select语法一般结构:
1 SELECT [ALL|DISTINCT] <目标列表达式> [别名] [, <目标列表达式> [别名]]... 2 FROM <表名或视图名> [别名] [,<表名或视图名> [别名]]... 3 [WHERE <条件表达式>] 4 [GROUP BY <列名1> [HAVING <条件表达式>]] 5 [ORDER BY <列名2>[ASC|DESC]
可知select语句是由几个组件或者说子句构成。有一些子句不可缺少(select子句),但有一些可以不用使用。
| 子句名称 | 使用目的 |
| select | 确定结果集中应该包含哪些列 |
| from | 指明所要提取数据的表, 以及这些表是如何连接的 |
| where | 过滤不需要的数据 |
| group by | 用于对具有相同列值的行进行分组 |
| having | 过滤掉不需要的组(必须同group by子句一起用) |
| order by | 按一个或多个列,对最后结果集中的行进行排序 |
0.select子句
作为select语句第一个部分,select是最后被执行的,因为需要知道结果集中所有可能包含的列。
select * from department;
这里*代表通配符,意思是从department表中选择所有的列,相当于将department中所有属性都写出来,如果要只显示需要的属性列,直接写出即可。当然也可以对select子句进行一下修饰。
- 字符,比如数字或字符串
- 表达式,如dept_id * 3
- 调用内建函数,如upper(name)
- 用户自定义的函数
通过查询,返回的是每个列的默认属性名,也可以自定义名,即取别名,可以属性名后直接加别名,也可以属性名 as 别名。
默认情况select语句是不去除重复行的,若不需要则在其后加distinct,如果显示所有的则用all(默认)。但是一定要注意:使用distinct,数据库会对查询结果进行排序,这对于较大的结果集是很浪费时间的,降低效率,因此不要随意使用。
1.frome子句
from子句定义了查询中所用的表,以及连接这些表的方式。
2.where子句
where子句用于在结果集中过滤掉不需要的行。
where后面跟的是条件表达式,满足条件的元组将会被选出。如:
select emp_id, fname, lname, start_date, title from employee where title = 'Head Teller';
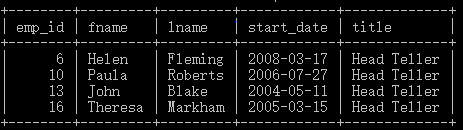
可以看出,仅仅title为Head Teller的元组被列了出来。
条件表达式是多种多样的,这里仅仅用了,相等的条件,其他表达式以后解释。
3.group by和having子句
group by子句用于根据列值对数据进行分组。having子句与group by子句配合使用,选取满足条件的元组。
select d.name, count(e.emp_id) num_employees from department d inner join employee e on d.dept_id = e.dept_id group by d.name having count(e.emp_id) > 2;
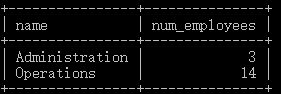
4.order by子句
order by子句用于对结果集中的原始列数据或是根据列数据计算的表达式结果进行排序。
如一般情况下的查询
select open_emp_id, product_cd from account;

可见结果没有次序,如果使用order by子句
select open_emp_id, product_cd from account order by open_emp_id;

从结果上看,结果按照open_emp_id升序排列(默认),如果想要降序排列,则在后面跟desc。也可以按照多个属性升序或降序排列。