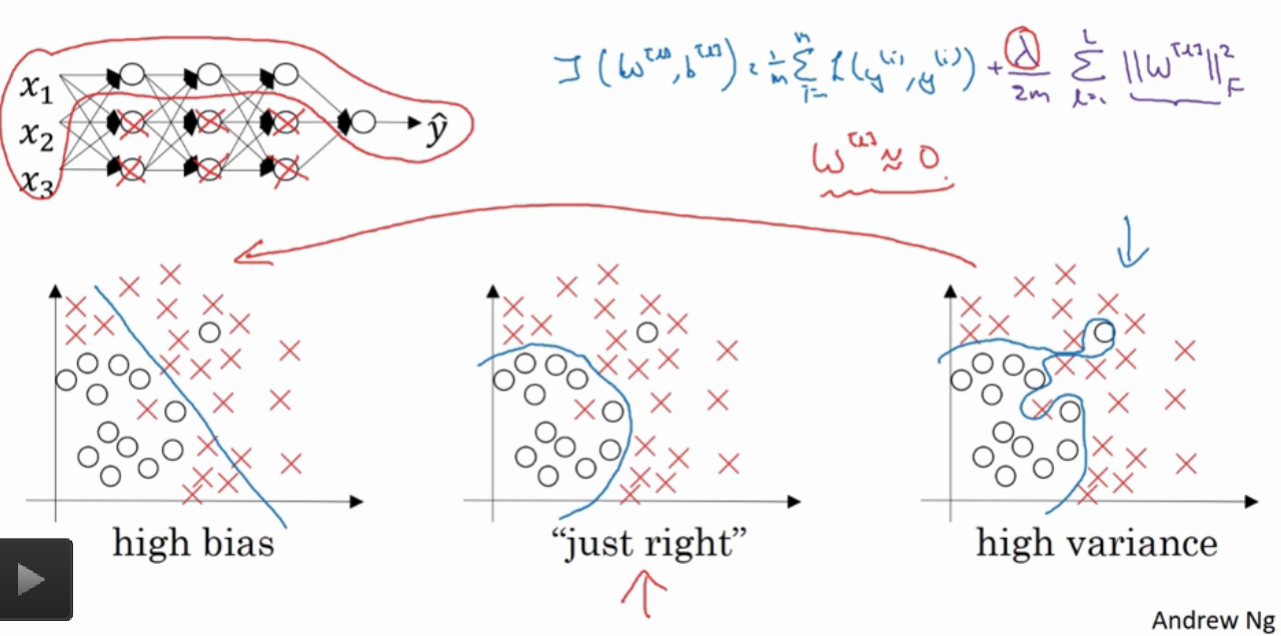
什么是偏差/方差?

偏差(bias) 度量了学习算法的期望预测与真实结果的偏离程序, 即 刻画了学习算法本身的拟合能力
方差(varience) 度量了同样大小的训练集的变动所导致的学习性能的变化, 即 刻画了数据扰动所造成的影响 .
准:bias描述的是根据样本拟合出的模型的输出预测结果的期望与样本真实结果的差距,简单讲,就是在样本上拟合的好不好。要想在bias上表现好,low bias,就得复杂化模型,增加模型的参数,但这样容易过拟合 (overfitting),过拟合对应上图是high variance,点很分散。low bias对应就是点都打在靶心附近,所以瞄的是准的,但手不一定稳。
确:varience描述的是样本上训练出来的模型在测试集上的表现,要想在variance上表现好,low varience,就要简化模型,减少模型的参数,但这样容易欠拟合(unfitting),欠拟合对应上图是high bias,点偏离中心。low variance对应就是点都打的很集中,但不一定是靶心附近,手很稳,但是瞄的不准。
什么是欠拟合/过拟合?
欠拟合就是模型能力不足,偏差大。
过拟合就是模型对于训练数据拟合过于完美,方差大。
为什么要有正则化?
我们需要的是中间那个划分模型,而不是最右边看似完美的划分,因为那个数据点可能由于噪声或者其他原因本身就有问题。
目的是降低过拟合的影响。
一般解决过拟合有减少特征数量,手动选择一些需要保留的特征,正则化。常见正则化有L2正则,L1正则。
为什么正则可以?
我们首先做一个极端的假设,假设正则项系数 (λ) 非常大,那么为了满足(minJ(w,b))这个运算,则必须使得(w[l]≈0w[l]≈0)
但是这样会极大的简化神经网络的结构,简单地说可能就是从非常复杂的非线性结构转变成了线性结构,这时得到了最左边的模型,但显然也不行,这是欠拟合
所以需要取中间的值,让模型恰到好处,就如中间的模型一样。
深度中的正则化
- Dropout
- early stopping
- Data augmentation
Dropout
每层每个节点以某一概率(这里以50%为例)被选中为需要删除的节点(如下图中标上X的节点),被选中为删除的节点,不仅要删除节点,与之相连的线段也要删除.
使用反向传播算法对精简后的神经网络进行权重更新计算
恢复被删节点,然后循环往复上面的步骤,直到得到我们想要的结果。
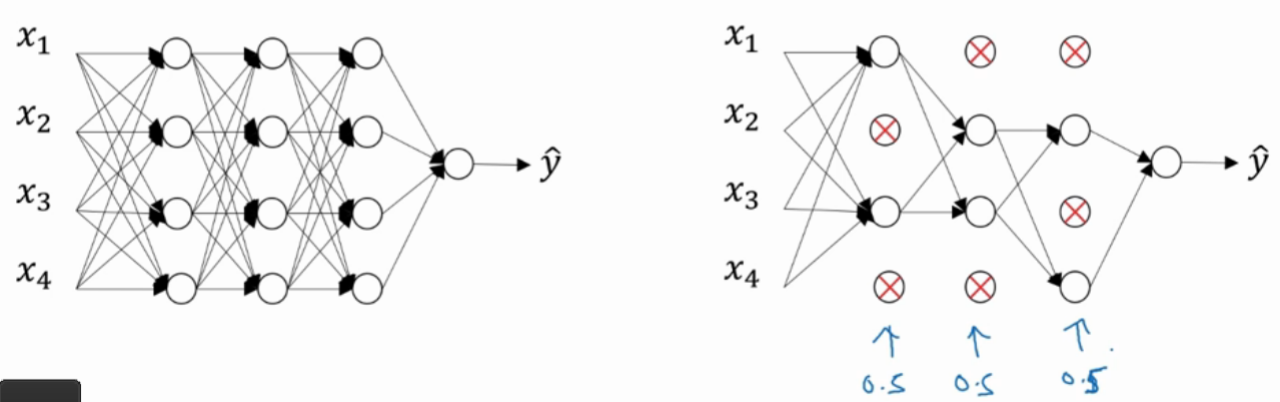
一种常用具体方式,反向随机失活(Inverted Dropout)
keepProb 保留概率
keepProb = 0.8
# d3元素值为True或False
d3 = np.random.rand(a3.shape[0], a3.shape[1]) < keepProb
# 在相乘运算时,python会自动将True转化为1,False转化为0
# 所以可以选出概率小于keepProb的节点继续留下来进行计算(这个大于小于可以根据你自己的想法来实现,不一定是小于)
a3 = np.multiply(a3, d3)
a3 /= keepProb
其中第四行进行的除法目的是为了不影响期望,修正丢失的20%.
early stopping
依据训练集迭代次数(蓝色线)和验证集迭代次数(紫色线)提前终止。

数据扩增
在有限的训练数据时,对已有数据进行缩放,翻转、扭曲等处理得到新的数据,来扩充原数据集,从而达到正则化的目的。

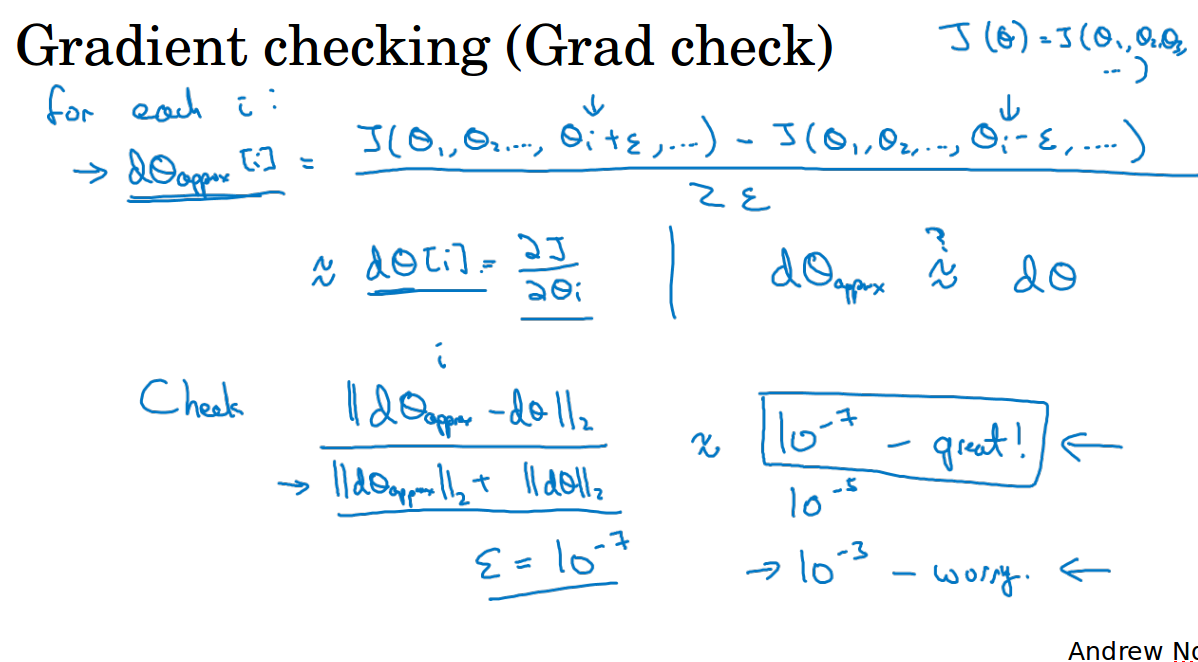
梯度检验
为了验证反向传播是否正确,使用计算导数的方法取一小段计算梯度和反向传播得到的梯度比较
进行梯度检验的时候,考虑某点前进很小很小距离的点,和往后很小小距离的点,考虑了两个点估计的梯度会更准确,渐进误差为这段距离的平方O(ε^2)。
所以我们采用双边误差的估计来进行梯度检验,用双边误差的估计梯度和实际求导的梯度做一个距离计算,看看距离是否足够小。
ng介绍的梯度检验如下第2个图所示,其中Θ[i]表示第i个样本的所有权重,距离公式中的分母只是为了防止数值太大而加的。
需要注意的是,梯度检验和dropout不要同时进行
距离计算的结果是(10^{−7})与(ε)相近,那么可以认为这个梯度计算是正确的。