我们知道,性能测试的目的是分析判断性能瓶颈并调优,最终得出性能结果来评估系统的性能指标是否满足既定值。
那么,如何能做好分析,显然是非常重要的。
通常来说,对于性能分析有这样一幅阶梯图:

- 工具操作:包括压力工具、监控工具、剖析工具、调试工具。
- 数值理解:包括上面工具中所有输出的数据。
- 趋势分析、相关性分析、证据链分析:就是理解了工具产生的数值之后,还要把它们的逻辑关系想明白。这才是性能测试分析中最重要的一环。
- 调优:这是最后一步,调优的方案策略就有很多种了,具体选择取决于调优成本和产生的效果。
在做性能分析的时候,需要融合以上的能力。高楼老师归纳了性能分析思路大纲:
- 瓶颈的精准判断
- 线程递增的策略
- 性能衰减的过程
- 响应时间的拆分
- 构建分析决策树
- 场景的对比
一、瓶颈的精准判断
通常,在性能测试过程中,我们会不断观察 TPS 和 响应时间的曲线图,从中分析出性能的拐点。值得注意的是:大部分系统其实是没有明确的拐点。
TPS 曲线
通常,如果画一幅示意图来描述 TPS 的衰减过程,大概会如下所示:
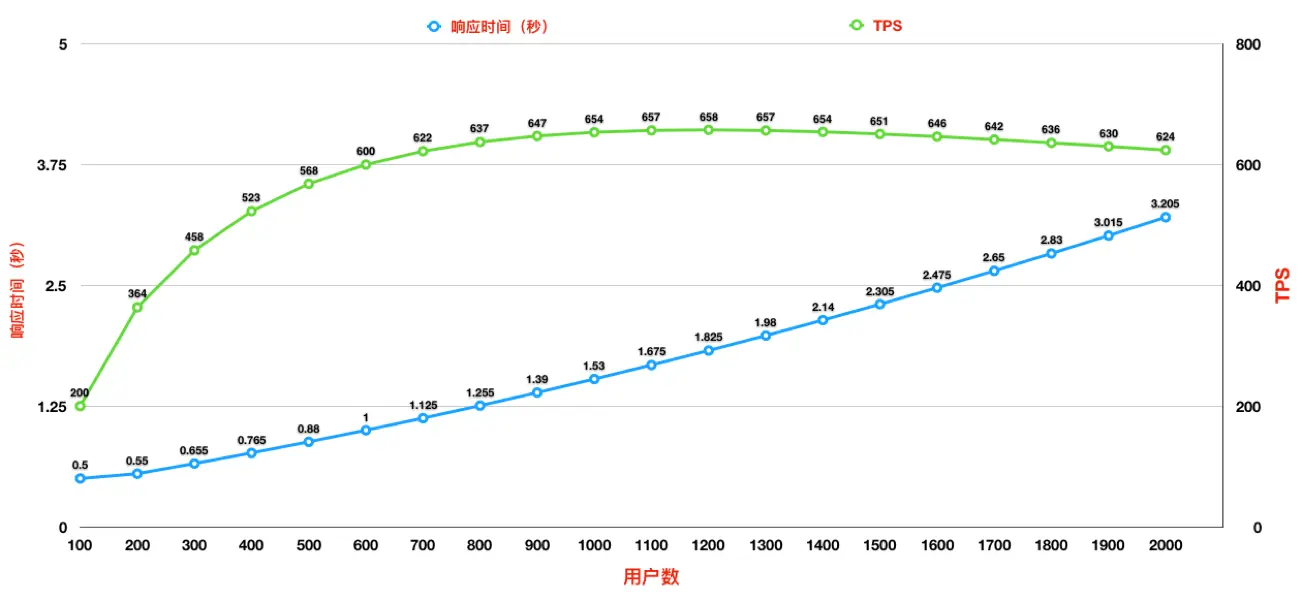
- 随着用户数的增加,响应时间也在缓慢增加。
- TPS 前期一直都有增加,但是增加的幅度在变缓,直到变平。
在这样的趋势图中,我们是看不到明确的拐点的。但是可以判断有瓶颈。
所以,TPS 曲线可以明确告诉我们:
- 是否存在瓶颈:准确来说,所有的系统都有性能瓶颈,只不过看我们在哪个量级做性能测试。
- 瓶颈和压力是否有关:TPS 随着压力的变化而变化,那就是有关系。另一种,不管压力增不增加,TPS 都会出现曲线趋势问题,那就是无关。
响应时间 曲线
TPS 用来判断容量有多大,而响应时间则是用来判断业务有多快。
看2个对应的图,分别是线程数和响应时间:
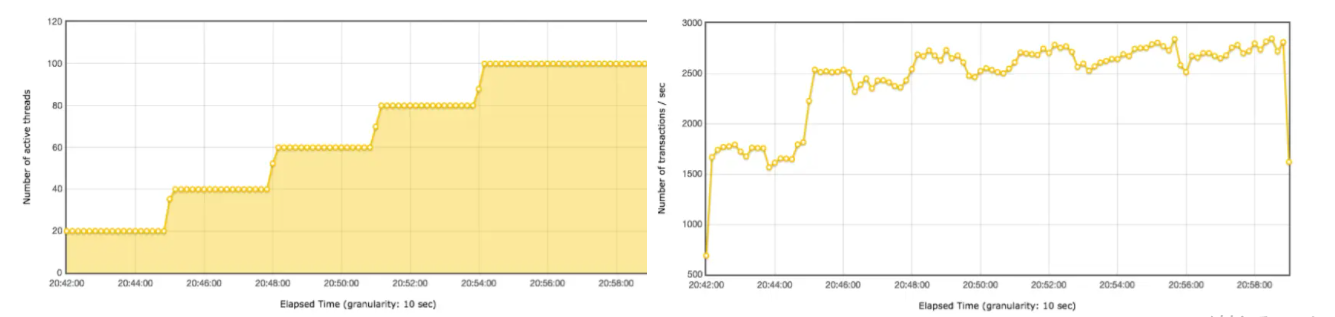
很明显,随着线程的增多,响应时间也在增加。
ok,接着再看一下对应的 TPS 图:
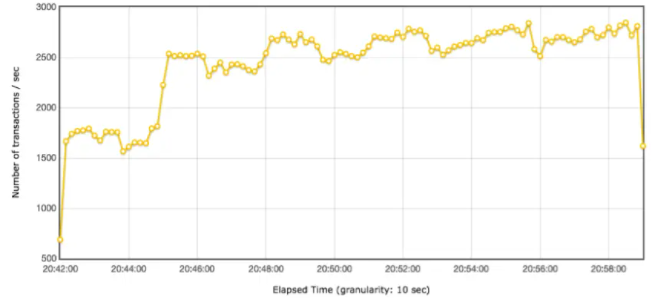
如果这时候我们只看 TPS 曲线,其实也可能判断出:存在瓶颈,和压力有关。到第 40 个线程时,TPS 基本上达到上限,为 2500 左右。
所以说,其实 TPS 就可以告诉我们系统有没有瓶颈了,而响应时间是用来判断业务有多快的。
但是,响应时间会是性能分析调优的重要分析对象。
二、线程递增的策略
递增与一次性加到最大是有很大区别的。
比如,做了2个场景:
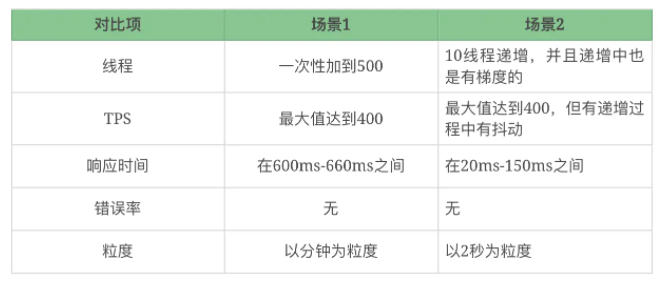
这里场景1 就是不合理的。
我们要确定设置的性能场景是正确的,线程是逐渐递增的,而不应该一上来就上几百个线程,这样不符合一般情况下的真实场景。
即便是秒杀场景,真实的生产环境,也会有个数据预热的过程。在预热之后,线程突增产生的压力,也是在可处理范围的。
此外,对于已经 TPS 已经达到上限的情况,再增加更多的线程,除了响应时间的增加,没有其他作用。
这里高楼老师还给出了做性能场景递增的经验值:

- 这个参考递增幅度不是适用所有系统,根据实际的测试过程来做相应的判断
- 响应时间少,递增幅度小。因为响应时间小的话,每个线程产生的TPS就高,如果线程增加多,整体的压力增加的就快,不利于产生明显的性能梯度用来分析。
还要补充一个点:线程递增过程不能断。
原因是保证在测试过程中资源分配的合理性,减少偏差,便于分析出当前环境中的性能瓶颈点。否则断开后系统动态资源会重新分配,造成分析偏差。
三、性能衰减的过程
有了瓶颈的判断能力,也有了线程递增的意识,接下来就要有判断性能衰减的能力。
这是一个压力过程中产生的结果图:
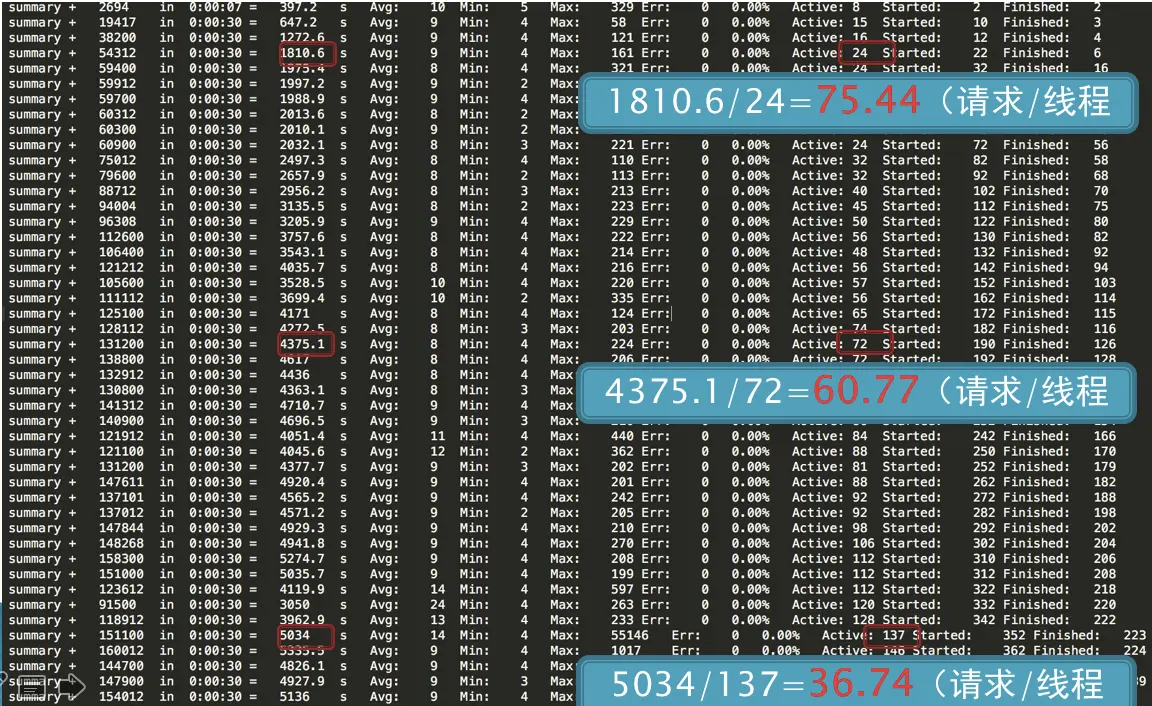
- 在线程达到 24 时,TPS 为 1810.6,也就是每线程每秒发出 75.44 个请求。
- 在线程达到 72 时,TPS 为 4375.1,也就是每线程每秒发出 60.77 个请求。
- 在线程达到 137 时,TPS 为 5034,也就是每线程每秒发出 36.74 个请求。
每线程每秒发出的请求数在变少,但是整体 TPS 是在增加的。继续看下面的分析对比图:
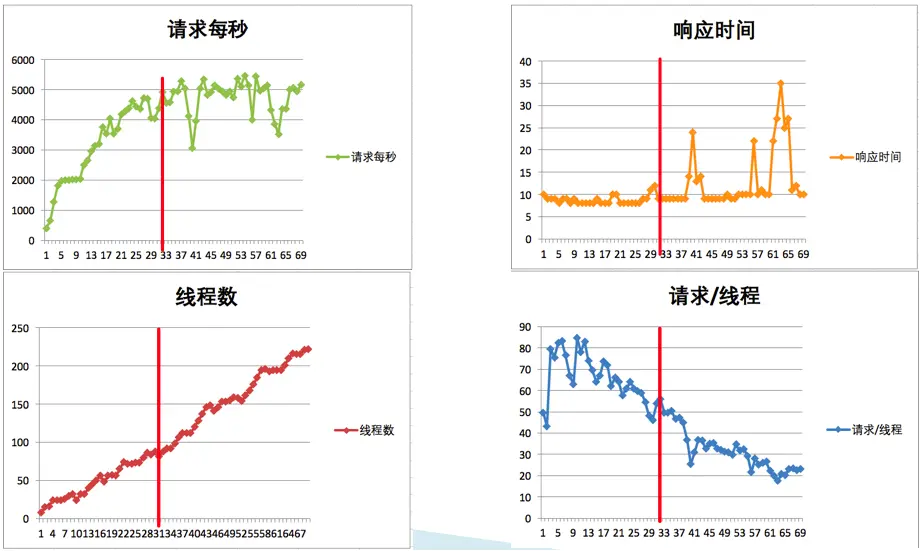
从图1中,找到 TPS 的瓶颈位置在5000,线程数维度大概在30个(红线区分)。
然后通过红线的大致比对可以知道,当每线程每秒的请求数降到 55 左右的时候,TPS 就达到上限了,再接着往上增加线程已经没有用了,响应时间开始往上增加。
这就是性能衰减的过程:
- 只要每线程每秒的 TPS 开始变少,就意味着性能瓶颈已经出现了。
- 但是瓶颈出现之后,并不是说服务器的处理能力下降。
- TPS 仍然会上升,在性能不断衰减的过程中,TPS 就会达到上限。
延伸问题:衰减到最大 TPS 时是否停止场景?
这个还是取决于我们的场景目标:
- 如果我们只是为了得到最大 TPS,那确实可以停止。
- 如果为了让瓶颈更为明显,就不需要停止场景,只要不报错,就接着往上压,
四、响应时间的拆分
当我们选择继续施压来扩大瓶颈,后面的响应时间就会变长,直到超时。
由于在压力工具上看到的响应时间,都是经过了后端的每一个系统的,所以我们就需要拆分响应时间,分析出在哪个阶段变长了。
但是,由于应用的架构不同,拆分的方法也不同。
单应用

对单应用来说,思路大概是这样:
- 查看 Nginx 上的时间。
- 查看 Tomcat 上的时间。
- 看前端浏览器的时间消耗,这里建议使用 Content Download 的时间来描述。
微服务

这种再单个拆就很痛苦了,首先要知道每个系统消耗了多长时间,需要链路监控工具来拆分时间。
不管用什么工具和手段去拆分时间,我们的最终目的就是:得到每个环节消耗了多长时间。
五、构建分析决策树
当我们拆分到了某个环节之后,我们就会知道时间消耗在了哪个节点上,接下来就需要:构建分析决策树,找到问题的根本原因。
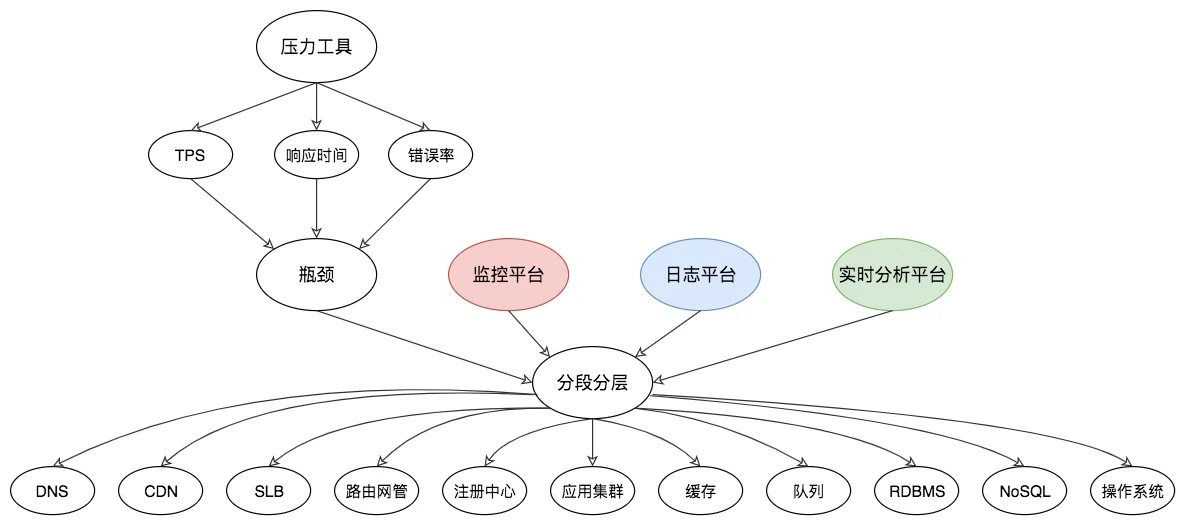
如图所示,从压力工具中,只需要知道 TPS、响应时间和错误率三条曲线,就可以明确判断瓶颈是否存在。再通过分段分层策略,结合监控平台、日志平台,或者其他的实时分析平台,知道架构中的哪个环节有问题,然后再根据更细化的架构图一一拆解下去。比如,定位到数据库有问题,那么就要针对数据库进行进一步的决策树拆解。
这个环节是最重要也是最难的一环。
所以,随着性能分析经验的累加,我们需要整理并总结每次遇到的性能问题以及相对应的解决方法,逐步构建自己的分析决策树。
同时我们还要不断扩充自己的知识库:系统架构、操作系统、数据库、缓存、路由等等,并将这些知识与经验结合起来。重新梳理,由大到小,由宏观到细节,去画出自己的分析决策树。
再总结一下决策树:它是对架构的梳理,是对系统的梳理,是对问题的梳理,是对查找证据链过程的梳理,是对分析思路的梳理。它起的是纵观全局,高屋建瓴的指导作用。
六、场景的比对
当你觉得系统中哪个环节不行的时候,作为小白又没能力分析它,你可以直接做该环节的增加,然后比对增加后的效果。
举例,现在有个架构:

对应的测试结果是这样的:
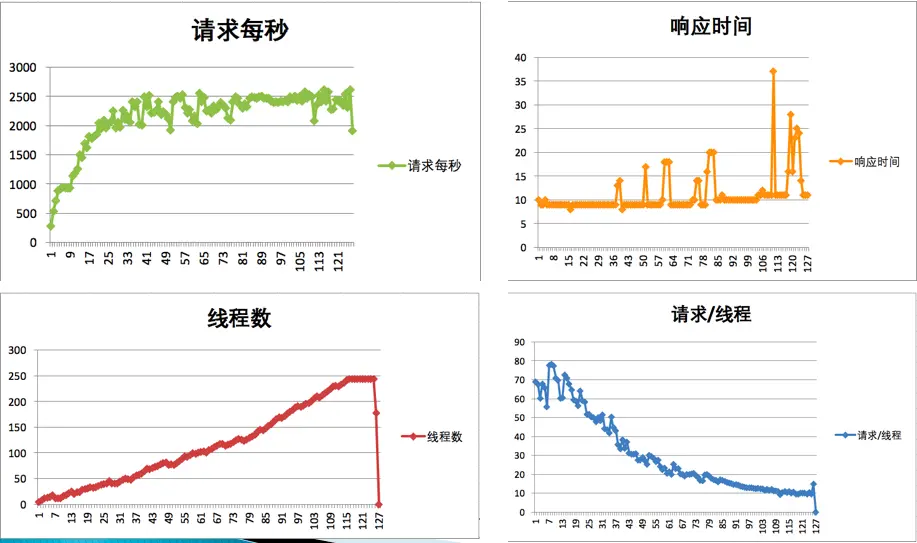
从 TPS 曲线中,我们可以明显看到系统是有瓶颈的,但是并不知道在哪里。
好在系统架构简单,那么我就先尝试在某环节上加上一台服务器,比如:
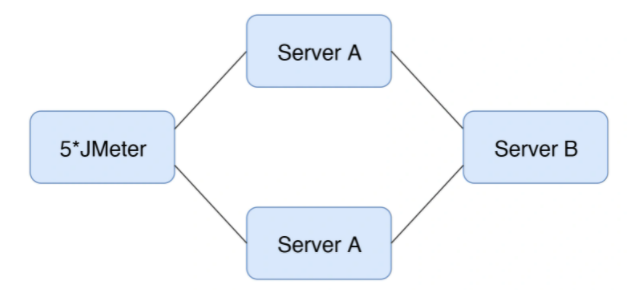
对增加后的进行测试,结果发现没变。
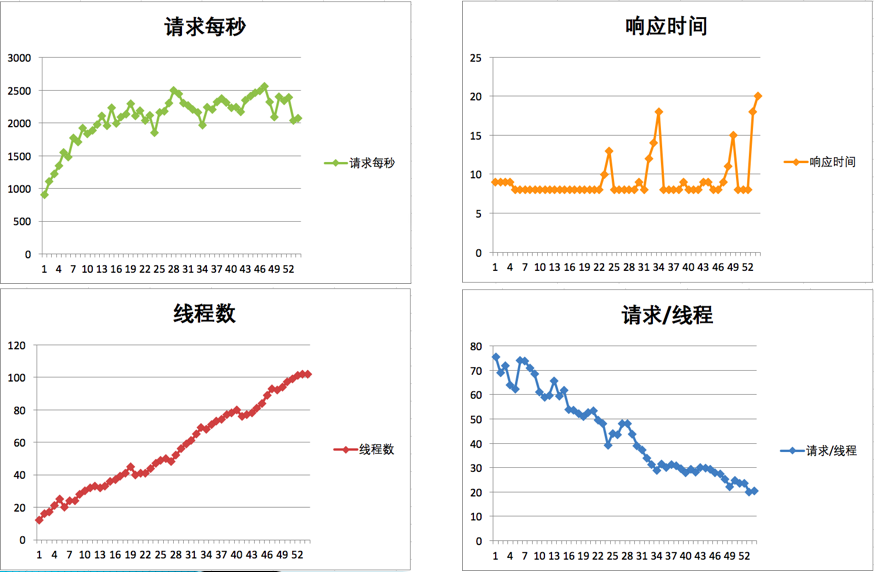
继续增加其他节点:
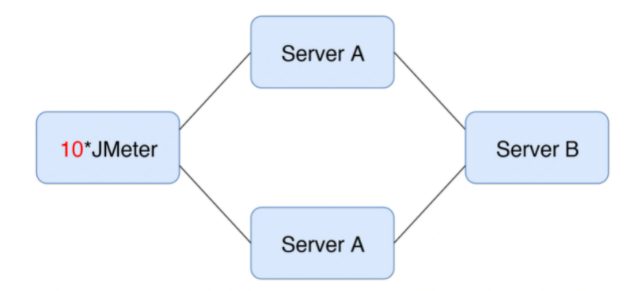
这时候,TPS跟着上去了。
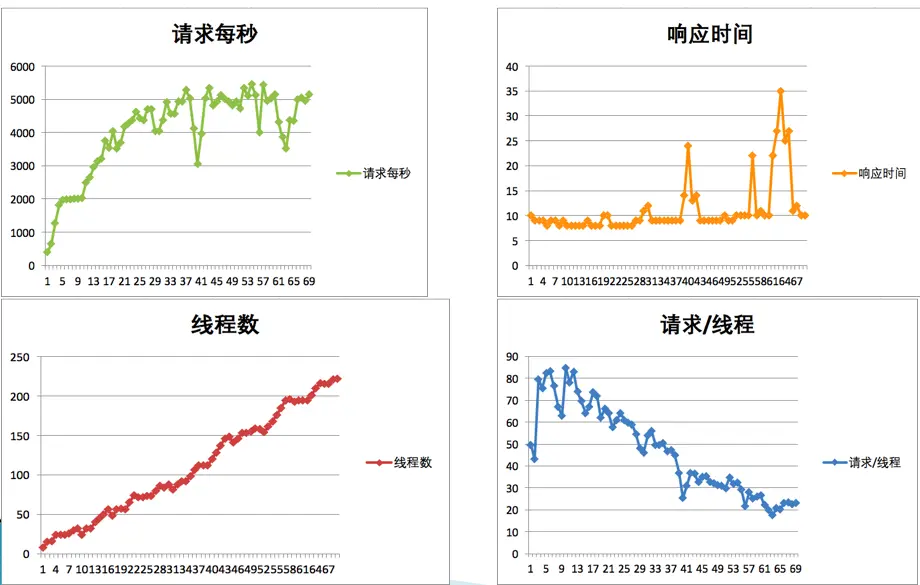
这就是场景比对。但是,局限也很大:只适用架构并不复杂的系统。
七、总结
快速了解了分析中的各个主要环节要做的事情和注意的点。而这里的每一个环节,又有非常多的细分,特别是构建分析决策树这一块,它需要太多的架构知识、系统知识、数据库知识等等。
对于我这种小白来说,是打开了思路,后续要做的就是实践的积累和知识的补充。
本文参考:
高楼老师 性能测试实战30讲