2018-03-0720:53:56
成功的效果如下

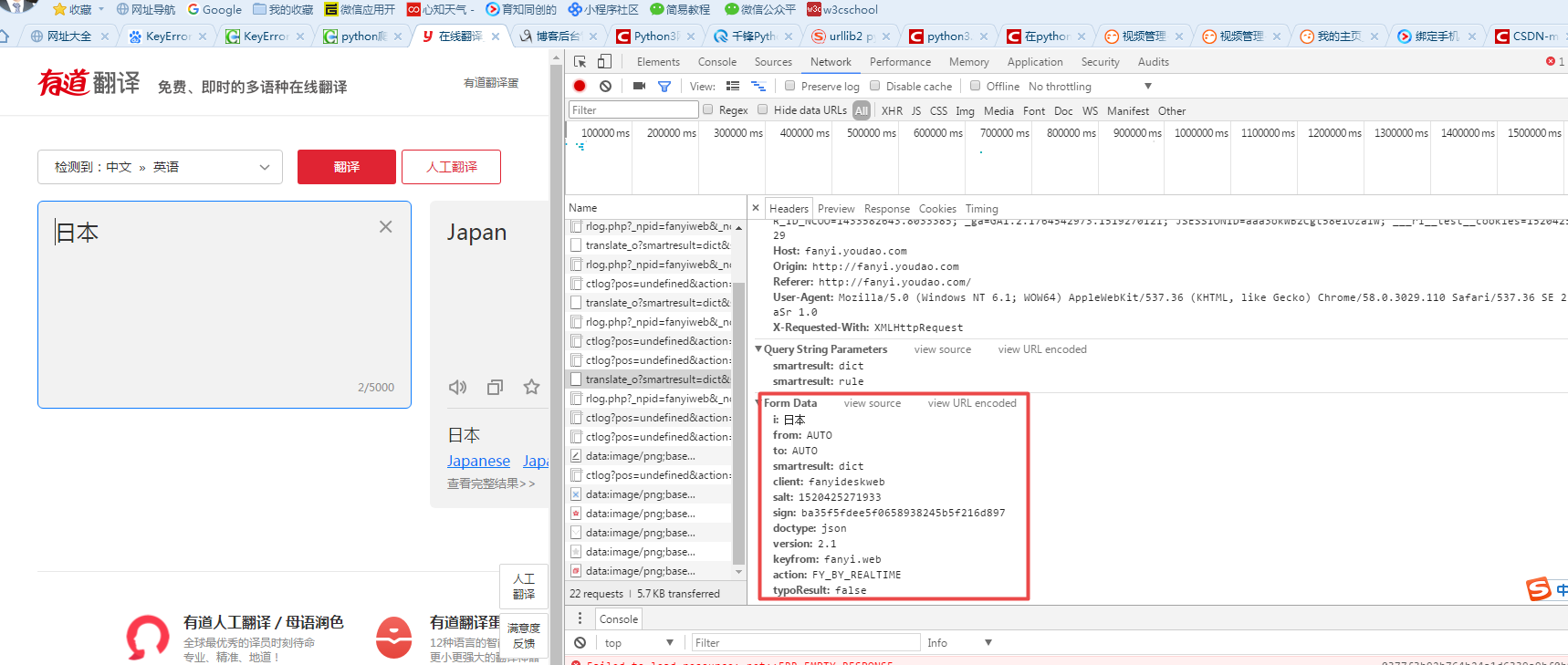
代码备份
# -*- coding: UTF-8 -*- from urllib import request from urllib import parse import json if __name__ == "__main__": #对应上图的Request URL Request_URL = 'http://fanyi.youdao.com/translate?smartresult=dict&smartresult=rule&smartresult=ugc' #创建Form_Data字典,存储上图的Form Data Form_Data = {} Form_Data['i'] = 'hello' Form_Data['from'] = 'AUTO' Form_Data['to'] = 'AUTO' Form_Data['smartresult'] = 'dict' Form_Data['client'] = 'fanyideskweb' Form_Data['salt'] = '1520425271933' Form_Data['sign'] = 'ba35f5fdee5f0658938245b5f216d897' Form_Data['doctype'] = "json" Form_Data['version'] = '2.1' Form_Data['keyfrom'] = 'fanyi.web' Form_Data['action'] = 'FY_BY_REALTIME' Form_Data['typoResult'] = 'false' #使用urlencode方法转换标准格式 data = parse.urlencode(Form_Data).encode('utf-8') #传递Request对象和转换完格式的数据 response = request.urlopen(Request_URL,data) print(response.getcode()) #读取信息并解码 html = response.read().decode('utf-8') #使用JSON translate_results = json.loads(html) #找到翻译结果 translate_results = translate_results["translateResult"][0][0]['tgt'] #打印翻译信息 print(html) print("翻译的结果是:%s" % translate_results)
效果还是可以的,毕竟这是自己的第一次调试。
代码更新
加入json数据解析的方法
# -*- coding: UTF-8 -*- from urllib import request from urllib import parse import json if __name__ == "__main__": #对应上图的Request URL Request_URL = 'http://fanyi.youdao.com/translate?smartresult=dict&smartresult=rule&smartresult=ugc' #创建Form_Data字典,存储上图的Form Data Form_Data = {} Form_Data['i'] = '我曾经有一个梦想' Form_Data['from'] = 'AUTO' Form_Data['to'] = 'AUTO' Form_Data['smartresult'] = 'dict' Form_Data['client'] = 'fanyideskweb' Form_Data['salt'] = '1520425271933' Form_Data['sign'] = 'ba35f5fdee5f0658938245b5f216d897' Form_Data['doctype'] = "json" Form_Data['version'] = '2.1' Form_Data['keyfrom'] = 'fanyi.web' Form_Data['action'] = 'FY_BY_REALTIME' Form_Data['typoResult'] = 'false' #使用urlencode方法转换标准格式 data = parse.urlencode(Form_Data).encode('utf-8') #传递Request对象和转换完格式的数据 response = request.urlopen(Request_URL,data) #读取信息并解码 html = response.read().decode('utf-8') #使用JSON translate_results = json.loads(html) print("输出json数据为: %s" % translate_results) # 找到可用的key print("可用的key为:%s" %translate_results.keys()) #找到翻译结果 test = translate_results["type"] your_input = translate_results["translateResult"][0][0]['src'] translate_results = translate_results["translateResult"][0][0]['tgt'] #打印翻译信息 print("测试输出 %s" %test) print("待翻译的内容为:%s" % your_input) print("翻译的结果是:%s" % translate_results)
输出结果为
C:UsersAdministratorPycharmProjectspython_test1venvScriptspython.exe C:/Users/Administrator/PycharmProjects/python_test1/123.py 输出json数据为: {'type': 'ZH_CN2EN', 'errorCode': 0, 'elapsedTime': 1, 'translateResult': [[{'src': '我曾经有一个梦想', 'tgt': 'I had a dream'}]]} 可用的key为:dict_keys(['type', 'errorCode', 'elapsedTime', 'translateResult']) 测试输出 ZH_CN2EN 待翻译的内容为:我曾经有一个梦想 翻译的结果是:I had a dream Process finished with exit code 0