原文链接:http://www.one2know.cn/nlp9/
- 多个维度判别文本之间相似度
- 情感维度 Sentiment/Emotion
- 感官维度 Sense
- 特定词的出现
- 词频 TF
逆文本频率 IDF
构建N个M维向量,N是文档总数,M是所有文档的去重词汇量 - 余弦相似度:
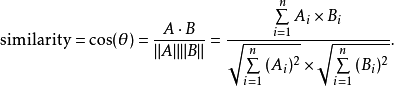
A,B分别是两个词的向量
import nltk
import math
from sklearn.feature_extraction.text import TfidfVectorizer
from sklearn.metrics.pairwise import cosine_similarity
class TextSimilarityExample:
def __init__(self):
self.statements = [ # 例句
'ruled india',
'Chalukyas ruled Badami',
'So many kingdoms ruled India',
'Lalbagh is a botanical garden in India',
]
def TF(self,sentence):
words = nltk.word_tokenize(sentence.lower()) # 分词,都化成小写
freq = nltk.FreqDist(words) # 计算词频分布,词和词频组成的字典
dictionary = {}
for key in freq.keys():
norm = freq[key] / float(len(words)) # 把词频正则化
dictionary[key] = norm
return dictionary # 返回 词:词频
def IDF(self):
def idf(TotalNumberOfDocuments,NumberOfDocumentsWithThisWord):
return 1.0 + math.log(TotalNumberOfDocuments/NumberOfDocumentsWithThisWord)
# idf = 1 + log(总文件数/含该词的文件数)
numDocuments = len(self.statements) # 总文档数
uniqueWords = {} # 不重复的 字典
idfValues = {} # 词:IDF 字典
for sentence in self.statements: # 得到每个句子的 词:含该词文章数量 字典
for word in nltk.word_tokenize(sentence.lower()):
if word not in uniqueWords:
uniqueWords[word] = 1
else:
uniqueWords[word] += 1
for word in uniqueWords: # 词:含该词文章数量 字典 => 词:IDF 字典
idfValues[word] = idf(numDocuments,uniqueWords[word])
return idfValues
def TF_IDF(self,query): # 返回每句话的向量
words = nltk.word_tokenize(query.lower())
idf = self.IDF() # IDF 由所有文档求出
vectors = {}
for sentence in self.statements: # 遍历所有句子
tf = self.TF(sentence) # TF 由单个句子得出
for word in words:
tfv = tf[word] if word in tf else 0.0
idfv = idf[word] if word in idf else 0.0
mul = tfv * idfv
if word not in vectors:
vectors[word] = []
vectors[word].append(mul) # 字典里添加元素7
return vectors
def displayVectors(self,vectors): # 显示向量内容
print(self.statements)
for word in vectors:
print("{} -> {}".format(word,vectors[word]))
def cosineSimilarity(self):
vec = TfidfVectorizer() # 创建新的向量对象
matrix = vec.fit_transform(self.statements) # 计算所有文本的TF-IDF值矩阵
for j in range(1,5):
i = j - 1
print(" similarity of document {} with others".format(j))
similarity = cosine_similarity(matrix[i:j],matrix) # scikit库的余弦相似度函数
print(similarity)
def demo(self):
inputQuery = self.statements[0] # 第一个句子作为输入查询
vectors = self.TF_IDF(inputQuery) # 建立第一句的向量
self.displayVectors(vectors) # 屏幕上显示所有句子的TF×IDF向量
self.cosineSimilarity() # 计算输入句子与所有句子的余弦相似度
if __name__ == "__main__":
similarity = TextSimilarityExample()
similarity.demo()
输出:
['ruled india', 'Chalukyas ruled Badami', 'So many kingdoms ruled India', 'Lalbagh is a botanical garden in India']
ruled -> [0.6438410362258904, 0.42922735748392693, 0.2575364144903562, 0.0]
india -> [0.6438410362258904, 0.0, 0.2575364144903562, 0.18395458177882582]
similarity of document 1 with others
[[1. 0.29088811 0.46216171 0.19409143]]
similarity of document 2 with others
[[0.29088811 1. 0.13443735 0. ]]
similarity of document 3 with others
[[0.46216171 0.13443735 1. 0.08970163]]
similarity of document 4 with others
[[0.19409143 0. 0.08970163 1. ]]