
基于飞桨PaddlePaddle实现的Sub-Pixel图像超分辨率
1.项目介绍
本文则参考论文:Real-Time Single Image and Video Super-Resolution Using an Efficient Sub-Pixel Convolutional Neural Network ,使用飞桨最新的分支版本,实现了一个轻量级图像的超分辨率模型,旨在带领各位小伙伴快速了解飞桨框架2.0,也可以在此基础上修改、优化模型,实现自己的超分辨率算法。
飞桨PaddlePaddle最近迎来了重大更新,进入了2. 0时代。AI Studio也同步上线了最新版本得在线编程环境,又送免费GPU算力,这波羊毛不薅都对不起自己啊(手动狗头)。飞桨框架2.0新添加了许多常用的API,丰富的API接口给开发带来了便利,能够比较轻松的完成模型搭建及训练。如果小伙伴们对本项目感兴趣,欢迎来AI Studio Fork 运行尝试。
下载安装命令 ## CPU版本安装命令 pip install -f https://paddlepaddle.org.cn/pip/oschina/cpu paddlepaddle ## GPU版本安装命令 pip install -f https://paddlepaddle.org.cn/pip/oschina/gpu paddlepaddle-gpu
AI Studio项目地址:
https://aistudio.baidu.com/aistudio/projectdetail/1109418
2.前言
图像和视频通常包含着大量的视觉信息,且视觉信息本身具有直观高效的描述能力,所以随着信息技术的高速发展,图像和视频的应用逐渐遍布人类社会的各个领域。近些年来,在计算机图像处理,计算机视觉和机器学习等领域中,来自工业界和学术界的许多学者和专家都持续关注着视频图像的超分辨率技术这个基础热点问题。
图像超分辨率的英文名称是 Image Super Resolution。它指的是从低分辨率图像中恢复高分辨率图像的过程。
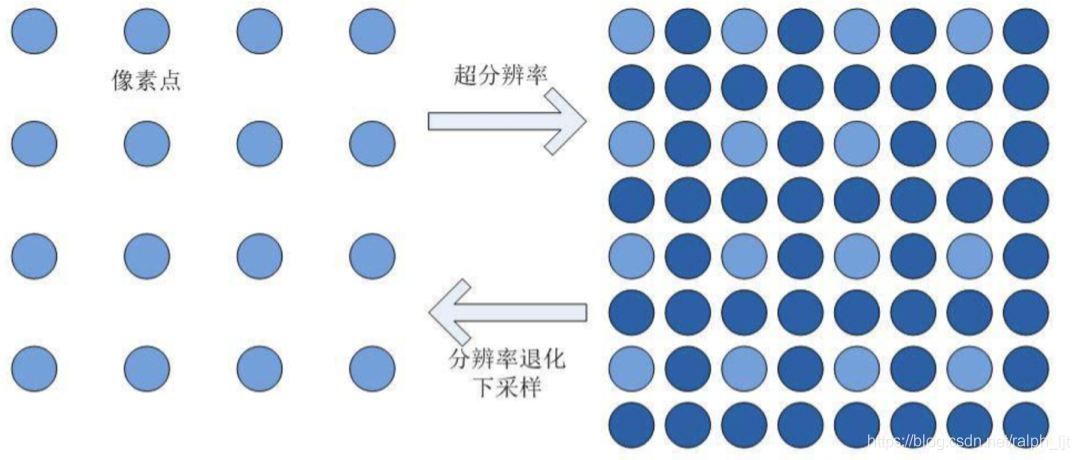
这项技术在现实世界中有广泛的应用,最常见的应用场景就是图片的压缩传输:为了在同等带宽下获得更高的图像质量,超分辨率算法适用于低带宽时低质量图像上的增强。除了提升图像感知的品质,也有助于提升其他计算机视觉任务,例如遥感领域、医学成像领域。传统的超分辨率方法有:基于预测的方法、基于边缘的方法、基于统计的方法、基于修补的方法、以及稀疏表示方法等。
近些年深度学习技术的快速发展,使得基于深度学习的超分辨率模型性能优异,大量深度学习方法被应用于解决超分辨率任务,早期的代表作有SRCNN和SRGAN,近期CVPR2020上也有不少相关的论文,例如:DRN和USRNet。总的来说,深度学习超分辨率算法之间各不相同,主要是由于下面几个主要的方向:不同类型的网络结构、不同类型的损失函数、不同类型的学习原则和策略等。
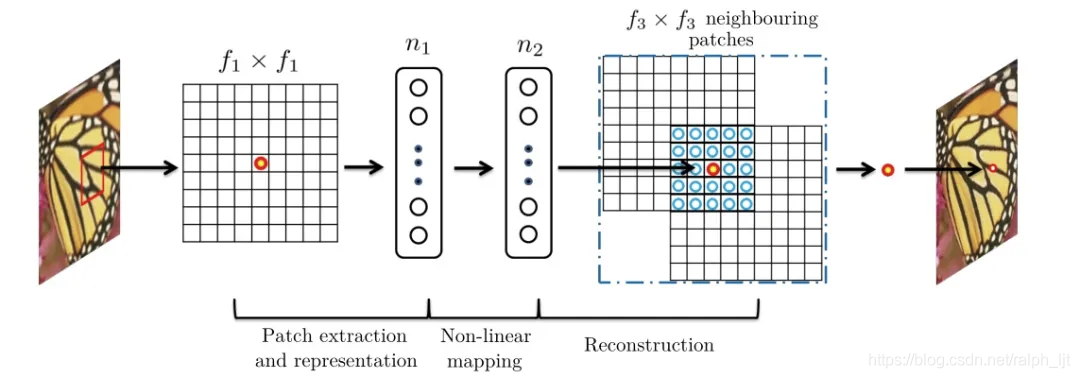
SRCNN:
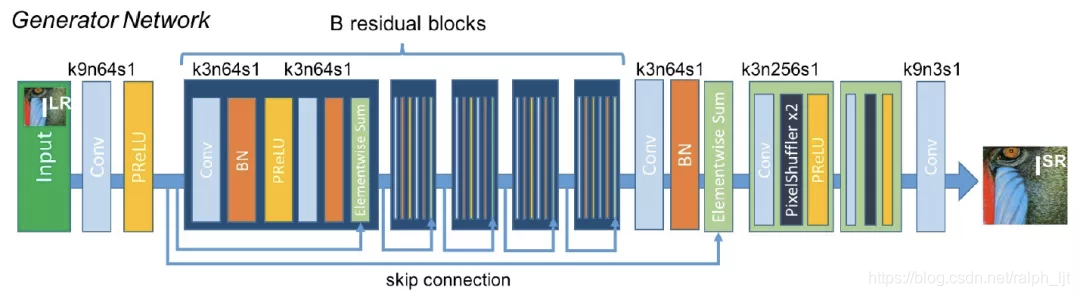
SRGAN:
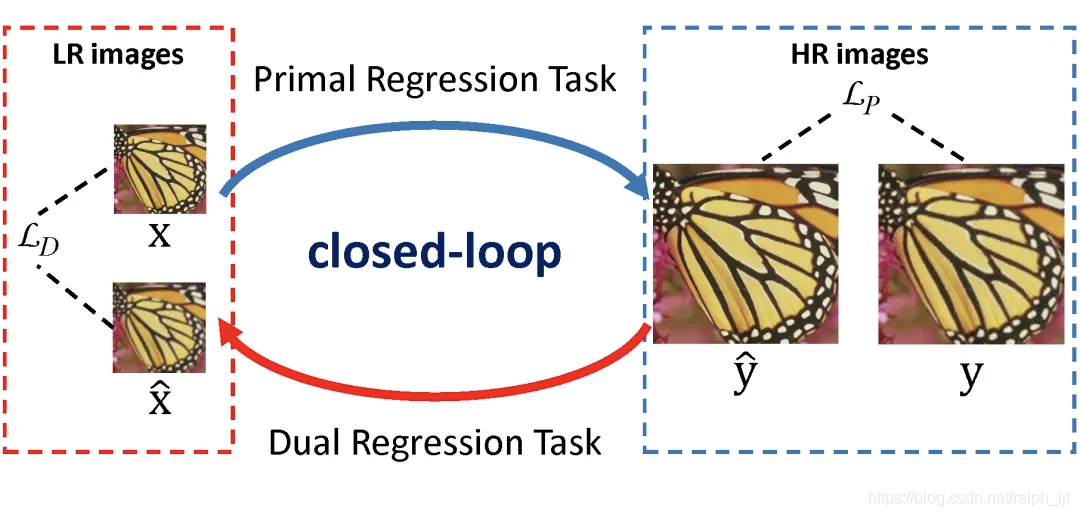
DRN:
USRNet:
3.项目背景
3.1摘要:
近年来,基于深度神经网络的单图像超分辨率重建模型在重建精度和计算性能方面都有了很大的进展。但是这些算法都太复杂了,效率很低。在本文中,我们提出了一种新的CNN架构,可以有效地降低计算的复杂度。在公开数据集上的评估结果表明,该方法的性能明显优于之前基于CNN的方法(图像为+0.15dB),并且比其他基于CNN的方法快了一个数量级。
3.2 网络结构:
与以往的工作不同,此项目在网络的末端才将分辨率从LR提高到HR,并从LR特征图中超分辨率地解析HR数据。这样就不需要在更大的HR分辨率下执行大部分超分辨率SR操作。为此,我们提出了一种有效的亚像素卷积层来学习图像和视频超分辨率的上尺度运算。这样做有两个优点:
每个LR图像被直接送入网络,通过LR空间中的非线性卷积进行特征提取。由于输入分辨率降低,我们可以有效地使用较小的过滤器大小来整合相同的信息,同时保持给定的上下文区域。分辨率和滤波器尺寸的减小,大大降低了计算量和内存的开销,但是足以实时实现超分辨率。
对于一个有图层的网络,我们学习了特征映射的上尺度过滤器,而不是输入图像的一个上尺度过滤器。此外,不使用显式插值滤波器意味着网络隐式地学习SR所需的处理。因此,与在第一层向上扩展单个固定滤波器相比,网络能够学习更好和更复杂的LR到HR映射,这使得模型重建精度的有额外提高。
3.3 基于Paddle的代码:
这里仅展示了部分关键代码,详细实现请参考AI Studio项目:
https://aistudio.baidu.com/aistudio/projectdetail/1109418
3.3.1 数据预处理
飞桨框架2.0 为我们封装好了Dataset类,我们定义数据读取器类时只需要继承自它并实现__getitem__返回读取的内容和__len__方法返回数据的样本数。这里,我们需要数据读取器返回一张缩小后的图片和一张没有缩放的图片,这两张图片都只有Ycbcr通道中的Y通道,因为大量的研究表表明人眼对亮度更敏感,所以我们这里只对亮度通道Y进行采样。
class BSD_data(Dataset):
def __init__(self,
mode='train',
image_path="data/data55873/images/"
):
super(BSD_data, self).__init__()
self.mode = mode.lower()
if self.mode == 'train':
self.image_path = os.path.join(image_path,'train')
elif self.mode == 'val':
self.image_path = os.path.join(image_path,'val')
else:
raise ValueError('mode must be "train" or "val"')
# 原始图像的缩放大小
self.crop_size = 300
# 缩放倍率
self.upscale_factor = 3
# 缩小后送入神经网络的大小
self.input_size = self.crop_size // self.upscale_factor
# numpy随机数种子
self.seed=1337
# 图片集合
self.temp_images = []
# 加载数据
self._parse_dataset()
def transforms(self, img):
"""
图像预处理工具,用于将升维(100, 100) => (100, 100,1),
并进行维度转换 H W C => C H W
"""
if len(img.shape) == 2:
img = np.expand_dims(img, axis=2)
return img.transpose((2, 0, 1))
def __getitem__(self, idx):
"""
返回 缩小3倍后的图片 和 原始图片
"""
# 加载原始图像
img = self._load_img(self.temp_images[idx])
# 将原始图像缩放到(3, 300, 300)
img = img.resize(
[self.crop_size,self.crop_size],
Image.BICUBIC
)
#转换为YCbCr图像
ycbcr = img.convert("YCbCr")
# 因为人眼对亮度敏感,所以只取Y通道
y, cb, cr = ycbcr.split()
y = np.asarray(y,dtype='float32')
y = y / 255.0
# 缩放后的图像和前面采取一样的操作
img_ = img.resize(
[self.input_size,self.input_size],
Image.BICUBIC
)
ycbcr_ = img_.convert("YCbCr")
y_, cb_, cr_ = ycbcr_.split()
y_ = np.asarray(y_,dtype='float32')
y_ = y_ / 255.0
# 升维并将HWC转换为CHW
img_s = self.transforms(y)
img_l = self.transforms(y_)
# img_s 为缩小3倍后的图片(1, 100, 100)
# img_l 是原始图片(1, 300, 300)
return img_s , img_l
def __len__(self):
"""
实现__len__方法,返回数据集总数目
"""
return len(self.temp_images)
def _sort_images(self, img_dir):
"""
对文件夹内的图像进行按照文件名排序
"""
files = []
for item in os.listdir(img_dir):
if item.split('.')[-1].lower() in ["jpg",'jpeg','png']:
files.append(os.path.join(img_dir, item))
return sorted(files)
def _parse_dataset(self):
"""
处理数据集
"""
self.temp_images = self._sort_images(self.image_path)
random.Random(self.seed).shuffle(self.temp_images)
def _load_img(self, path):
"""
从磁盘读取图片
"""
with open(path, 'rb') as f:
img = Image.open(io.BytesIO(f.read()))
img = img.convert('RGB')
return img
3.3.2 定义网络结构:
通过2.2节网络结构图,可以很容易的看出来:图片经过三层CNN采样后得到R的平方个特征通道,再通过Sub-Pixel层还原成channel个通道(这里是1通道)图像。
from paddle.nn import Layer, Conv2D
class Sub_Pixel_CNN(Layer):
def __init__(self, upscale_factor=3, channels=1):
super(Sub_Pixel_CNN, self).__init__()
self.conv1 = Conv2D(channels,64,5,stride=1, padding=2)
self.conv2 = Conv2D(64,32,3,stride=1, padding=1)
self.conv3 = Conv2D(32,channels * (upscale_factor ** 2),3,stride=1, padding=1)
def forward(self, x):
x = self.conv1(x)
x = self.conv2(x)
x = self.conv3(x)
x = paddle.fluid.layers.pixel_shuffle(x,3)
return x
模型封装及模型可视化
3.3.3 模型封装
model = paddle.Model(Sub_Pixel_CNN())
3.3.4 模型可视化
model.summary((1, 1, 100, 100))
3.3.5 模型训练准备
损失函数选用:
这里选择了常用的的均方差损失函数:MSELoss,其表达式如下图所示:
有兴趣的小伙伴可以尝试一下使用PSMR作为损失函数,可能效果会更好。
model.prepare(
paddle.optimizer.Adam(
learning_rate=0.001,
parameters=model.parameters()
),
paddle.nn.MSELoss()
)
3.3.6 模型训练:
# 启动模型训练,指定训练数据集、训练轮数、批次大小、日志格式
model.fit(train_dataset,
epochs=1,
batch_size=16,
verbose=1)
3.3.7 结果可视化
从我们的预测数据集中抽1个张图片来看看预测的效果,其中lowers是缩放的图片,prediction是lowers经过卷积超分辨率之后的结果。
psmr_low: 30.381882136539197 psmr_pre: 29.4920122281961
4 .思考与总结
这篇论文发表之前,CNN网络在超分辨率重建上就取得了非常好的效果,但是网络结构复杂,不适合在移动端部署。这篇论文使用了一个结构十分简单的网络结构,可以在视频上实现实时超分辨率,给轻量级的超分辨率算法提供了一个很好的思路。因为时间关系,本项目还没有实现对视频的实时处理。别急,下一个项目一定会有的!
最后,感谢飞桨和AI Studio深度学习开源平台提供的支持。本项目全程使用AI Studio完成开发,简直是穷学生党的福音啊,V100是真的香!
下载安装命令 ## CPU版本安装命令 pip install -f https://paddlepaddle.org.cn/pip/oschina/cpu paddlepaddle ## GPU版本安装命令 pip install -f https://paddlepaddle.org.cn/pip/oschina/gpu paddlepaddle-gpu
邮箱:(欢迎骚扰,一起探讨学习)
juntao.lu@connect.qut.edu.au
近期目标:拿到墨大AI方向研究生的offer(好像有点难度)
爱好倒腾,喜欢航模、航拍,梦想有朝一日实现财富自由,带着我的小飞机自驾拍遍全国。疫情原因暂时还在国内,欢迎南京的小伙伴找我面基。
如在使用过程中有问题,可加入飞桨官方QQ群进行交流:1108045677。
如果您想详细了解更多飞桨的相关内容,请参阅以下文档。
飞桨PaddlePaddle项目地址:
GitHub:
https://github.com/PaddlePaddle/PaddlePaddle
Gitee:
https://Gitee.com/PaddlePaddle/PaddlePaddle
飞桨官网地址:
https://www.paddlepaddle.org.cn/
本文分享 CSDN - Ralph Lu。
如有侵权,请联系 support@oschina.cn 删除。
本文参与“OSC源创计划”,欢迎正在阅读的你也加入,一起分享。
