在卷积神经网络尚未火热的年代,人们使用haar/lbp + adaboost级连的组合方式检测人脸,hog+svm的组合方式检测行人。这种传统的目标检测方法一个认知上的优势就是: 模块的功能明确,划分得很清晰,符合人们的理解方式。其中,haar,lbp,hog等手工设计的特征提取算子用于提取特征,adaboost,svm用于对提取的特征分类。
而早期的全连接神经网络,就是属于用于对提取的特征进行分类的模块,我们也可以同样将神经网络替换掉adaboost,svm用于分类。
后来将神经网络用于图像分类中,面对早期的小分辨率图片,我们依旧可以使用特征提取+神经网络分类的模式,也可以直接将每个像素点作为特征输入用于神经网络的分类。但面对后期的大分辨率图像,如果依旧使用逐像素点输入的方式,很明显将会导致全连接中的权值过于稀疏,造成模型训练的困难。
而卷积神经网络中conv+relu(早期为sigmoid)+pooling(以下称三剑客)的组合,不仅可以替代手工设计特征算子的繁琐,而且局部感受野+权值共享的设计思想也能避免全连接网络中的种种弊端。此时人们将三剑客的组合视为特征提取的过程,如果按照早期人们特征提取+分类的设计思路,那么分类使用全连接的设计方式,就可以刚好实现了一个end-to-end的架构,也即早起卷积神经网络的原型。
但必须明白的是,虽然模型完成了一个end-to-end的设计架构,可以直接用于训练和分类,但在人们的认知上,特征提取和分类依然是分开的,也就是说三剑客用于特征提取,全连接用于分类。
后来随着更优秀分类网络的出现(alexnet,vgg等),人们不再仅仅满足于分类准确率的提升,面对动辄两三百M的模型,人们思考能否减少模型的大小。人们通过研究发现,在包含全连接的网络中,全连接的参数占据了所有参数中的大部分比例,这样使得精简全连接参数变得刻不容缓。
于是一部分优秀的人们想到了使用svd等方式减少参数,另一部分优秀的人们开始思考: 是否真的需要使用全连接层,或者有无可以替代全连接层的方法?
于是就出现了如nin,squeezenet中,直接使用global average pooling的方式,直接替代全连接层。人们发现不使用全连接层,模型的检准率并没有降低,而模型的大小却极大的减少(当然了,也包括以上网络中其他模块优化的功劳,如11卷积的使用等)。
另一方面,同样在nin,以及用于图像分类的fcn中,人们发现使用11卷积,也可以达到与全连接层同样的功效,依然能保证同样的检准率
全连接层的设计,属于人们在传统特征提取+分类思维下的一种"迁移学习"思想,但在这种end-to-end的模型中,其用于分类的功能其实是被弱化了
卷积层
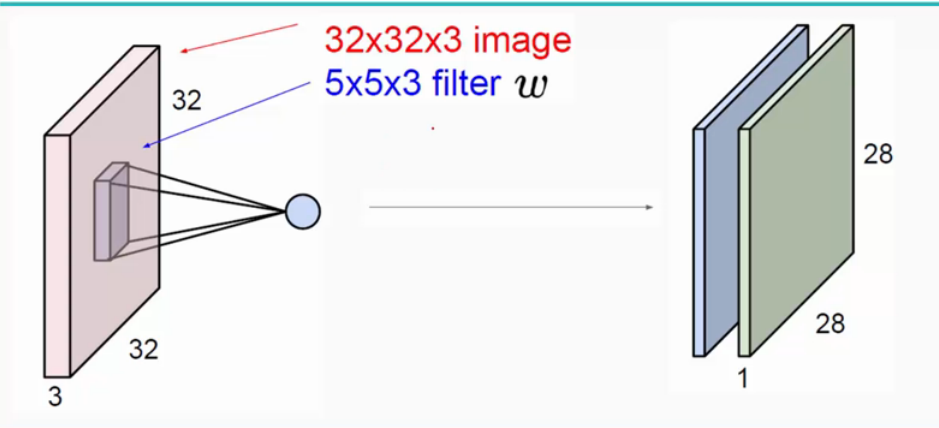
作用
局部感知,在传统神经网络中每个神经元都要与图片上每个像素相连接,这样的话就会造成权重的数量巨大造成网络难以训练。而在含有卷积层的的神经网络中每个神经元的权重个数都时卷积核的大小,这样就相当于没有神经元只与对应图片部分的像素相连接。这样就极大的减少了权重的数量。
参数共享,卷积核的权重是经过学习得到的,并且在卷积过程中卷积核的权重是不会改变的,这就是参数共享的思想。这说明我们通过一个卷积核的操作提取了原图的不同位置的同样特征。简单来说就是在一幅图片中的不同位置的相同目标,它们的特征是基本相同的。
多核卷积,用一个卷积核操作只能得到一部分特征可能获取不到全部特征,这么一来我们就引入了多核卷积。用每个卷积核来学习不同的特征(每个卷积核学习到不同的权重)来提取原图特征
参数更新
使用转置卷积参看之前的文章 深度拾遗(03) - 上采样/下采样/卷积/逆卷积
池化层(Pooling)
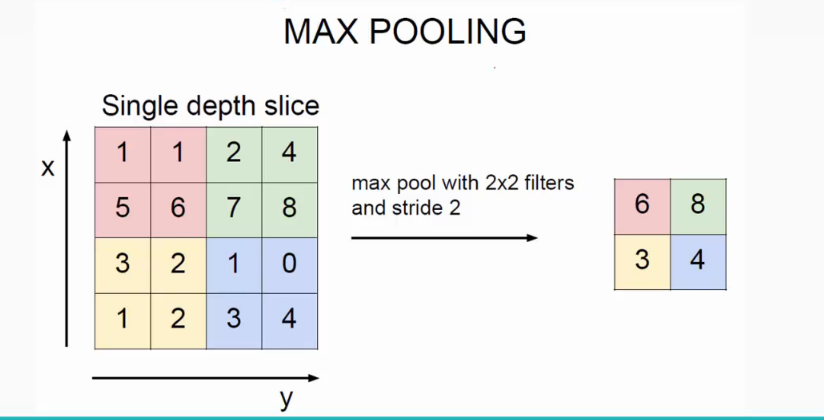
池化层往往跟在卷积层后面。通过平均池化或者最大池化的方法将之前卷基层得到的特征图做一个聚合统计。同时降低了数据量。同时图像具有一种“静态性”的属性,这也就意味着在一个图像区域有用的特征极有可能在另一个区域同样适用。
例如,卷积层输出的特征图中两个相连的点的特征通常会很相似,假设a[0,0],a[0,1],a[1,0],a[1,1]都表示颜色特征是红色,没有必要都保留作下一层的输入。池化层可以将这四个点做一个整合,输出红色这个特征。可以达到降低模型的规模,加速训练的目的。
作用
可以忽略目标的倾斜、旋转之类的相对位置的变化。以此提高精度,同时降低了特征图的维度并且已定成度上可以避免过拟合
参数更新
Average Pooling 的bp好算,直接求导可得,就是1/n
Max Pooling 则在forward的时候需要记录 每个窗口内部最大元素的位置,然后bp的时候,对于窗口内最大元素的gradient是1,否则是0。原理和ReLu是一样的。
全连接层
卷积层、池化层和激活函数层等操作是将原始数据映射到隐层特征空间的话,全连接层则起到将学到的“分布式特征表示”映射到样本标记空间,起到了分类器的作用。
全连接层可视作模型表示能力的“防火墙”,特别是在源域与目标域差异较大的情况下,全连接层可保持较大的模型capacity从而保证模型表示能力的迁移。(冗余的参数并不一无是处。)