对于我们而言,经常会遇到服务器服务出现异常的情况,一般情况下,我们可以通过查看应用日志解决。但是有些特殊情况就不适用了。
例如:服务器有段时间总是莫名挂掉了;应用访问变得特别慢;cpu占用突然变高又突然变低等等,这些就涉及到服务器管理相关操作。
最常见的异常:1.oom异常,服务器kill应用,我们通常可以通过查看/var/log/messages,全局搜索相关,查看是否这些原因造成的。
一般服务器问题排查的流程:
1.使用Top命令查看异常服务
- 可以查看各个服务的CPU内存占用情况
- 输入交互指令1,可以看到多核各个CPU的使用情况

-
输入交互指令H,查看线程使用情况
-
查看有没有进程CPU和内存占用多的
-
如果线程资源占用太多,说明可能存在线程性能问题,或者线程出现了死循环。
-
查找对应应用的PID进行相关分析,如果是Java项目的话,要根据项目具体分析。
-
转化一下线程nid(查询出来的是十进制的需要转成十六进制) ,可以通过线程id对线程进行查看*
-
printf "%x
" 19054
4a6e
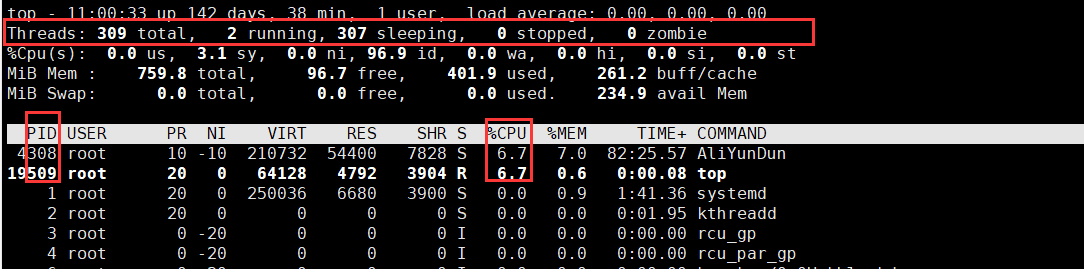
- 使用TOP -p pid命令,查看进程

2.分析JVM使用情况
使用jstat 查看虚拟机堆内存分区信息
最常使用的是:
jstat -gc pid
jstat -gcutil pid
这两个指令,查看虚拟机的堆内存信息,判断老生代是否已经满了,造成应用速度减慢。

jmap获取堆内存
- 指令格式
jmap 参数 pid
jmap 参数 executable core
jmap 参数 [server-id@]remote-hostname-or-IP
- 指令参数
-dump:[live],format=b,file=
-finalizerinfo 打印正等候回收的对象的信息
-heap 打印heap的概要信息,GC使用的算法,heap的配置及wise heap的使用情况.
-histo[:live] 打印每个class的实例数目,内存占用,类全名信息. VM的内部类名字开头会加上前缀”*”. 如果live子参数加上后,只统计活的对象数量.
-permstat 打印classload和jvm heap长久层的信息. 包含每个classloader的名字,活泼性,地址,父classloader和加载的class数量. 另外,内部String的数量和占用内存数也会打印出来.
-F 强迫.在pid没有响应的时候使用-dump或者-histo参数. 在这个模式下,live子参数无效.
-h | -help 打印辅助信息
-J
- 打印堆快照信息
jmap -dump:format=b,file=j.dmp 19053
jmap -heap 19053
常用指令jstack,定位线程具体信息
- 几种使用方法
jstack [-l] <pid>
(to connect to running process) 所有线程信息
jstack -F [-m] [-l] <pid>
(to connect to a hung process) 连接阻塞线程
jstack [-m] [-l] <executable> <core>
(to connect to a core file) 连接dump的文件
jstack [-m] [-l] [server_id@]<remote server IP or hostname>
(to connect to a remote debug server) 连接远程服务器
- 上面已经获取到了异常线程的nid,可以通过jstack查看对应线程的信息
jstack 19053|grep 4a6e -A 40
查找PID中nid对应信息的后20行数据,定位线程信息