \(\) pairs"); 106 break; 107 case ')': 108 if (*sp == BOT) 109 return badpat("Null pattern inside \(\)"); 110 if (tagi > 0) { 111 store(EOT); 112 store(tagstk[tagi--]); 113 } 114 else 115 return badpat("Unmatched \)"); 116 break;
98行的case处理"("。100行将当前group counter值压入tagstk,然后生成 BOT tagc 。
107行处理")"。108行的if防止出现空的group。111行和112行生成 EOT x ,并从tagstk中弹出原group counter值。
117 case '<': 118 store(BOW); 119 break; 120 case '>': 121 if (*sp == BOW) 122 return badpat("Null pattern inside \<\>"); 123 store(EOW); 124 break;
上面的两个case处理"<"和">"。121行的if防止出现空的单词(<>)。
125 case '1': case '2': case '3': case '4': case '5': 126 case '6': case '7': case '8': case '9': 127 n = *p-'0'; 128 if (tagi > 0 && tagstk[tagi] == n) 129 return badpat("Cyclical reference"); 130 if (tagc > n) { 131 store(REF); 132 store(n); 133 } 134 else 135 return badpat("Undetermined reference"); 136 break;
处理group引用。128行防止出现循环引用(当前正位于某个group中时对这个group进行引用)。
130行的if防止引用尚未存在的group。
137 default: 138 store(CHR); 139 store(*p); 140 } 141 break;
对于"x"中x的其他情况,直接生成 CHR x 。
142 default : /* an ordinary char */ 143 store(CHR); 144 store(*p); 145 break; 146 }
如果*p是常规字符,生成 CHR x 。
147 if (tagi > 0) 148 return badpat("Unmatched \("); 149 store(END);150 return 0; 151 }
在主循环结束后,判断表达式中的(和)是否匹配(tagi == 0)。最后向nfa写入一个 END 。
2.2 匹配
在生成NFA后,就可以用这个NFA对目标字符串进行匹配。
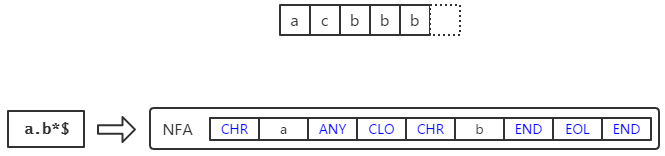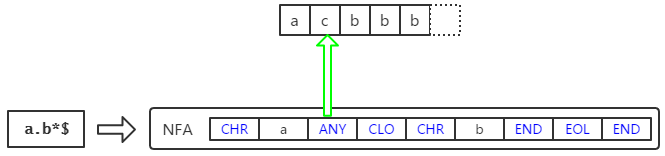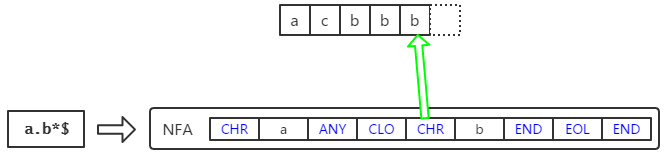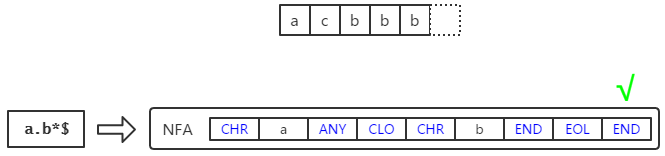
这里要对NFA分三种情况:
1) 开头是 BOL 。此时仅在字符串开头使用整个NFA进行一次匹配;
2) 开头是 CHR x 。此时需要在字符串中找到字符x第一次出现的位置,然后从这个位置开始使用NFA进行匹配,如果匹配失败则从下一个位置开始使用NFA匹配;

3) 其他情况。从字符串开头开始使用NFA匹配,若匹配失败则从字符串的第二个字符开始使用NFA匹配,以此类推。
closure的处理
closure要尽可能多地匹配符合条件的字符,因此要先跳过所有匹配的字符,从第一个不匹配的字符开始用剩余的NFA进行匹配,若匹配失败则向前移动一个字符,继续使用NFA匹配。
函数re_exec()接受一个字符串,使用全局nfa进行匹配。若匹配成功则返回非0,并将所有匹配的group的start offset和end offset放入全局变量:
static char *bol; char *bopat[MAXTAG]; char *eopat[MAXTAG];
bopat和eopat分别保存group的start offset和end offset。其中group 0是整个匹配的字符串。bol在匹配的过程中保存字符串地址。
1 int re_exec(char *lp) { 2 CHAR c; 3 char *ep = 0; 4 CHAR *ap = nfa; 5 6 bol = lp; 7 8 memset(bopat, 0, sizeof (char *) * MAXTAG); 9 10 switch(*ap) { 11 case BOL: /* anchored: match from BOL only */ 12 ep = pmatch(lp,ap); 13 break; 14 case CHR: /* ordinary char: locate it fast */ 15 c = *(ap+1); 16 while (*lp && *lp != c) 17 lp++; 18 if (!*lp) /* if EOS, fail, else fall thru. */ 19 return 0; 20 default: /* regular matching all the way. */ 21 do { 22 if ((ep = pmatch(lp,ap))) 23 break; 24 lp++; 25 } while (*lp); 26 break; 27 case END: /* munged automaton. fail always */ 28 return 0; 29 } 30 if (!ep) 31 return 0; 32 33 bopat[0] = lp; 34 eopat[0] = ep; 35 return 1; 36 }
10行的switch处理nfa的3种情况。如果nfa第一个opcode是 BOL ,从字符串开头进行一次匹配。pmatch()函数是使用NFA匹配字符串的核心函数,它返回匹配的字符串的end offset。如果第一个opcode是 CHR x ,16行的while将找到x字符第一次出现的位置,之后和第三种情况一样处理。其他情况下,21行的do-while循环将逐个以字符串的每个字符开始使用NFA匹配。在匹配完后,将start offset和end offset分别保存到bopat[0]和eopat[0]。
1 static char *pmatch(char *lp, CHAR *ap) { 2 int op, c, n; 3 char *e; /* extra pointer for CLO */ 4 char *bp; /* beginning of subpat.. */ 5 char *ep; /* ending of subpat.. */ 6 char *are; /* to save the line ptr. */ 7 8 while ((op = *ap++) != END) 9 switch(op) { 10 case CHR: 11 if (*lp++ != *ap++) 12 return 0; 13 break; 14 case ANY: 15 if (!*lp++) 16 return 0; 17 break; 18 case CCL: 19 c = *lp++; 20 if (!isinset(ap,c)) 21 return 0; 22 ap += BITBLK; 23 break;
8行的循环遍历整个nfa,并根据不同的opcode做不同处理。 CHR x 的处理是直接对*lp和x进行判断。 ANY 匹配任意字符,因此只需要判断字符串中是否有剩余字符。 CCL bitset 需要判断字符在bitset中对应bit是否为1,使用isinset这个宏实现:
#define isinset(x,y) ((x)[((y)&BLKIND)>>3] & bitarr[(y)&BITIND])
22行跳过bitset所占用的nfa空间。
24 case BOL: 25 if (lp != bol) 26 return 0; 27 break; 28 case EOL: 29 if (*lp) 30 return 0; 31 break;
BOL 和 EOL 的处理很简单,只要判断lp是否是字符串首地址或末尾。
32 case BOT: 33 bopat[*ap++] = lp; 34 break; 35 case EOT: 36 eopat[*ap++] = lp; 37 break;
BOT n 和 EOT n 分别将当前的字符串指针写入bopat和eopat数组。
38 case BOW: 39 if (lp!=bol && iswordc(lp[-1]) || !iswordc(*lp)) 40 return 0; 41 break; 42 case EOW: 43 if (lp==bol || !iswordc(lp[-1]) || iswordc(*lp)) 44 return 0; 45 break;
BOW 成功的条件是上一个字符是非单词字符(或没有上一个字符,即位于字符串开头)并且当前字符是单词字符。iswordc()宏判断某个字符是否为单词字符。
EOW 成功的条件是前一个字符是单词字符且当前字符是非单词字符,如果当前位于字符串开头那么判断也将失败。
这两个opcode都不匹配任何字符,他们只是匹配字符的边界:

46 case REF: 47 n = *ap++; 48 bp = bopat[n]; 49 ep = eopat[n]; 50 while (bp < ep) 51 if (*bp++ != *lp++) 52 return 0; 53 break;
REF n 先从bopat和eopat取出group n的start offset和end offset,对字符串中的每个字符逐个与start offset ~ end offset中的字符做比较。
54 case CLO: 55 are = lp; 56 switch(*ap) { 57 58 case ANY: 59 while (*lp) 60 lp++; 61 n = ANYSKIP; 62 break; 63 case CHR: 64 c = *(ap+1); 65 while (*lp && c == *lp) 66 lp++; 67 n = CHRSKIP; 68 break; 69 case CCL: 70 while ((c = *lp) && isinset(ap+1,c)) 71 lp++; 72 n = CCLSKIP; 73 break; 74 default: 75 re_fail("closure: bad nfa.", *ap); 76 return 0; 77 } 78 79 ap += n; 80 81 while (lp >= are) { 82 if (e = pmatch(lp, ap)) 83 return e; 84 --lp; 85 } 86 return 0;
CLO 的处理比较复杂。首先使用临时变量are保存当前字符串指针lp。接下来对closure包含的内容的三种不同情况分别处理。
对于 ANY ,将直接把lp移动到字符串末尾。将ANYSKIP(值为2)赋给n,n是nfa指针ap将跳过的字节数(79行)。这种情况下NFA的opcode序列如下:
CLO ANY END ...
此时ap指向 ANY ,需要跳过2个字节才能移动到下一个opcode,因此ANYSKIP值为2。
对于 CHR x ,跳过所有字符x。CHRSKIP值为3( CLO CHR x END )。
对于 CCL bitset ,跳过所有位于bitset中的字符。CCLSKIP值为18( CLO CCL bitset (16 bytes) END )。
81行从当前lp开始使用剩余的NFA递归调用pmatch()匹配,并不断向前移动lp指针,直到lp小于are指针。
87 default: 88 re_fail("re_exec: bad nfa.", op); 89 return 0; 90 } 91 return lp; 92 }
最后返回当前lp指针,即最后一个匹配的字符的下一个字符的位置。