一:cuda编程模型
1:主机与设备
主机---CPU 设备/处理器---GPU
CUDA编程模型如下:
GPU多层存储空间结构如图:
2:Kernel函数的定义与调用
A:运行在GPU上
相关限定符:__global__能在主机端和device端调用中调用;__device__只能在device端调用
__host__只能在host端调用 _host__device_:都可调用,单元测试是可只使用一份代码---应该编译了两份binary.
B:在调用时必须声明内核函数的执行参数----<<<>>>。
C:先为内核函数中用到的变量分配好足够空间再调用kernel函数
D:每个线程都有自己对应的id----由设备端的寄存器提供的内建变量保存,且是只读的。
E:CUDA C通过允许程序员定义称为内核的 C函数来扩展C,这些函数在被调用时由N个不同的CUDA线程并行执行N次,而不是像常规C函数那样仅执行一次。
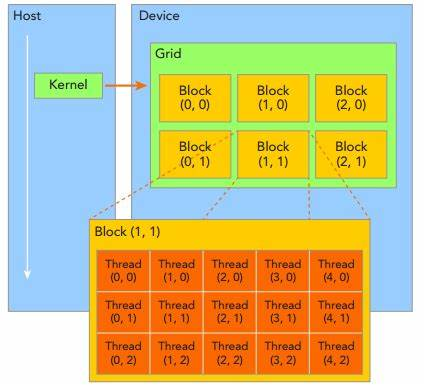
3:线程结构
1)线程标识
dim3类型(基于uint3定义的矢量类型----由三个unsigned int组成的结构体)的内建变量threadIdx和blockIdx。
2)一维block
线程threadID----threadIdx.x.
3)二维block---(Dx,Dy)
线程threadID----threadIdx.x+threadIdx.y*Dx;
4)三维block---(Dx,Dy,Dz)
线程threadID----threadIdx.x+threadIdx.y*Dx+threadIdx.z*Dx*Dy;
4:硬件映射
1)计算单元
SM---流多处理器 SP---流处理器
A:一个SM包含8个SP,共用一块共享存储器
2)warp
线程束在采用Tesla架构的gpu中:一个线程束由32个线程组成,且其线程只和threadID有关
A:warp才是真正的执行单位,当在一个warp内不需要__syncwarp.
3)执行模型
SIMT---单指令多线程 SIMD---单指令多数据
4)deviceQuery实例


1 #include <stalib.h> 2 #include <stdio.h> 3 #include<string.h> 4 #include <cutil.h> 5 6 int main() 7 { 8 int deviceCount; 9 CUDA_SAFE_CALL(cudaGetDeviceCount(&deviceCount)); 10 if(0 == deviceCount) 11 { 12 printf("no deice "); 13 } 14 int dev; 15 for(dev = 0;dev <deviceCount;dev++) 16 { 17 cudaDeviceProp deviceProp; 18 CUDA_SAFE_CALL(cudaGetDeviceProperties(&deviceProp,dev)); 19 print(); 20 } 21 }
5)cuda程序编写流程
A:主机端
1 启动CUDA,使用多卡时需加上设备号,或使用cudaSetDevice()设置 2 为输入数据分配空间 3 初始化输入数据 4 为GPU分配显存,用于存放输入数据 5 将内存中的输入数据拷贝到显存 6 为GPU分配显存,用于存放输出数据 7 调用device端的kernel进行计算,将结果写到显存中对应区域 8 为CPU分配内存,用于存放GPU传回来的输出数据 9 使用CPU对数据进行其他处理 10 释放内存和显存空间 11 退出CUDA
B:设备端
1 从显存读数据到GPU片内 2 对数据进行处理 3 将处理后的数据写回显存
(1)在显存全局内存分配线性空间--cudaMalloc()/cudaFree()
(2)拷贝存储器中的数据 --cudaMemcpy()
拷贝操作类型:cudaMemcpyDeiceToHost cudaMemcpyHostToDevice cudaMemcpyDeviceToDevice
(3)网格定义
<<<Dg,Db,Ns,S>>>
Dg----grid纬度与尺寸 Db---block维度与尺寸 Ns--可分配动态共享内存大小 s--stream_t类型的可选参数
(4)设备端内建变量
gridDim blockIdx blockDim threadIdx warpSize
6)内核实例
A:与shared memory有关-----shared memory 与opencl local memory 类似,只对device可见,hardwork只知道shared 大小且都认为从0开始编号
1 __global__ void 2 testKernel(float* g_idata,float* g_odata) 3 {
//分配共享内存 将全局内存的数据写入共享内存 进行计算,将结果写入共享内存 将结果写回全局内存 4 extern __shared__ float sdata[];//动态分配共享内存空间--__device__ __global__函数中
//动态分配大小是执行参数中的第三个参数。当静态分配时必须指明大小 5 6 const unsigned int bid = blockIdx.x; 7 const unsigned int tid_in_block = threadIdx.x; 8 const unsigned int tid_in_grid = blockIdx.x*blockDim.x+threadIdx.x; 9 sdata[tid_in_block] = g_idata[tid_in_grid]; 10 __syncthreads(); 11 12 sdata[tid_in_block] *= (float)bid; 13 14 __syncthreads();
g_odata[tid_in_grid] = sdata[tid_in_block]; 15 }
B:静态共享内存与二维网格
1 __gloabal__ void 2 testKernel(float* g_idata,int width,int height ) 3 { 4 __shared__ float sdata[4]; 5 6 //__mul24()-----cuda中两数相乘函数 7 //block在网格中的索引-----如同元素在二维数组中的下标 8 //blockIdx.x----线程所在块索引号 9 unsigned int bid_in_grid = __mul24(blockIdx.y,griDim.x)+blockIdx.x; 10 11 //线程在线程快中的索引---与上一个类似,但嵌套在网格中 12 //threadIdx.x---线程在块中的索引号 13 unsigned int tid_in_block = __mul24(threadIdx.y,blockDim.x)+threadIdx.x; 14 unsigned int tid_in_grid_x = __mul24(blockDim.x,blockIdx.x)+threadIdx.x; 15 unsigned int tid_in_grid_y = __mul24(blockDim.y,blockIdx.y)+threadIdx.y; 16 unsigned int tid_in_grid = __mul24(tid_in_grid_y,width)+tid_in_grid_x; 17 18 SDATA(tid_in_block) = (float)bid_in_grid*SDATA(tid_in_block); 19 __syncthreads(); 20 21 g_odata[tid__in_grid] = SDATA(tid_in_block); 22 __syncthreads(); 23 }
二:CUDA软件体系
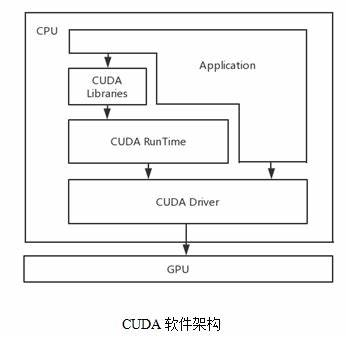
1:CUDA C语言---我不熟悉的
A:blockIdx threadIdx-----索引线程块和线程 gridDim blockDim---描述线程网格和线程块的维度
warpSize----warp中的线程数量
B:初始化
在初始化过程中,运行时创建系统中的每个设备。此上下文是此设备的主要上下文,并且在应用程序的所有主机线程之间共享。作为此上下文创建的一部分,设备代码会在必要时进行实时编译,并加载到设备内存中。这一切都是在后台进行的,并且运行时不会向应用程序公开主要上下文。当主机线程调用 cudaDeviceReset(),这将破坏主机线程当前在其上操作的设备的主要上下文。具有该设备作为当前设备的任何主机线程进行的下一个运行时函数调用都将为此设备创建一个新的主上下文。
2:CUDA驱动API
A:调用任何一个驱动API函数之前,必须先调用cuInit()完成初始化,创建一个CUDA上下文。
B:上下文
封装驱动程序API中执行的 所有资源和操作------管理相关资源,当上下文被销毁时,系统自动清理这些资源。
一个主机端线程在一个时刻只能拥有一个当前设备上下文。
cuCtxCreate()创建上下文;cuCtxPopCurrent()---解除或恢复主机端线程与上下文关系
cuCtxAttach()---上下文使用计数递增 cuCtxDetach()--使用计数递减
cuCtxDetach()/cuCtxDestroy()---使用数为0是上下文被销毁
计数目的-----实现在同一上下文中与第三方代码进行互操作。当有库使用时上下文计数加1,使用完后计数减1。特殊情况---库单独使用一个上下文:库初始化调用-cuCtxCreate()-初始化上下文--cuCtxPopCurrent()将该库上下文压入。库调用---cuCtxPushCurrent()---使用上下文--cuCtxPopCurrent()释放上下文。
C:Kernel执行
cuFuncSetBlockShape()----为给定函数设置每个块的线程数以及块中threadID的设置方式
cuFuncSetSharedSize()----为函数设置每个block中共享存储器的大小
实现矢量加法
1 int main() 2 {
//初始化设备 3 if(cuInit() != CUDA_SUCCESS) 4 exit(0); 5
//获得支持设备的数目 6 int deiceCount = 0; 7 cuDeviceGetCount(&deviceCount); 8 if(0 == deviceCount) 9 exit(0); 10
//获得设备0的句柄 11 CUdevice cuDevice = 0; 12 cuDeviceGet(&cuDevice,0); 13
//创建上下文 14 CUcontext cuContext; 15 cuCtxCreate(&cuContex,0,cuDevice); 16
//从二进制文件生成模板 17 CUmodule cuModule; 18 cuModuleLoad(&cuModule,"VecAdd.cubin");
//从模板取得函数句柄
CUfunction vecAdd;
cuModuleGetFunction(&vecAdd,cuModule,"VecAdd");
//启动Kernel 19 //cuParam*()函数用于指定调用cuLaunchGrid()/cuLaunch()调用启动内核时为内核提供的参数 20 int threadsPerBlock = 256; 21 int threadsPerGrid = (N+threadsPerBlock-1)/threadsPerBlock; 22 int offset = 0; 23 cuParamSeti(vecAdd.offset.A);offset += sizeof(A); 24 cuParamSeti(vecAdd.offset.B);offset += sizeof(B); 25 cuParamSeti(vecAdd.offset.C);offset += sizeof(C); 26 cuParamSetSize(vecAdd.offset); 27 cuFuncSetBlockShape(vecAdd,threadsPerBlock,1,1); 28 cuLaunchGrid(vecAdd,threadsPerGrid,1); 29 }
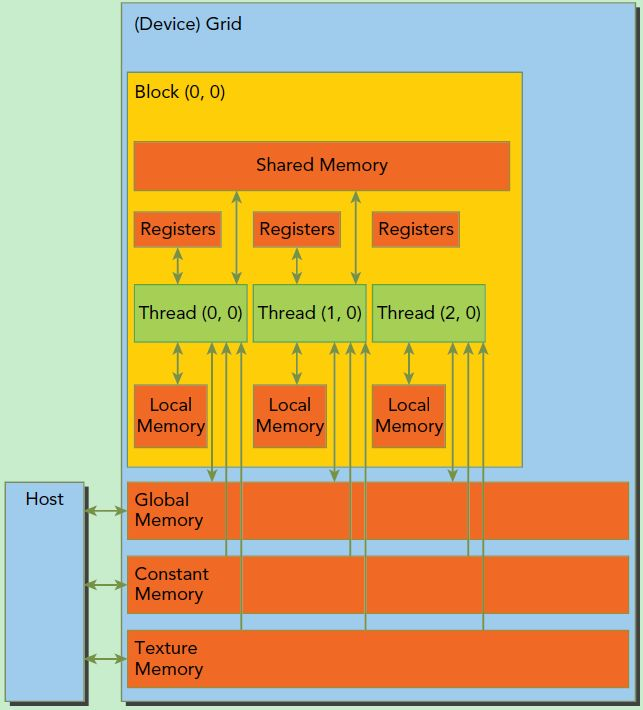
三:CUDA存储器模型
相关图片在随笔开头已经给出;
| 存储器 | 位置 | 拥有缓存 | 访问权限 | 变量生存周期 |
| register | GPU片内 | N/A | device可读/写 | 与thread相同 |
| local memory | 板载显存 | 无 | device可读/写 | 与thread相同 |
| shared memory | GPU片内 | N/A | device可读/写 | 与block相同 |
| constant memory | 板载显存 | 有 | device可读,host可读/写 | 可在程序中保持 |
| global memory | 板载显存 | 无 | device可读/写,host可读/写 | 可在程序中保持 |
| texture memory | 板载显存 | 有 | device可读,可读/ | 可在程序中保持 |
| host memory | host内存 | 无 | host可读/写 | 可在程序中保持 |
| pinned memory | host内存 | 无 | host可读/写 | 可在程序中保持 |
1:设备端内存
A:寄存器内存
每个寄存器文件大小为32bits,当私有变量不大时,将其分配为寄存器变量,否则为局部变量--访问速度慢
B:常数存储器
空间较小(64kb)
用于存放需要频繁访问的只读参数
在所有函数外声明定义
C;全局内存
runtime API 使用global memory
1 __constant__ float constData[256]; 2 float data[256]; 3 cudaMemcpyToSymbol(constData,data,sizeof(data)); 4 cudaMemcpyFromSymbol(data,constData,sizeof(data)); 5 6 __device__ float devData; 7 float value = 3.14; 8 cudaMemcpyToSymbol(devData,&value,sizeof(float)); 9 10 __device__ float* devPointer; 11 float* ptr; 12 cudaMalloc(&ptr,256*sizeof(float)); 13 cudaMemcpyToSymbol(devPointer,&ptr,256*sizeof(ptr)); 14 15 //cudaGetSymbolAddress()用于检索指向为全局内存空间中声明的变量分配的内存的地址。分配的内存大小通过以下方式获得 cudaGetSymbolSize()。
D:实例
1)运行时API完成数据计算
线性内存通常使用 cudaMalloc() 并使用释放 cudaFree() 主机内存和设备内存之间的数据传输通常使用 cudaMemcpy()
1 __global__ void VecAdd(float* A,float* B,float* C) 2 { 3 int i = threadIdx.x; 4 if(i<N) 5 C[i] = A[i]+B[i]; 6 } 7 8 int main() 9 { 10 //显存中分配向量空间 11 size_t size = N*sizeof(float); 12 float* d_A; 13 cudaMalloc((void**)&d_A,size); 14 float* d_B; 15 cudaMalloc((void**)&d_B,size); 16 flaot* d_C; 17 cudaMalloc((void**)&d_C,size); 18 19 //从内存向显存拷贝向量 20 cudaMemcoy(d_A,h_A,size,cudaMemcpyHostToDevice); 21 cudaMemcpy(d_B,h_B,size,cudaMemcpyHostToDevice); 22 23 //启动kernel 24 int threadsPerBlock = 256; 25 int threadsPerGrid = (N+threadsPerBlock-1)/threadsPerBlock; 26 VecAdd<<<threadsPerGrid,threadsPerBlock>>>(d_A,d_B,d_C); 27 28 //从显存向内存考回结果 29 cudaMemcpy(h_C,d_C,size,cudaMemcpyDeviceToHost); 30 31 //释放缓存空间 32 cudaFree(d_A); 33 cudaFree(d_B); 34 cudaFree(d_C); 35 }
对于二三维数组使用cudaMallocPitch() cudaMalloc3D()分配线性存储空间,cudaMemcpy2D() cudaMemcpy3D()进行拷贝。
2)驱动API完成数据运算
1 int main() 2 { 3 //初始化设备 4 if(cuInit(0) != CUDA_SUCCESS) 5 exit(0); 6 7 //获得支持cuda的设备数目 8 int deviceCount = 0; 9 cuDeviceGetCount(&deviceCount); 10 if(deviceCount == 0) 11 exit(0); 12 13 //获得设备0句柄 14 CUdevice cuDevice = 0; 15 cuDeviceGet(&cuDevice,0); 16 17 //创建上下文 18 CUcontext cuContext; 19 cuCtxCreate(&cuContext,0,cuDevice); 20 21 //从二进制文件创建模块 22 23 CUmoudle cuMoudle; 24 cuMoudleLoad(&cuMoudle,"VecAdd.cubin"); 25 26 //从模块获得函数句柄 27 CUfunction VecAdd; 28 cuModuleGetFunction(&VecAdd,cuModule,"VecAdd"); 29 30 //显存中分配向量空间 31 size_t ize = N*sizeof(float); 32 CUdeviceptr d_A; 33 cuMalloc(&d_A,size); 34 CUdeviceptr d_B; 35 cuMalloc(&d_B,size); 36 CUdeviceptr d_C; 37 cuMalloc(&d_C,size); 38 39 //从内存向显存拷贝向量 40 cuMemcpyHtoD(d_A,h_A,size); 41 cuMemcpyHtoD(d_B,h_B,size); 42 43 // 启动kernel 44 int threadsPerBlock = 256; 45 int threadsPerGrid = (N+threadsPerBlock-1)/threadsPerBlock; 46 int offset = 0; 47 cuParamSeti(VecAdd,offset,d_A);offset += sizeof(A); 48 cuParamSeti(VecAdd,offset,d_B);offset += sizeof(B); 49 cuParamSeti(VecAdd,offset,d_C);offset += sizeof(C); 50 cuParamSetSize(VecAdd,offset); 51 cuLaunchGrid(VecAdd,threadsPerGrid,1); 52 53 //从显存向内存拷回结果 54 cuMemcpyDtoH(h_C,d_C,size); 55 56 //释放显存空间 57 cuMemFree(d_A); 58 cuMemFree(d_B); 59 CUMemFree(d_C); 60 61 }
2:主机端内存
可分页内存--通过操作系统API分配的存储器空间
页锁定内存--保证存在于物理内存中,不被分配到虚拟内存中
1)页锁定内存
A:运行时API实现
cudaHostAlloc() cudaFreeHost()分配释放pinned memory
<1>portable memory
cudaHostAllocPortable:可以让控制不同GPU的几个CPU线程共享同一块pinned memory,减少CPU线程间的数据传输和通信,页锁定内存默认为此标志
<2>write-combined Memory
cudaostAllocWriteCombined:减少缓存机制-对内存的监视,在总线传输期间不会被来自CPU的监听打断。由于没有缓存机制,CPU在读数据时速度有所降低,最好只将从CPU端只写的数据存放在此类内存。cache---当多个使用一个地址空间数据时,会多次刷新,导致浪费内存(当写入一定量的数据一次性刷新到内存,而写内存不用cache可直接写入memory)。
<3>mapped memory
cudaHostAllocMapped:两个地址:主机端地址 设备端地址
可以在内核程序中直接访问此类内存中的数据:zero-copy 经常用于量少数据
cudaHostAlloc()分配 cudaHostGetDevicePointer()获取设备端指针
cudaGetDeviceProperties()返回的cuMapHostMemory属性查看是否支持此类内存
必须通过同步保证CPU和GPU对同一块存储器操作的顺序一致性--流与事件等
当多个主机端线程操作一块pinned 内存时,每个线程必须获取设备端指针
必须调用cudaSetDeviceFlags()--cudaDeviceMapHost标志,再获取设备端指针
四:compiling ----暂时用不着
1:offline compilation
2:just in time compliation