spark 运行架构基本由三部分组成,包括SparkContext(驱动程序),ClusterManager(集群资源管理器)和Executor(任务执行过程)组成。
其中SparkContext负责与ClusterManager通信,进行资源的申请.任务的分配.监控等,负责作业执行的声明周期管理。ClusterManager负责资源的分配和管理,在不同模式下担任的角色有所不同,在本地运行.Spark Standalone等运行模式中由Master提供,在YARN运行模式作用由Resource Manager担任,在Mesos运行模式下由Mesos Manager进行负责。当SparkContext对作业划分并分配资源后,会把任务发送给Excutor进行运行。
每个应用程序获取专属的Executor进程,这些进程在应用程序运行的过程中一直驻留,并以多线程方式运行任务。这种隔离机制有一下两种优势,一从调度来看,每个Driver段调度它的自己任务,二从运行角度,来自不同应用程序的任务运行在不同的JVM。这也意味着spark应用程序不能跨应用程序共享数据,排除将数据写入外部存储系统。
对于潜在的资源管理器来说,spark是不可知的,也就是说,spark与资源管理器无关,只要能够获取Executor进程,并能保持相互通信就可以了。
TaskScheduler是最重要的Spark调度器之一,它负责任务的的调度执行,而SchedulerBackend则负责应用程序运行期间与底层资源调度系统交互。应用程序的运行过程:
首先,在SparkContext启动时,调用TaskScheduler.start方法启动TaskScheduler调取器;
然后,当DAGScheduler调度阶段和任务拆分完毕时,调用TaskScheduler.submitTasks方法提交任务,SchedulerBackend接到执行任务时,通过reviveOffers方法分配运行资源并启动运行节点的Executor;
最后,由TaskScheduler接受任务运行状态,如果任务运行完毕,则继续分配,直至应用程序所有任务运行完毕。
TaskScheduler:该类是高层类DAGScheduler与任务执行SchedulerBackend的桥梁。是特质类(trait),定义了任务调度相关的实现方法,TaskSchedulerImp1是其重要的子类,它实现了TaskScheduler的所有接口方法,而TaskScheduler的孙子类YarnScheduler和YarnCluterScheduler只是重写了其中一两个个方法
SchedulerBackend:该类为特质类(trait),子类根据不同运行模式分为本地模式的LocalBackend,粗粒度运行模式的CoarseGrainedSchedulerBackend和细粒度的Mesos运行模式的MesosSchedulerBackend等,粗粒度运行模式包括独立运行模式的SparkDeploySchedulerBackend,YARN运行模式的YarnSchedulerBackend和粗粒度Mesos运行模式的CoarseMesosSchedulerBacken等,其中YARN运行模式根据SparkContext运行位置不同分为yarn-client运行模式的YarnClientSchedulerBackend和yarn-cluster运行模式的YarnClusterScheduerBackend。
在不同运行模式中任务调度器具体为:
Spark on Standalone模式为TaskScheduler;
YARN-Client模式为YarnClientClusterScheduler
YARN-Cluster模式为YarnClusterScheduler
本地(local)运行模式
spark所有进程都运行在一个机器的JVM中,该运行模式一般用户测试等用途。在运行中,如果在命令中不添加配置,spark默认设置为local模式,本地模式标准写法为local[N],N表示打开N个线程进行多个线程运行。
伪分布(local_cluster)运行模式
在一台机器上模拟集群运行,相对于独立运行模式,master,worker,sparkcontext在不同节点,伪分布运行模式中这些进程都是在一台机器上。
伪分布运行模式既可以在$SPARK_HOME/conf/slaves配置worker节点为本地机器名来实现,也可以在脚本中通过执行local-cluster匹配字符串来执行。
伪分布模式下启动spark-shell:
[root@host conf]# spark-shell --master local-cluster[3,2,1024] //模拟启动三个worker进程,每个worker进程启动2个CPU和1024MB内存
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
18/08/16 14:53:23 WARN util.Utils: Service 'SparkUI' could not bind on port 4040. Attempting port 4041.
18/08/16 14:53:57 WARN metastore.ObjectStore: Failed to get database global_temp, returning NoSuchObjectException
Spark context Web UI available at http://192.168.53.122:4041
Spark context available as 'sc' (master = local-cluster[3,2,1024], app id = app-20180816145326-0000).
Spark session available as 'spark'.
Welcome to
____ __
/ __/__ ___ _____/ /__
_ / _ / _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_ version 2.2.0
/_/
Using Scala version 2.11.8 (Java HotSpot(TM) 64-Bit Server VM, Java 1.8.0_101)
Type in expressions to have them evaluated.
Type :help for more information.
scala> val aa=sc.makeRDD(1 to 10)
aa: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[0] at makeRDD at <console>:24
scala> import org.apache.spark.TaskContext
import org.apache.spark.TaskContext
scala> val mapRDD=aa.map(x=>(TaskContext.getPartitionId,x))
mapRDD: org.apache.spark.rdd.RDD[(Int, Int)] = MapPartitionsRDD[1] at map at <console>:27
scala> mapRDD.sortBy(_._2,false).collect
res0: Array[(Int, Int)] = Array((5,10), (5,9), (4,8), (4,7), (3,6), (2,5), (2,4), (1,3), (1,2), (0,1))
查看:http://192.168.53.122:4041,发现确实启动了3个worker,每个work启动两个CPU
相同的语句在本地模式下只启动一个work,根据机器CPU数启动了4个任务。
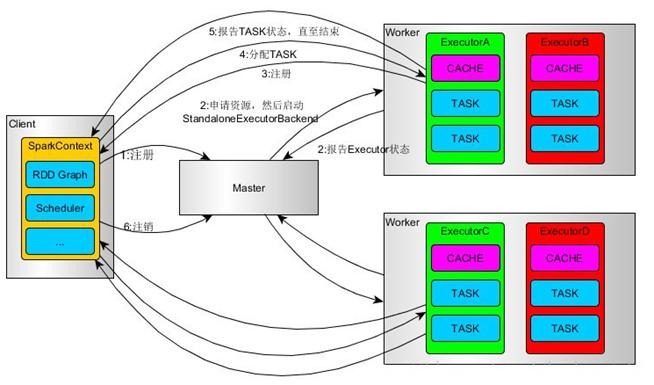
Standalone模式
Standalone模式是Spark实现的资源调度框架,其主要的节点有Client节点、Master节点和Worker节点。其中Driver既可以运行在Master节点上中,也可以运行在本地Client端。当用spark-shell交互式工具提交Spark的Job时,Driver在Master节点上运行;当使用spark-submit工具提交Job或者在Eclips、IDEA等开发平台上使用”new SparkConf.setManager(“spark://master:7077”)”方式运行Spark任务时,Driver是运行在本地Client端上的。
其运行过程如下:
1.SparkContext连接到Master,向Master注册并申请资源(CPU Core 和Memory);
2.Master根据SparkContext的资源申请要求和Worker心跳周期内报告的信息决定在哪个Worker上分配资源,然后在该Worker上获取资源,然后启动StandaloneExecutorBackend;
3.StandaloneExecutorBackend向SparkContext注册;
4.SparkContext将Applicaiton代码发送给StandaloneExecutorBackend;并且SparkContext解析Applicaiton代码,构建DAG图,并提交给DAG Scheduler分解成Stage(当碰到Action操作时,就会催生Job;每个Job中含有1个或多个Stage,Stage一般在获取外部数据和shuffle之前产生),然后以Stage(或者称为TaskSet)提交给Task Scheduler,Task Scheduler负责将Task分配到相应的Worker,最后提交给StandaloneExecutorBackend执行;
5.StandaloneExecutorBackend会建立Executor线程池,开始执行Task,并向SparkContext报告,直至Task完成。
6.所有Task完成后,SparkContext向Master注销,释放资源
YARN是一种统一资源管理机制,在其上面可以运行多套计算框架
Spark on YARN模式根据Driver在集群中的位置分为两种模式:一种是YARN-Client模式,另一种是YARN-Cluster(或称为YARN-Standalone模式)。
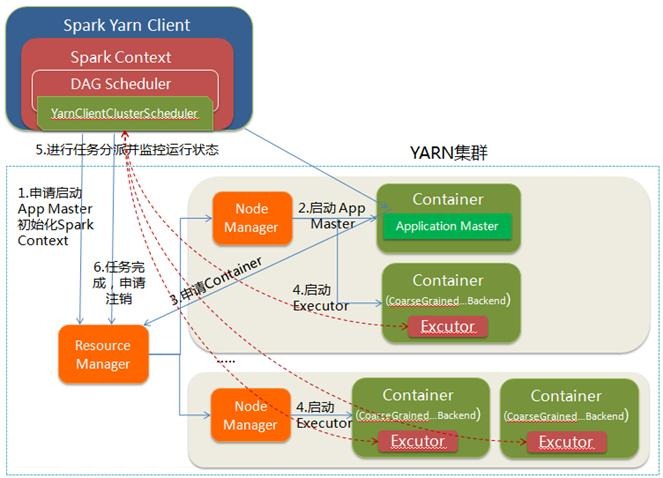
YARN-Client模式
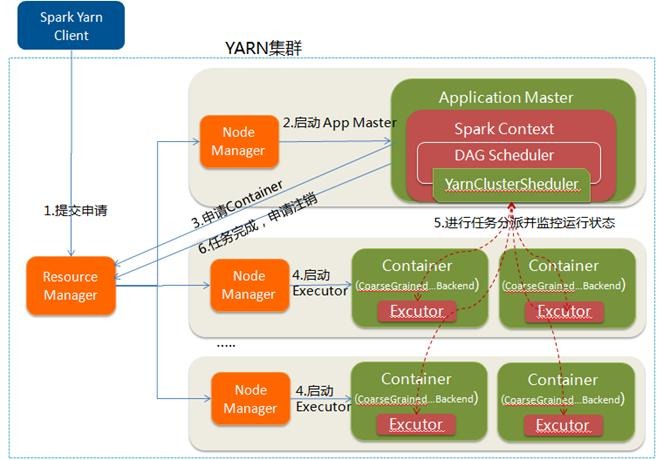
1.Spark Yarn Client向YARN的ResourceManager申请启动Application Master。同时在SparkContent初始化中将创建DAGScheduler和TASKScheduler等,由于我们选择的是Yarn-Client模式,程序会选择YarnClientClusterScheduler和YarnClientSchedulerBackend;
2.ResourceManager收到请求后,在集群中选择一个NodeManager,为该应用程序分配第一个Container,要求它在这个Container中启动应用程序的ApplicationMaster,与YARN-Cluster区别的是在该ApplicationMaster不运行SparkContext,只与SparkContext进行联系进行资源的分派;
3.Client中的SparkContext初始化完毕后,与ApplicationMaster建立通讯,向ResourceManager注册,根据任务信息向ResourceManager申请资源(Container);
4.一旦ApplicationMaster申请到资源(也就是Container)后,便与对应的NodeManager通信,要求它在获得的Container中启动启动CoarseGrainedExecutorBackend,CoarseGrainedExecutorBackend启动后会向Client中的SparkContext注册并申请Task;
5.Client中的SparkContext分配Task给CoarseGrainedExecutorBackend执行,CoarseGrainedExecutorBackend运行Task并向Driver汇报运行的状态和进度,以让Client随时掌握各个任务的运行状态,从而可以在任务失败时重新启动任务;
6.应用程序运行完成后,Client的SparkContext向ResourceManager申请注销并关闭自己。
YARN-Cluster
在YARN-Cluster模式中,当用户向YARN中提交一个应用程序后,YARN将分两个阶段运行该应用程序:第一个阶段是把Spark的Driver作为一个ApplicationMaster在YARN集群中先启动;第二个阶段是由ApplicationMaster创建应用程序,然后为它向ResourceManager申请资源,并启动Executor来运行Task,同时监控它的整个运行过程,直到运行完成。
YARN-cluster的工作流程分为以下几个步骤:
1. Spark Yarn Client向YARN中提交应用程序,包括ApplicationMaster程序、启动ApplicationMaster的命令、需要在Executor中运行的程序等;
2. ResourceManager收到请求后,在集群中选择一个NodeManager,为该应用程序分配第一个Container,要求它在这个Container中启动应用程序的ApplicationMaster,其中ApplicationMaster进行SparkContext等的初始化;
3. ApplicationMaster向ResourceManager注册,这样用户可以直接通过ResourceManage查看应用程序的运行状态,然后它将采用轮询的方式通过RPC协议为各个任务申请资源,并监控它们的运行状态直到运行结束;
4.一旦ApplicationMaster申请到资源(也就是Container)后,便与对应的NodeManager通信,要求它在获得的Container中启动启动CoarseGrainedExecutorBackend,CoarseGrainedExecutorBackend启动后会向ApplicationMaster中的SparkContext注册并申请Task。这一点和Standalone模式一样,只不过SparkContext在Spark Application中初始化时,使用CoarseGrainedSchedulerBackend配合YarnClusterScheduler进行任务的调度,其中YarnClusterScheduler只是对TaskSchedulerImpl的一个简单包装,增加了对Executor的等待逻辑等;
5.ApplicationMaster中的SparkContext分配Task给CoarseGrainedExecutorBackend执行,CoarseGrainedExecutorBackend运行Task并向ApplicationMaster汇报运行的状态和进度,以让ApplicationMaster随时掌握各个任务的运行状态,从而可以在任务失败时重新启动任务;
6.应用程序运行完成后,ApplicationMaster向ResourceManager申请注销并关闭自己。
YARN-Client 与 YARN-Cluster 区别
理解YARN-Client和YARN-Cluster深层次的区别之前先清楚一个概念:Application Master。在YARN中,每个Application实例都有一个ApplicationMaster进程,它是Application启动的第一个容器。它负责和ResourceManager打交道并请求资源,获取资源之后告诉NodeManager为其启动Container。从深层次的含义讲YARN-Cluster和YARN-Client模式的区别其实就是ApplicationMaster进程的区别。
YARN-Cluster模式下,Driver运行在AM(Application Master)中,它负责向YARN申请资源,并监督作业的运行状况。当用户提交了作业之后,就可以关掉Client,作业会继续在YARN上运行,因而YARN-Cluster模式不适合运行交互类型的作业;
YARN-Client模式下,Application Master仅仅向YARN请求Executor,Client会和请求的Container通信来调度他们工作,也就是说Client不能离开。
YARN-Client模式下启动spark-shell
[root@host hadoop-2.7.4]# spark-shell --master yarn --num-executors 3 --executor-memory 1g
Setting default log level to "WARN".
To adjust logging level use sc.setLogLevel(newLevel). For SparkR, use setLogLevel(newLevel).
18/08/16 16:42:49 WARN ipc.Client: Address change detected. Old: host/192.168.53.122:8032 New: host/127.0.0.1:8032
18/08/16 16:42:57 WARN yarn.Client: Neither spark.yarn.jars nor spark.yarn.archive is set, falling back to uploading libraries under SPARK_HOME.
18/08/16 16:43:16 WARN ipc.Client: Address change detected. Old: host/192.168.53.122:8032 New: host/127.0.0.1:8032
18/08/16 16:44:11 WARN metastore.ObjectStore: Failed to get database global_temp, returning NoSuchObjectException
Spark context Web UI available at http://192.168.53.122:4040
Spark context available as 'sc' (master = yarn, app id = application_1534408393915_0001).
Spark session available as 'spark'.
Welcome to
____ __
/ __/__ ___ _____/ /__
_ / _ / _ `/ __/ '_/
/___/ .__/\_,_/_/ /_/\_ version 2.2.0
/_/
Using Scala version 2.11.8 (Java HotSpot(TM) 64-Bit Server VM, Java 1.8.0_101)
Type in expressions to have them evaluated.
Type :help for more information.
scala> import org.apache.spark.TaskContext
import org.apache.spark.TaskContext
scala> val aa=sc.makeRDD(1 to 10)
aa: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[0] at makeRDD at <console>:25
scala> val mapRDD=aa.map(x=>(TaskContext.getPartitionId,x))
mapRDD: org.apache.spark.rdd.RDD[(Int, Int)] = MapPartitionsRDD[1] at map at <console>:27
scala> mapRDD.sortBy(_._2,false).collect
res0: Array[(Int, Int)] = Array((2,10), (2,9), (2,8), (2,7), (1,6), (1,5), (1,4), (0,3), (0,2), (0,1))
查看http://192.168.53.122:8088/cluster: Executor的启动过程:
Executor的启动过程:
在集群中由master给应用程序分配资源后,然后在worker中启动ExecutorRunner,而ExcutorRunner根据当前的运行模式启动CoarseGrainedExecutorBackend进程,当该进程会向driver发送注册Executor信息,如果注册成功,则CoarseGrainedExecutorBackend在其内部启动Executor。CoarseGrainedExecutorBackend和Executor是一一对应的,CoarseGrainedExecutorBackend是Executor运行所在的进程名称,Executor才是真正在处理Task的对象,Executor内部是通过线程池的方式来完成Task的计算的。CoarseGrainedExecutorBackend是一个消息通信体(其实现了ThreadSafeRpcEndpoint)。可以发送信息给Driver,并可以接收Driver中发过来的指令,例如启动Task等。
部分引用自:https://www.cnblogs.com/shishanyuan/p/4721326.html