源代码:
#unicoding=utf-8
import re
import urllib
def gethtml(url):
html=urllib.urlopen(url)
page=html.read()
return page
def img(page):
reg=r'src="(.+?jpg)" alt'
imgre=re.compile(reg)
imglist=re.findall(imgre,page)
x=0
for imgurl in imglist:
urllib.urlretrieve(imgurl,'%s.jpg' % x)
x+=1
#page=gethtml("http://www.51tietu.net/tp/")
page=gethtml("http://mm.51tietu.net/qingchun/90/")
img(page)
这样执行的话,会出现IOError 大致意思时文件操作时,出现错误
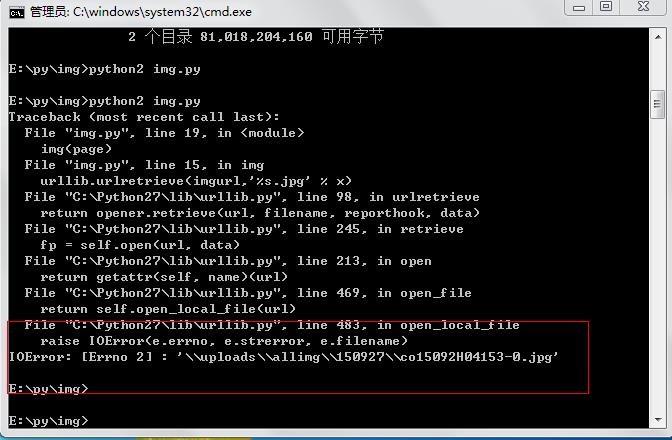
在这里可以看到IOError后跟着你抓取到的jip文件的路径,但是这个路径不是整个url的路径,所以才会在urlretrieve调用imgurl的时候报错。
去网站查看整个URL

因此可以根据图中的url进行修改代码, 想法:可以在urlretrieve中把url补完整,之后代码如下
#unicoding=utf-8
import re
import urllib
def gethtml(url):
html=urllib.urlopen(url)
page=html.read()
return page
def img(page):
reg=r'src="(.+?jpg)" alt'
imgre=re.compile(reg)
imglist=re.findall(imgre,page)
x=0
for imgurl in imglist:
urllib.urlretrieve('http://mm.51tietu.net'+imgurl,'%s.jpg' % x)
x+=1
#page=gethtml("http://www.51tietu.net/tp/")
page=gethtml("http://mm.51tietu.net/qingchun/90/")
img(page)
之后再进行运行的话,就可以将图片爬取到本地了。
效果如下:
