参考:http://www.infoq.com/cn/news/2015/12/linux-performance
1. uptime
如果电脑运行缓慢,执行 uptime 可以大致查看Linux服务器的负载,执行w或者top命令也可以,在这三个命令都可以看到系统的当前负载
注:参考文章 - http://www.ruanyifeng.com/blog/2011/07/linux_load_average_explained.html
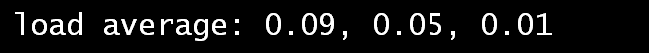
上述三个命令都会有如上的输出,该输出表示当前系统的1、5、15分钟内的平均负载。什么是系统负载?其实上述的参考文章说明了这个问题。
系统负载表示的是CPU的能力,系统的进程数。当CPU同时处理的进程越多,系统可以承受的最大负载比较大。
这个命令可以知道当前机器是否真的运行缓慢,但具体那个进程引起的,以及具体的原因(哪种资源,哪个进程)则需要另外的命令来确定。
2. dmesg | tail
下面的参考文章说,这个命令仅仅是打印环形缓冲区的内容,且这些内容也会实时输出到
syslogd或者klogd,在我的机器上是syslogd,这个进程最终会打印日志到/var/log/messages。
文章说dmesg最有用的地方就是在syslogd或者klogd启动前捕获开机的信息。所以我认为直接看/var/log/messages文件查看当前系统的日志,应该可以查看到有用的信息。
如果系统出现了问题(网络堵塞,CPU负载高,IO负载高等)应该会有所表现。注:参考文章 - http://unix.stackexchange.com/questions/35851/whats-the-difference-of-dmesg-output-and-var-log-messages
3. vmstat 1
每一行输出都会显示系统的核心指标,这些指标可以让我们更详细的了解系统状态。以下说明性能调优的相关参数,粗体字需要格外注意:
进程相关
- r: 进程运行队列的进程数,这个数据比uptime的输出更能体现CPU负载情况。如果这个数值已经大于机器CPU核数,那么机器的CPU资源已经饱和
- b: 等待IO的进程数,这个参数一般不需要关心
内存相关
- swpd: 使用虚拟内存大小
- free: 可用内存大小,如果可用内存不足,会导致性能问题
- buff: 用作缓冲的内存大小
- cache: 用作缓存的内存大小
交换区读写:如果以下俩个指标不为0,表明已经在使用swap交换区,机器的物理内存已经不足
- si: 每秒从交换区写到内存的大小
- so: 每秒写入交换区的内存大小
块IO读写,单位为1024KB
- bi: 每秒读取的块数
- bo: 每秒写入的块数
系统
- in: 每秒中断数,包括时钟中断。
- cs: 每秒上下文切换数。
CPU(以百分比表示)
- us: 用户进程执行时间(user time) 如果用户时间和系统时间加起来比较长,表示CPU忙于执行指令,CPU资源紧张。
- sy: 系统进程执行时间(system time)
- id: 空闲时间(包括IO等待时间)
- wa: 等待IO时间 如果等待IO时间比较长,那么说明磁盘IO为瓶颈
注:参考文章 - http://www.infoq.com/cn/news/2015/12/linux-performance
4. mpstat -P ALL 1
该命令可以显示每个CPU的占用情况,查看CPU资源
5. pidstat 1
该命令输出进程的cpu占用率,如果进程不占用CPU,不会在输出结果中显示,这个可以看到当前服务器中占用CPU比较高的进程
6. iostat -xz 1: -z 参数表示消除(不显示)那些不活跃的设备
cpu属性值说明:
%user:CPU处在用户模式下的时间百分比。
%nice:CPU处在带NICE值的用户模式下的时间百分比。
%system:CPU处在系统模式下的时间百分比。
%iowait:CPU等待输入输出完成时间的百分比。
%steal:管理程序维护另一个虚拟处理器时,虚拟CPU的无意识等待时间百分比。
%idle:CPU空闲时间百分比。
备注:如果%iowait的值过高,表示硬盘存在I/O瓶颈,%idle值高,表示CPU较空闲,如果%idle值高但系统响应慢时,有可能是CPU等待分配内存,此时应加大内存容量。%idle值如果持续低于10,那么系统的CPU处理能力相对较低,表明系统中最需要解决的资源是CPU。
disk属性值说明:
rrqm/s: 每秒进行 merge 的读操作数目。即 rmerge/s
wrqm/s: 每秒进行 merge 的写操作数目。即 wmerge/s
r/s: 每秒完成的读 I/O 设备次数。即 rio/s
w/s: 每秒完成的写 I/O 设备次数。即 wio/s
rsec/s: 每秒读扇区数。即 rsect/s
wsec/s: 每秒写扇区数。即 wsect/s
rkB/s: 每秒读K字节数。是 rsect/s 的一半,因为每扇区大小为512字节。
wkB/s: 每秒写K字节数。是 wsect/s 的一半。
avgrq-sz: 平均每次设备I/O操作的数据大小 (扇区)。
avgqu-sz: 平均I/O队列长度。向设备发出的请求平均数量。如果这个值大于1,可能是硬件设备已经饱和
await: 平均每次设备I/O操作的等待时间 (毫秒)。
svctm: 平均每次设备I/O操作的服务时间 (毫秒)。
%util: 一秒中有百分之多少的时间用于 I/O 操作,即被io消耗的cpu百分比。表示设备的繁忙程度,经验值是如果超过60,可能会影响IO性能,同时可以参照IO操作等待时间
备注:如果 %util 接近 100%,说明产生的I/O请求太多,I/O系统已经满负荷,该磁盘可能存在瓶颈。如果 svctm 比较接近 await,说明 I/O 几乎没有等待时间;如果 await 远大于 svctm,说明I/O 队列太长,io响应太慢,则需要进行必要优化。如果avgqu-sz比较大,也表示有当量io在等待。
7. free -m
free命令可以查看系统内存的使用情况,-m参数表示按照兆字节展示。
free命令输出解释:
第一行是表头。
第二行是从操作系统的角度计算机一共有多少内存(total),使用了多少(used),可用的还有多少(free),buffer(存放将要写入磁盘的缓存), cache(存放从磁盘读入的缓存)。
buffer和cache都是为了提高磁盘IO效率的,操作系统管理。
第三行是从应用的角度来看系统内存的使用情况
-buffers/cache,表示一个应用程序认为系统被用掉多少内存;
+buffers/cache,表示一个应用程序认为系统还有多少内存;
因为被系统cache和buffer占用的内存可以被快速回收,所以通常FO[3][3]比FO[2][3]会大很多。
这里还用两个等式:
- FO[3][2] = FO[2][2] - FO[2][5] - FO[2][6]
- FO[3][3] = FO[2][3] + FO[2][5] + FO[2][6]
可用内存的大小会影响性能
注:参考文章 - http://www.cnblogs.com/coldplayerest/archive/2010/02/20/1669949.html
8. sar -n DEV 1
http://lovesoo.org/linux-sar-command-detailed.html
http://linuxtools-rst.readthedocs.io/zh_CN/latest/tool/sar.html 注:此文章-n参数说明有误,还是应该man sar查看用途
怀疑CPU存在瓶颈,可用 sar -u 和 sar -q 等来查看
怀疑内存存在瓶颈,可用 sar -B、sar -r 和 sar -W 等来查看
怀疑I/O存在瓶颈,可用 sar -b、sar -u 和 sar -d 等来查看
sar -n [keyword, [keyword] | ALL]
keyword: DEV, EDEV, NFS, NFSD, SOCK, IP, EIP, ICMP, EICMP, TCP, ETCP, UDP, SOCK6, IP6, EIP6, ICMP6, EICMP6 and UDP6
这主要是查看网络设备的情况
例:sar -n DEV 1
查看网络设备的吞吐率,通过判断网络设备的吞吐量,判断网络设备是否已经饱和,如示例输出中eth0网卡设备(网卡设备吞吐率例如:1Gbit/sec)
9 sar -n TCP, ETCP 1
查看TCP的连接状态
active/s: 每秒本地发起的TCP连接数,即服务器通过connect调用创建的TCP连接数
passive/s: 每秒远程发起的TCP连接数,即服务器通过accept调用创建的连接数
retrans/s: 每秒重传数量
这几个参数可以用来判断性能问题是否由于创建了过多的连接,进一步判断原因是因为主动发起的连接过多还是没动发起的连接数过多。
TCP重传可能是由于网络环境的恶劣,或者服务器压力过大导致丢包。
10. top
top是比较全面的命令,可以查看系统负载,系统内存,系统CPU等情况。top支持排序,可以按照内存占用大小、CPU占用大小等排序。
详细情况请查看man
其他
pstak: 跟踪进程栈
strace: 跟踪进程系统调用
netstat: 查看网络状态