任务
action detection:先切割视频,然后聚类。
motivation
利用单个视频中,各个子动作之间存在时间顺序关系,比如在做咖啡的视频中,把咖啡倒进杯子里一般会发生在搅拌咖啡之前。
基本流程
这里只介绍基础版本。
给一个视频数据集,每个视频都包含多个子动作,但所有视频主题相同。从中取出一个视频,假设该视频包含N帧,把该视频时间长度归一化,则视频中第n帧时间位置是:t=n/N. 用t作为训练标签。
网络模型如下图左1所示,是包含两层隐藏层的全连接神经网络。
模型训练完成之后,取出每帧视频经过第二层后得到的feature,对这些feature聚类,聚成K类(K是怎么确定的?我暂未细究)。
把这K类中每个feature对应的时间位置进行统计,每个类别内部取均值,按照均值把这些簇按时间顺序排列,如下图左2、3.
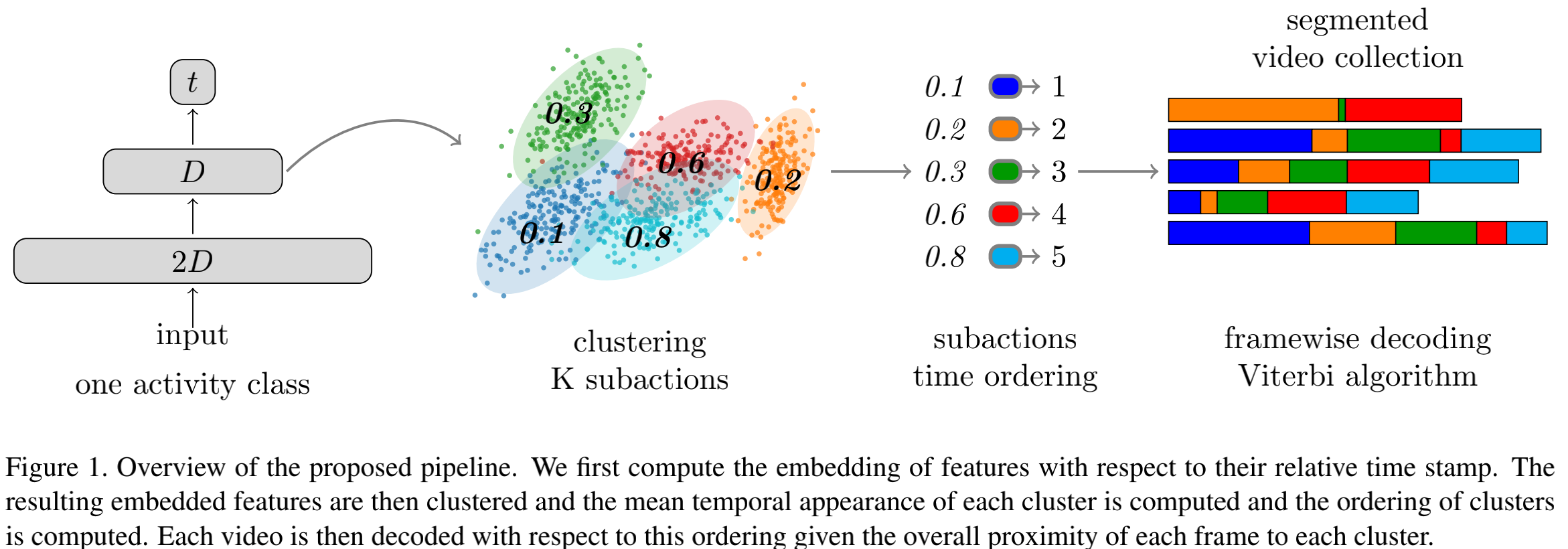
但是上述流程得到的每帧的label不一定consistent,也就是可能上一帧是cluster1,下一帧是cluster2,再下一帧又是cluster1了,很零碎。为了让label更consistent,作者在文章的第3.4,3.5节用高斯分布拟合每帧属于哪一簇的概率分布,然后又最大化概率...等,具体我没去细究。
数据集
Breakfast,YouTube Instructions dataset,50Salads dataset
聚类指标
MoF,IoU