测试环境需要新建个秒杀页面,正常来说1.在nginx.conf新建个server{},2.根据server{}里的制定路径的目录把秒杀的内容放进目录,3.域名解析(二级域名)
问题:以上配置都配置了之后,发现无法正常访问,都跳到一个默认首页
原因:本机存在两个nginx


我以为是默认的 /usr/local/nginx/conf/nginx.conf 所以怎么配置,依然无法访问
后面发现 /opt/nginx/conf/nginx.conf 才是实际的nginx


注意:1.留意本机是否只有唯一个nginx
2.重wind解压文件后在上传到linxu目录会出现乱码,所以更新的时候必须要在linux环境下解压

3.留意 nginx: master process ./nginx 主要这个就是主进程号
原因:
502 GAT away
Php-cgi进程挂掉或者是没有cgi进程
504 timeout
Nginx请求不到php-cgi进程,超时
解决方法:
思路:
502错误和php-fpm.conf配置文件有关系,网上很多教程都说了,一般就设置以下几个选项
这个数字只是一个参考,具体多少需要自己去琢磨

504错误和nginx.conf配置文件有很大的关系,网上教程就是说修改缓存的时间,大小等等,其实不然,除了上面的要修改,还有一个关键就是fastcgi_read_timeout这个选项,此选项的意思是设置在那个时间段内,不管php-cgi请求是否完成,都要关闭,大概意思就是这样,还有一点就是一定要注意,你的web站点的Php最大请求的时间大概为多少,如果设置少了,那么肯定报504,下面是我的配置

由于我内部Php那面需要网上采集数据,时间设置少了就会报502或者504……..就是这个原因
故障简述
中午在线优化一个敏感服务的Nginx配置时,发现5分钟内Nginx errorlog里出现了大量400错误,于是迅速回滚了Nginx配置。
原来的Nginx配置存在重复或者需废弃的内容,于是在多次diff了新旧两份配置内容后,小明认为最新配置是不影响业务的,因此在线推送更新配置后,直接reload了Nginx,出于double check原则,在线观察了5分钟Nginx日志:
/etc/init.d/Nginx reload
tail -f /var/log/access.log
tail -f /var/log/error.log
发现出现大量类似下面的400错误:
1.1.1.1 - - [21/Feb/2017:13:53:00 +0800] "GET /x/get?id=hh2&aid=11642618¤ttime=1487656379&num=21461799&flag=1&host=23000&user=60%2E220%2E132%2E66&logintime=1487654812&username=howru%2D10 HTTP/1.1" 400 166 "-" "-" "223.252.221.10" "0.000" "-" "-"
400错误的产生,很可能影响服务端或客户端的后续业务逻辑判断,因此需要引起重视。
处理过程
当时回滚配置后,先在搜索引擎查找了Nginx 400错误的可能原因和解决办法,初步确定有下面两种可能:1是空主机头,2是请求包头过大
为了方便后续排查,小明参考线上环境临时搭建了一套Nginx测试环境,重现了故障:
了解到原来客户端不是从代码的http库调用, 而是按照上面的方式走TCP/telnet传递http参数来调用服务端http接口。但是为什么一样的客户端请求方式,旧配置完全ok,新配置则会出现大量400错误?
怀疑自己没有完全diff出新旧两份配置的差别,于是他使用vimdiff再次对比新旧两份配置。
本次排查中,小明考虑的重点是新配置里遗漏了某些配置,于是他把location ~ (.*)的相关逻辑加上,发现问题依旧:
既然前面往缺失配置的思路走不通,下面就按照新增配置的思路排查,结果发现新配置增加了一些包头信息,小明怀疑是请求包过大,于是优先排查了Nginx针对包头大小的设置,其中有这么几个配置:
-
client_header_buffer_size:默认是1k,所以header小于1k的话是不会出现问题的。
-
large_client_header_buffers:该命令用于设置客户端请求的Header头缓冲区的大小,默认值为4KB。
客户端请求行不能超过large_client_header_buffers指令设置的值,客户端请求的Header头信息不能大于large_client_header_buffers指令设置的缓冲区大小,否则会报“Request URL too large”(414)或者“Bad-request”(400)错误,如果客户端Cookie信息较大,则须增加缓冲区大小。于是小明将client_header_buffer_size和large_client_header_buffers都设置为128k。结果问题也重现了。
原因分析
A client MUST include a Host header field in all HTTP/1.1 request messages . If the requested URI does not include an Internet host name for the service being requested, then the Host header field MUST be given with an empty value. An HTTP/1.1 proxy MUST ensure that any request message it forwards does contain an appropriate Host header field that identifies the service being requested by the proxy. All Internet-based HTTP/1.1 servers MUST respond with a 400 (Bad Request) status code to any HTTP/1.1 request message which lacks a Host header field.
上面是http1.1的rfc关于host部分的解释,从上面我们了解到如果一个http1.1的请求没有host域,那么server应该给client段发送400的状态码,表明这个请求server不能处理。而对于Nginx server来说,也遵循这样的方式,说明client发送了一个无效的请求,Nginx server无法处理,于是返回了400的状态码。
$host
This variable is equal to line Host in the header of request or name of the server processing the request if the Host header is not available.
This variable may have a different value from $http_host in such cases: 1) when the Host input header is absent or has an empty value, $host equals to the value of server_name directive; 2)when the value of Host contains port number, $host doesn't include that port number. $host's value is always lowercase since 0.8.17.
本次故障中,客户端的调用方式没有使用host 参数,传递了空的Host头给服务端,一旦Nginx设置了proxy_set_header Host $http_host,空Host头就传给了后端。然而,在http 1.1的规范中,Host只要出现空,就会返回400,所以出现了这个故障。而对于需要在Host字段里带上端口信息的,则仍需要配置proxy_set_header Host $http_host。
最后,需要注意的是,400错误不一样会影响业务,需要看具体的业务处理逻辑,比如使用nagios的check_tcp插件对Nginx server端口做检测或者使用keepalived的tcp_check功能对后端Nginx端口的存活做检测,这两种情况都会在Nginx errorlog中产生400的请求。
原因也很简单,就是一般tcp check的方式,就是建立tcp连接,但是没有发送任何数据,当然也没有Host头,然后再reset或者四次挥手断开连接
技术学习方法
本次故障的产生,很大程度上就是运维同学不理解Nginx变量的定义和区别,直接从搜索引擎上找了些配置,检查觉得正确就推到了线上。这里仍需要重申的是,以官方文档为准!互联网上很多知识或者配置有各种各样的问题,随时都有暗坑在里边,只有啃过官方文档才能避免误读。
Web日志分析
针对这里的Nginx错误日志查看,我们看到小明是用在线命令查看的,其实现在有很多web日志分析工具或系统,比如ELK(ElacticSearch+LogStash+Kibana),只需要配置好grok正则,是可以通过可视化界面实时监控web服务质量的。
-
403错误
403是很常见的错误代码,一般就是未授权被禁止访问的意思。
可能的原因有两种:
-
Nginx程序用户无权限访问web目录文件
-
Nginx需要访问目录,但是autoindex选项被关闭
修复方法:
-
授予Nginx程序用户权限读取web目录文件
-
设置autoindex目录为on
location /path/to/website/folder {
...
autoindex on;
... }
-
413错误
在上传时Nginx返回了413错误:“413 Request Entity Too Large”,这一般就是上传文件大小超过Nginx配置引起。
修复方法:
-
在Nginx.conf增加client_max_body_size的设置,这个值默认是1M,可以增加到8M以提高文件大小限制;
-
如果运行的是php,那么还要检查php.ini,这个大小client_max_body_size要和php.ini中的如下值的最大值一致或者稍大,这样就不会因为提交数据大小不一致出现的错误。
post_max_size = 8M
upload_max_filesize = 2M
-
502错误
Nginx 502 Bad Gateway的含义是请求的PHP-CGI已经执行,但是由于某种原因(一般是读取资源的问题)没有执行完毕而导致PHP-CGI进程终止。一般来说Nginx 502 Bad Gateway和php-fpm.conf的设置有关。
修复方法:
1、查看FastCGI进程是否已经启动
ps -aux | grep php-cgi
2、检查系统Fastcgi进程运行情况
除了第一种情况,fastcgi进程数不够用、php执行时间长、或者是php-cgi进程死掉也可能造成Nginx的502错误。
运行以下命令判断是否接近FastCGI进程,如果fastcgi进程数接近配置文件中设置的数值,表明worker进程数设置太少。
netstat -anpo | grep "php-cgi" | wc -l
3、FastCGI执行时间过长
根据实际情况调高以下参数值
fastcgi_connect_timeout 300;
fastcgi_send_timeout 300;
fastcgi_read_timeout 300;
-
504错误
Nginx 504 Gateway Time-out的含义是所请求的网关没有请求到,简单来说就是没有请求到可以执行的PHP-CGI。
Nginx 504 Gateway Time-out一般与Nginx.conf的设置有关。
头部太大这种情况可能是由于Nginx默认的fastcgi进程响应的缓冲区太小造成的, 这将导致fastcgi进程被挂起,如果你的fastcgi服务对这个挂起处理的不好,那么最后就极有可能导致504 Gateway Time-out。
默认的fastcgi进程响应的缓冲区是8K,可以调大以下参数:
-
fastcgi_buffer_size 128k;
fastcgi_buffers 8 128k;
-
fastcgi_busy_buffers_size 由 128K 改为 256K;
fastcgi_temp_file_write_size 由 128K 改为 256K。
此外,也可能是php-cgi的问题,需要修改php.ini的配置:
-
将max_children由之前的10改为30,这样操作是为了保证有充足的php-cgi进程可以被使用。
-
将request_terminate_timeout由之前的0秒改成60秒,这样使php-cgi进程处理脚本的超时时间提高到60秒,可以防止进程被挂起以提高利用效率。
nginx缓存权限问题
故障说明:
官网放了一段flv的视频,之前还可以播放,今天突然发现播放不了了。程序都一样,测试环境没问题,线上却播放不了。
下面说下产生问题的原因和解决办法。
-
nginx打开网页,点击视频播放,打不来,首先从nginx的error log下手,看下能否找出一些蛛丝马迹。
2015/04/09 18:33:20 [crit] 8063#0: *15970093 open() "/data/nginx/proxy_temp/7/41/0000006417" failed (13: Permission denied) while reading upstream, (nginx部分error日志)
通过查询nginx的eror日志,表面上是打不来缓存目录,没法缓存数据,google搜索了下,找到了答案。
nginx原本运行的账户是root,后来基于安全考虑,我修改成了你nginx,但是缓存目录的属主和属组还是root,所以视频的缓存数据写不到缓存目录。
2.找到了原因,下面说下解决方法:查看下,运行nginx的用户。
ps -ef | grep nginx
root 4850 1 0 Jan22 ? 00:00:00 nginx: master process /data/nginx/sbin/nginx
nginx 8862 4850 0 Apr14 ? 00:00:34 nginx: worker process
root 20476 20395 0 10:49 pts/1 00:00:00 grep nginx
3.可以看到运行nginx服务的用户是nginx用户,修改缓存目录的属主和属组为nginx。
chown -R nginx.nginx proxy_temp
ls -ld proxy_temp
drwx------ 12 nginx nginx 4096 Jan 8 18:02 proxy_temp
或者是把proxy_temp删除,就可以了
nginx 加tomcat负载在业务高峰期出现问题
nginx 反向代理Tomcat 高峰时报 connect() failed (110: Connection timed out) while connecting to upstream,
平峰一切OK 反应很快, 一到高峰期就很多connect() failed (110: Connection timed out) while connecting to upstream,
导致后端tomcat卡死 ,一开始以为是tomcat内存设置不够 gc的问题,后来更改过了还是不行 不能解决问题! 然后就奇葩的是 我直接干掉nginx 直接采用一个tomcat处理业务在高峰期居然可以抗的下来 但是加上nginx+tomcat的模式就会报错在高峰期
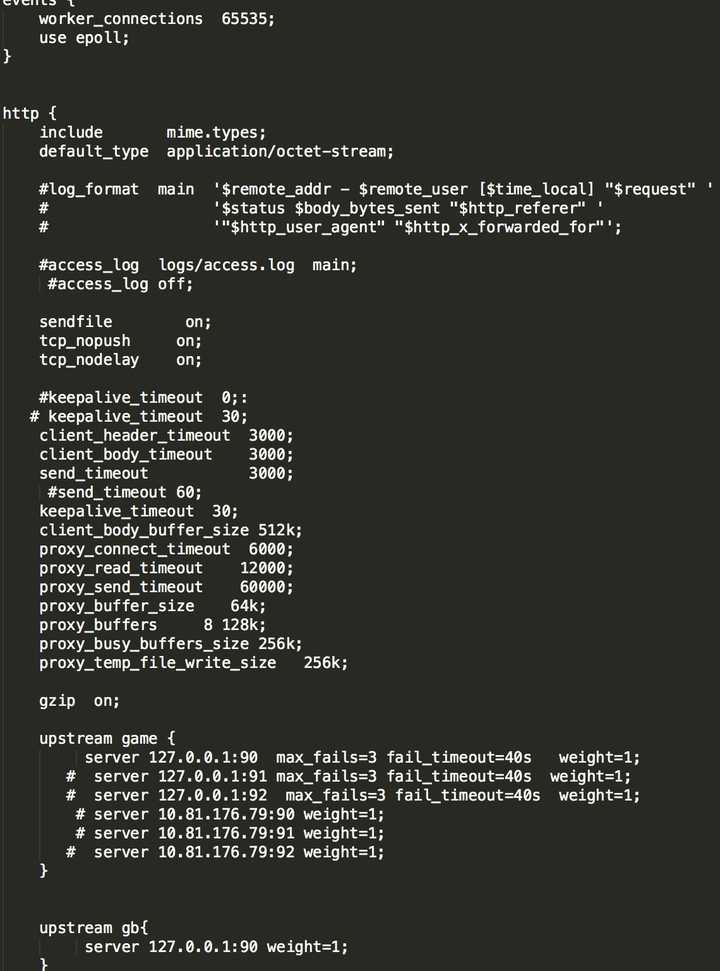
解决:
nginx配置中,"proxy_connect_timeout 6000"代表nginx与后端(即upstream)建连的超时时间为6秒。即是说,当nginx尝试与tomcat建连时间超过6秒后就会放弃并报错。高峰期时,如果nginx与tomcat建连频繁超时,就会出现你描述的情况。
你所谓的"tomcat卡死",我估计应该是tomcat在应对高峰流量时展现出的请求严重积压状态,此时tomcat还在工作,只不过排队的请求太多,响应非常非常慢。
至于为啥拿掉nginx之后就"没问题"了,是因为拿掉nginx之后就是用户直接与tomcat建连,此时请求处理效率并没有提高(如果按照6秒超时来计算的话,建连失败和先前是一样多甚至更多的),只不过建连失败、请求超时等问题都不会体现在tomcat的日志中罢了