帅图!
@
前戏
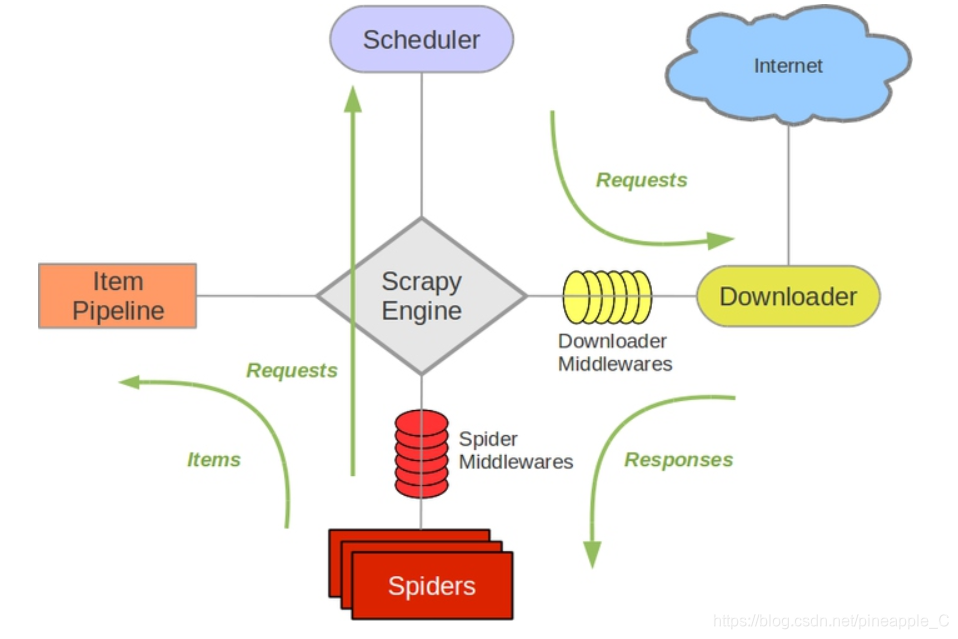
Item Pipeline是项目管道,在item.py中定义的具体项目被爬虫提取出来之后,传给项目管道,进行最后的写入文件,保存至数据库等操作,需要在pipelines.py内编写具体的代码,然后在settings.py内开启指定的Item Pineline
一个Pipeline类中的核心方法是process_item(self, item, spider),执行将项目写入的操作,返回item交给下一个级别的Pipeline继续处理,或者抛出DropItem异常,丢弃Item
其他的方法还有:
- open_spider(self, spider)
- 当开启爬虫时要进行的操作,比如打开一个文件,或者连接数据库
- close_spider(self, spider)
- 当关闭爬虫时要进行的操作,比如关闭一个文件,或者关闭数据库连接
- from_crawler(cls, crawler)
- 用@classmethod标识的类方法,通过crawler参数可以拿到在Scrapy的所有组件,包括在settings内定义的全局变量
下面总结一下Scrapy中最常用的几个Pipeline
CsvWriterPipeline
保存为CSV文件
import csv
class CsvWriterPipeline:
def __init__(self):
self.file = open('storage/national_bus_stations.csv', 'w', encoding='utf-8')
self.my_writer = csv.writer(self.file)
def open_spider(self, spider):
pass
def process_item(self, item, spider):
self.my_writer.writerow(list(dict(item).values()))
return item
def close_spider(self, spider):
self.file.close()
CsvItemPipeline
利用Scrapy的CsvItemExporter,保存为csv文件
from scrapy.exporters CsvItemExporter
class CsvItemPipeline:
def __init__(self):
self.file = open('data.csv', 'w')
self.exporter = CsvItemExporter(self.file)
def open_spider(self, spider):
pass
def process_item(self, item, spider):
self.exporter.export_item(item)
return item
def close_spider(self, spider):
self.file.close()
JsonWriterPipeline
保存为jsonline文件,每一行都是json格式
import json
from itemadapter import ItemAdapter
class JsonWriterPipeline:
def __init__(self):
self.file = open('items.jl', 'w', encoding='utf-8')
def open_spider(self, spider):
pass
def close_spider(self, spider):
self.file.close()
def process_item(self, item, spider):
line = json.dumps(ItemAdapter(item).asdict()) + "
"
self.file.write(line)
return item
JsonItemLinePipeline
利用Scrapy的JsonLinesItemExporter,将提取出的item一条一条地写入json文件
from scrapy.exporters import JsonLinesItemExporter
class JsonItemLinePipeline:
def __init__(self):
self.file = open('storage/national_bus_stations.jl', 'wb')
self.exporter = JsonLinesItemExporter(self.file, encoding='utf-8')
def open_spider(self, spider):
pass
def process_item(self, item, spider):
self.exporter.export_item(item)
return item
def close_spider(self, spider):
self.file.close()
JsonItemPipeline
利用Scrapy的JsonItemExporter,将提取出的item一次性全部写入json文件
from scrapy.exporters import JsonItemExporter
class JsonItemPipeline:
def __init__(self):
self.file = open('data.json', 'w')
self.exporter = JsonItemExporter(self.file, encoding='utf-8')
def open_spider(self, spider):
self.exporter.start_exporting()
def process_item(self, item, spider):
self.exporter.export_item(item)
return item
def close_spider(self, spider):
self.exporter.finish_exporting()
self.file.close()
MongoPipeline
写入MongoDB
import pymongo
from itemadapter import ItemAdapter
class MongoPipeline:
def __init__(self, mongo_uri, mongo_db):
self.mongo_uri = mongo_uri
self.mongo_db = mongo_db
self.client = None
self.db = None
@classmethod
def from_crawler(cls, crawler):
return cls(
mongo_uri=crawler.settings.get('MONGO_URI'),
mongo_db=crawler.settings.get('MONGO_DATABASE', 'items')
)
def open_spider(self, spider):
self.client = pymongo.MongoClient(self.mongo_uri)
self.db = self.client[self.mongo_db]
def process_item(self, item, spider):
self.db[item.collection].insert_one(ItemAdapter(item).asdict())
return item
def close_spider(self, spider):
self.client.close()
其中collection可以在item.py内定义,如
from scrapy import Item, Field
class BusStationItem(Item):
table = collection = 'national_bus_stations'
province_name = Field()
city_name = Field()
area_name = Field()
line_name = Field()
line = Field()
station = Field()
MysqlPipeline
写入Mysql
import pymysql
class MysqlPipeline:
def __init__(self, host, user, port, database, password):
self.host = host
self.user = user
self.port = port
self.database = database
self.password = password
self.db = None
self.cursor = None
@classmethod
def from_crawler(cls, crawler):
return cls(
host=crawler.settings.get('MYSQL_HOST'),
user=crawler.settings.get('MYSQL_USER'),
port=crawler.settings.get('MYSQL_PORT'),
database=crawler.settings.get('MYSQL_DATABASE'),
password=crawler.settings.get('MYSQL_PASSWORD')
)
def open_spider(self, spider):
self.db = pymysql.connect(self.host, self.user, self.password, self.database, self.port, charset='utf8')
self.cursor = self.db.cursor()
def process_item(self, item, spider):
data = dict(item)
keys = ','.join(data.keys())
values = ','.join(['%s'] * len(data))
sql = f'INSERT INTO {item.table} ({keys}) VALUES ({values})'
self.cursor.execute(sql, tuple(data.values()))
self.db.commit()
return item
def close_spider(self, spider):
self.cursor.close()
self.db.close()
表table也和mongo的collection一样,在item.py内指定
AsyncMysqlPipeline
异步写入Mysql
import logging
import pymysql
from twisted.enterprise import adbapi
class AsyncMysqlPipeline:
def __init__(self, db_params):
self.db_params = db_params
self.db_pool = None
@classmethod
def from_crawler(cls, crawler):
return cls(
db_params=dict(
host=crawler.settings.get('MYSQL_HOST'),
user=crawler.settings.get('MYSQL_USER'),
port=crawler.settings.get('MYSQL_PORT'),
database=crawler.settings.get('MYSQL_DATABASE'),
password=crawler.settings.get('MYSQL_PASSWORD'),
charset='utf8',
cursorclass=pymysql.cursors.DictCursor,
use_unicode=True
)
)
def open_spider(self, spider):
self.db_pool = adbapi.ConnectionPool('pymysql', **self.db_params)
self.db_pool.runInteraction(self.do_truncate)
def process_item(self, item, spider):
"""
使用Twisted 异步插入Mysql
"""
query = self.db_pool.runInteraction(self.do_insert, item)
query.addErrback(self.handle_error)
return item
@staticmethod
def handle_error(failure):
"""
记录异常
"""
logging.debug(failure)
@staticmethod
def do_insert(cursor, item):
"""
执行具体的插入操作, 和同步MysqlPipeline一样
"""
data = dict(item)
keys = ','.join(data.keys())
values = ','.join(['%s'] * len(data))
sql = f'INSERT INTO {item.table} ({keys}) VALUES ({values})'
cursor.execute(sql, tuple(data.values()))
def close_spider(self, spider):
self.db_pool.close()
Mysql的相关变量在settings.py内统一配置
# Mysql settings
MYSQL_HOST = 'localhost'
MYSQL_USER = 'root'
MYSQL_PORT = 3306
MYSQL_DATABASE = 'station'
MYSQL_PASSWORD = 'Password123$'
为了对接大数据集群,还有另外自创的两个Pipeline,分别是可以将数据写入远程服务器的RemoteJsonPipeline,和对接远程Flume的RemoteFlumePipeline
RemoteJsonPipeline
利用paramiko库与远程服务器建立ssh连接,使用sftp协议将数据写入远程json文件
import paramiko
from scrapy.exporters import JsonLinesItemExporter
class RemoteJsonPipeline:
def __init__(self, host, port, user, password, file_path):
self.host = host
self.port = port
self.user = user
self.password = password
self.file_path = file_path
self.client = paramiko.SSHClient()
self.sftp = None
self.file = None
self.exporter = None
@classmethod
def from_crawler(cls, crawler):
return cls(
host=crawler.settings.get('SSH_HOST'),
port=crawler.settings.get('SSH_PORT'),
user=crawler.settings.get('SSH_USER'),
password=crawler.settings.get('SSH_PASSWORD'),
file_path=crawler.settings.get('FILE_PATH')
)
def open_spider(self, spider):
self.client.load_system_host_keys()
self.client.set_missing_host_key_policy(paramiko.AutoAddPolicy())
self.client.connect(self.host, self.port, self.user, self.password)
self.sftp = self.client.open_sftp()
self.file = self.sftp.open(self.file_path + 'data.json', 'wb')
self.exporter = JsonLinesItemExporter(self.file, encoding='utf-8')
def process_item(self, item, spider):
self.exporter.export_item(item)
return item
def close_spider(self, spider):
self.file.close()
self.client.close()
其中的SSH变量在settings.py内统一配置:
# SSH settings
SSH_HOST = '172.16.1.2'
SSH_PORT = 22
SSH_USER = 'root'
SSH_PASSWORD = 'passwd'
FILE_PATH = '/opt/'
RemoteFlumePipeline
使用telnetlib库,通过telnet协议与远程服务器建立连接,往Flume监听的端口发送数据,Flume接受到数据后写入HDFS
from telnetlib import Telnet
class RemoteFlumePipeline:
def __init__(self, host, port):
self.host = host
self.port = port
self.tn = None
@classmethod
def from_crawler(cls, crawler):
return cls(
host=crawler.settings.get('FLUME_HOST'),
port=crawler.settings.get('FLUME_PORT')
)
def open_spider(self, spider):
self.tn = Telnet(self.host, self.port)
def process_item(self, item, spider):
text = str(item).replace('
', '').encode('utf-8') + b'
'
self.tn.write(text)
return item
def close_spider(self, spider):
self.tn.close()
Flume的相关变量在settings.py内统一配置
# Flume settings
FLUME_HOST = '172.16.1.2'
FLUME_PORT = 10000